Data is considered the oil of the 21st century. It is considered so because of the immense value that data presents to organizations across the globe. Due to data, companies today can make informed decisions, stay competitive, innovate, and better understand the future.
However, companies cannot enjoy all of these advantages of data until it is methodologically dealt with. This is where the concept of data mining comes into play.
The global data mining tools is expected to reach a staggering $2400 million by 2030.
In this article, you will learn about data mining in detail, i.e., what data mining is, its process, types, various data mining functionalities, uses, advantages, disadvantages, and more. Let’s start by understanding what “data mining” means.
For more detailed insight: Data Science Bible Report 2023
What is Data Mining?
Every organization today emphasizes data mining. If you are working in the field of data science, then you, in one way or another, get involved in some aspect of data mining. Let’s start understanding data mining by exploring its history and then focusing on the generally agreed-upon definition of it.
History
During the 1980s and early 1990s, analytical technologies like data warehousing and business intelligence emerged, facilitating the collection and analysis of the growing volume of data. The term “data mining” was coined in 1995 at the “First International Conference in Knowledge Discovery and Data Mining” in Montreal to respond to the increasing need for a systematic approach to handling data.
Subsequently, the term gained wider recognition with the inaugural issue of “Data Mining and Knowledge Discovery” in 1997, featuring peer-reviewed techniques, practices, and theories on knowledge discovery.
Now, that you have gained some background about data mining, let’s understand what it means.
Definition
Data Mining refers to analyzing large amounts of data to identify relationships and patterns so that different business problems can be solved. Its tasks are often designed semi- or fully automatic to work on large and complex datasets.
The data mining process encompasses several tools and techniques to allow enterprises to describe data and predict future trends, helping to increase situational awareness and informed decision-making. It is considered an integral part of data analytics and a core discipline of data science.
It is considered a key step in the KDD process (KDD is an abbreviation of knowledge discovery in databases, a data science methodology for gathering, processing, and analyzing data).
Prerequisites
The nature of data mining can also be understood through what one needs to know to implement it properly. Arithmetics, statistics, business principles, programming, and reporting are key areas you need to excel in to perform data mining properly.
To be more precise, you need to have a decent knowledge of linear algebra, statistical computing, machine learning, data structures, data manipulation, databases, problem-solving, visualization, etc.
A great way to expand your understanding is by understanding the typical process one follows when performing data mining, but before that –
Course Alert 👨🏻💻
The more organized way you’ll use to mine data, the more informed decisions you will make. Therefore, AnalytixLabs is here to help you master the concepts of Data Mining with its industry-special courses.
Explore our signature data science courses and join us for experiential learning that will transform your career.
We have elaborate courses on AI, ML engineering, and business analytics. Engage in a learning module that fits your needs – classroom, online, and blended eLearning.
Check out our upcoming batches or book a free demo with us. Also, check out our exclusive enrollment offers
Data Mining Process
As per the Cross Industry Standard Process for Data Mining (CRISP-DM), the process has six sequential steps or phases.
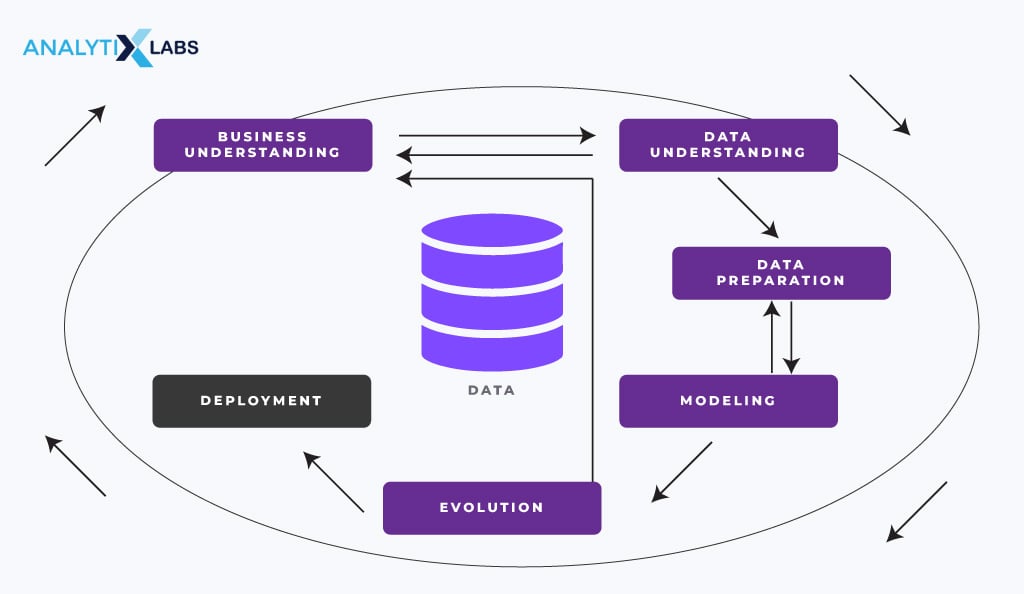
-
Understand Business Problems
The first step in the data mining process is to understand the business objective and the problem it faces. Several questions must be asked before extracting, cleaning, or analyzing data. These include
- What goals does the company intend to achieve by mining data?
- What is the current situation of the business?
- What findings have come out of the SWOT analysis?
- What is the definition of success upon completing the data mining exercise?
All these questions help define the scope and expectations of the organization’s data mining project.
-
Gather Data
The next step is to gather the required data once the business objective and problems are clearly defined. At this phase, several questions need to be answered, such as.
- What sources of data are available to the organization?
- How can the available data sources be accessed?
- What is relevant data? How can this data solve the business problem?
- Is the data collection method secure, ethical, and legal?
- In what format is the data available?
- Where and how will the extracted data be stored?
Therefore, first, you need to determine the limits of the data in terms of access, storage, and security and assess how these constraints can affect the data mining. The relevant data is typically available in warehouses, data lakes, and source systems.
It can often be mixed data, with some data being structured and others being semi-structured or unstructured. Often, external data sources need to be considered, which makes the data-gathering process more complicated.
-
Data Preparation
After the required data is located, extracted, stored, and accessible, the process of making it ready starts. In this phase, various tasks are executed, such as exploratory data analysis (EDA), data profiling, and data pre-processing, encompassing activities like data cleaning, transformation, and manipulation.
Issues identified during the initial phase are addressed to optimize data quality, consistency, and integrity. The ultimate objective of this step is to ensure that the data aligns with the tools and techniques intended for use in data mining.
Typically, the data generated in this step is anticipated to be clean (free of errors, missing values, outliers, redundant information, etc.) and structured (presented in a tabular format or possessing some form of structure).
-
Mine Data
The core step in data mining is, unsurprisingly, the mining of data. In this step, the data scientist or other professionals evaluate the prepared data and the business requirements and identify the appropriate data mining tools and techniques.
The aim of this step can range from identifying sequential patterns, association rules, or correlation in the data to going as far as predicting the future.
For example, a data scientist might decide to perform machine learning to predict future events and may evaluate and use several algorithms to mine the data effectively. To properly execute this step, you need to have a good knowledge of the several data mining types and functionalities (that are discussed in the next few sections).
Also read: Top 11 Powerful Data Mining Techniques To Learn in 2024
-
Analyze Results
The objective of data mining is to come up with actionable insights. To have those, the mined data need to be analyzed and interpreted. The data scientists, therefore, need to aggregate, interpret, extrapolate, visualize, and report the findings from the above step to the decision-makers.
Also, the findings need to be validated by using some benchmarks to ensure that the picture being showcased by the mined data is not incorrect.
-
Implement Findings
If decision-makers, such as business executives or leaders, deem the data provided by the data scientist and others as valid, useful, novel, and comprehensible, they must then determine the appropriate course of action.
The company may view the information as insufficiently robust, relevant, or actionable for decision-making. However, if the findings are compelling, the company may undergo a strategic shift, implementing significant changes.
Regardless of the scenario, the leadership evaluates the decision’s impacts, identifies information gaps, and makes decisions to enhance the organization. The third step in the data mining process, where data is mined, is pivotal among the six steps.
A deeper understanding of data mining, including its types, functionalities, and tools, is essential to execute this step effectively. Subsequent sections delve into these aspects, starting with exploring the various types of data mining.
Types of Data Mining
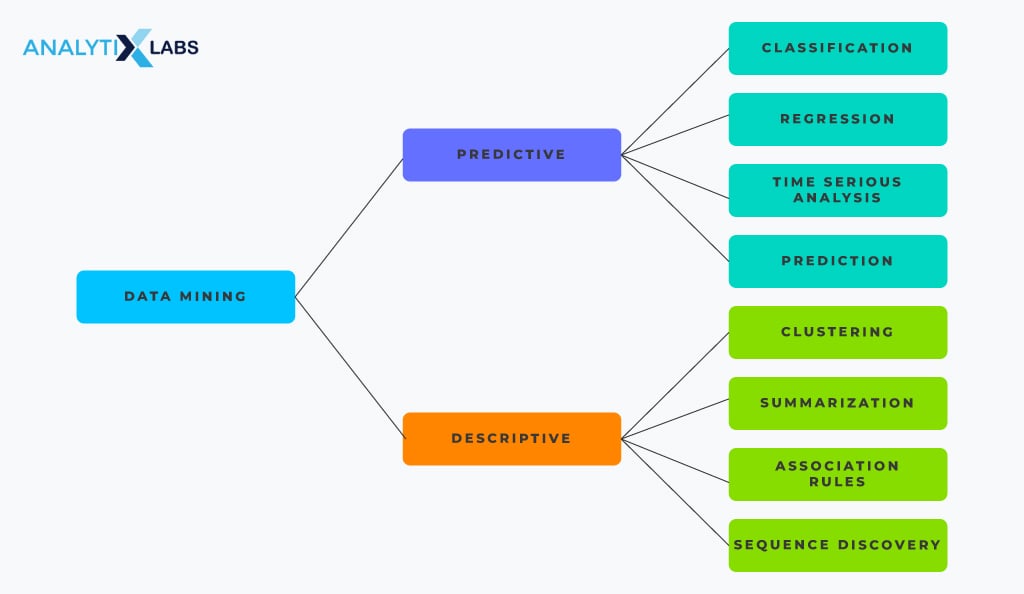
There are several data mining functions or activities that one performs. All these activities can be divided into two categories – descriptive and predictive data mining. Descriptive data mining includes association rule mining, clustering, visualization, sequence, and path analysis.
In contrast, predictive data mining includes activities like classification, regression, and using decision trees and neural networks.
Descriptive Data Mining
In descriptive data mining, the focus is on finding relationships and patterns in the data that can provide information regarding its underlying structure. In this category of data mining, the data is to be summarized and explored so that the following questions can be answered.
- What are the most common and important relationships and patterns in the data?
- Are there any groups (aka. clusters) in the data containing data points with common characteristics?
- Are there outliers in the data, and how are they presented?
The answer to all this information allows data scientists to understand what is happening inside the data, identify its features, and make it possible for them to analyze and report it. Therefore, to understand the general properties of the data and bring its relationships to the surface, such a type of data mining is used.
Common tasks performed under descriptive data mining are as follows-
-
Association Rule Mining
Association rule mining is used to identify the relationship between two or more variables (attributes/features) in the data. It is also used to identify co-occurring events. Thus, it discovers relationships between the data points and uncovers the rules that bind them.
One of the most common use cases of association rule mining is in retail, where transaction data is used to find products that are frequently bought together. This task, known as market basket analysis, employs several association rule mining algorithms, such as the Apriori algorithm.
Also read: Apriori Algorithm In Data Mining
-
Clustering
Cluster analysis, or called clustering, is a process of data mining where similar data points are identified and grouped. The idea of clustering is to find homogeneous groups of data points that shed light on certain group characteristics while minimizing intra-group similarity, i.e., different groups should be distinct.
It is commonly used in customer behavior analysis, fraud detection, etc. Several algorithms allow you to perform clustering, such as K-means clustering, DBSCAN, Gaussian mixture models, mean-shift algorithm, hierarchical clustering using AGNES or DIANA, etc.
Also read: What is Clustering in Machine Learning: Types and Methods
-
Visualization
The primary aim of this type of data mining is to describe data. Therefore, the most common task associated with it is visualization. The idea is to use graphs and charts to represent the data visually. This allows users to summarize the data, identify trends and patterns, and describe the key point in an easy-to-understand medium, which is difficult to do just by looking at the raw data.
Common visualization schemes used here are histograms, line charts, boxplots, scatterplots for numerical columns, and bar charts and pie charts for categorical and numerical-categorical columns.
-
Sequence and Path Analysis
Another task commonly performed in data mining is to find a pattern such that a particular set of events (i.e., values or data points) leads to subsequent events. This identification of the sequence of events or the path that events undertake is called sequence and path analysis. Such analysis is commonly used in e-commerce, online games, etc, to understand how consumers navigate on their platforms.
Predictive Data Mining
While descriptive data mining is important to give you insights about what’s happening inside the data, you often also need to understand the future behavior and events using the data.
It is possible to do so because data is historical, and by building predictive models around it, one can get a sense of what can happen in the future. It’s due to predictive data mining that common business questions can be answered, such as
- What is the likelihood that an employee will churn?
- What is the expected revenue of a product ready for launch?
- What is the probability of the loan applicant defaulting?
Therefore, predictive data mining can enable companies to assess the future by taking cues from the past. In predictive data mining, a predictive model is created where some historically labeled data is fed, and an algorithm is used to produce predictions. Common techniques employed in this category of data mining are as follows.
-
Classification
In classification, well-labeled historical data is used to understand how different data points are associated with different classes. Once a classification model understands this relationship, any new data point can be classified easily.
It is commonly used for churn prediction, loan default risk assessment, item categorization, etc. Common algorithms associated with classification are logistic regression, naïve Bayes, support vector machine classifier, etc.
Also read: What is Classification Algorithm in Machine Learning?
-
Regression
Regression is akin to classification, but it differs in that it predicts continuous values instead of classes. Companies often employ this method when predicting variables like product sales or the success of a marketing campaign. A closely related concept is forecasting, where values are predicted by considering the effects of time.
Common forecasting tasks include weather forecasting, predicting stock prices over the short term, web traffic prediction, etc. Algorithms commonly associated with regression and forecasting are linear regression, ARIMA, Holt-Winters, ARIMAX, GARCH, etc.
Other blogs in Regression series:
- Logistic Regression in R
- What is Linear Regression In ML?
- Random Forest Regression
- Learning Logistic Regression – Types, Algorithms, and more – Part 1
- Learning Logistic Regression – Applications using Python – Part 2
-
Decision Tree
A great way of predicting values is through decision trees, which use a tree-like visualization to explain how the model reaches a prediction. This allows users to drill deeper into the data and understand the relationship between the predictors and the predicted value.
The “decisions” taken by the model to reach an outcome greatly increase interpretability and aid in the reporting of the analysis. Classification and regression activities can be performed using decision trees, making it a great data mining technique.
Common decision tree algorithms include CART, ID3, C4.5, etc. An ensemble of these algorithms can also be used, giving birth to algorithms such as random forest, bagging, XGBoost, Adaboost, etc.
Also read: Decision Tree Algorithm in Machine Learning
-
Neural Networks
The most advanced way of performing predictive data mining is by using neural networks, a class of algorithms that simulate how the human brain works. Neural networks use input, weights, and output to form a node that acts as a human brain cell – neuron.
Several such neurons are then stacked horizontally and vertically to create a neural network, creating an artificial human brain, giving rise to artificial intelligence. While they can mine data, such networks give little insight into how the predictions are produced. Neural networks can perform regression and classification activities using algorithms like ANN, RNN, CNN, LSTM, GRU, etc.
Now, after discussing the types, we will focus on the numerous data mining functionalities that it is associated with in the next section. This will help you answer questions like the functions of data mining or what activities you can perform under it.
Also read:
Data Mining Functionalities
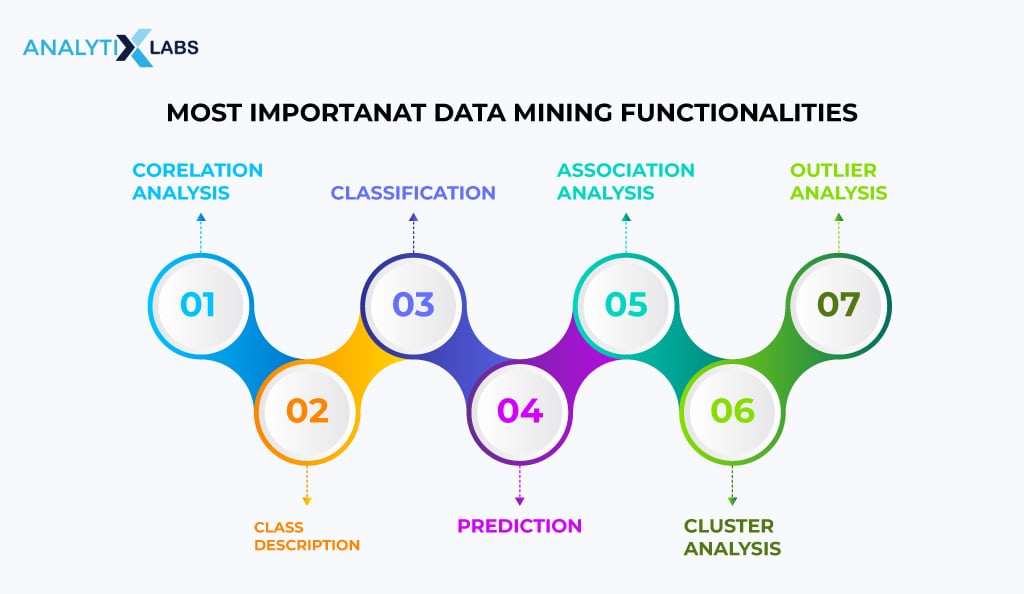
Several data mining functions are expected from you to be performed. These functionalities arise from the various data mining types and associated tasks discussed above. A few of the most common functionalities of data mining are as follows.
Class/Concept Description: Characterization and Discrimination
It is possible to correlate definitions or classes with results. It can define concepts and individual groups in descriptive, simplified, yet accurate ways. These concept or class definitions are what class/concept descriptions mean.
Data Characterization
Data characterization refers to actively summarizing the general features or characteristics of the class under study. Presenting the output can take various forms, including bar charts, pie charts, multidimensional data cubes, etc.
For example, an electronic store analyzes the customers who purchase products worth ₹50,000 or above and ends up describing the characteristics as follows-
- Age between 30 to 40
- CIBIL score between 650 to 750
- Employed
Data Discrimination
In data discrimination, common features of the class in question are identified and compared. Thus, this method compares the target class’s general features against the general features of objects from one or multiple contrasting classes.
For example, comparing two groups of customers with one group shopping for mobile regularly while the other shopping for it rarely, i.e., less than once every three years. When the data is analyzed, it provides a comparative profile of these customers.
| Frequent Customer Group | Rare Customer Group |
|---|---|
| Age of 80% in this group is between 20 to 40 years | Age of 70% in this group is either below 20 or above 40 |
| 75% of this group is graduate | 80% of this group has no college degree |
Frequent Pattern, Correlations, Association and Clustering Analysis
The next functionality of data mining is to find patterns and relationships in the data by assessing how different data points are connected. It’s often the primary answer to the question – what are the functions of data mining?
This can be done in multiple ways, such as
-
Frequent Pattern Analysis
Finding frequent patterns in data means finding the most common data points. Different kinds of frequencies can be observed in data, such as
- Frequent Item sets
Here, the items often appearing together are counted, e.g., customers buying bread and butter together.
- Frequent Subsequence
This is where pattern series that occur often are counted, e.g., purchasing a phone followed by a screen protector.
- Frequent Substructure
This method combines different kinds of data structures (like trees and graphs) with the subsequence, i.e., itemsets.
-
Association Analysis
In association analysis, we identify rules that actively dictate the relationships between the data. For instance, conducting market basket analysis on a supermarket’s transaction data helps identify frequently bought items, leading to improved inventory management, optimized product placement, and effective group discounts.
Also read: Factor Analysis Vs. PCA
-
Correlation Analysis
In mathematics, correlation is a technique where the strength of the relationship between two pairs of attributes is determined. Common techniques include Pearson’s correlation coefficient, Spearman’s rank correlation coefficient, etc.
An example of this could be assessing the strength of the relationship between years of education and income.
-
Cluster Analysis
As previously mentioned, data is grouped into distinct clusters to identify their characteristics in clustering.
For instance, a telecom company conducts cluster analysis on customer 360 data, which includes demographics, usage, and transaction information. The goal is to identify various customer types, enabling the company to retain high-paying customers and encourage those at risk of churn to continue using the service.
Classification
Classification is a major data mining functionality that uses data models to classify new data into pre-existing classes.
For example, a bank fixes the risk level of a loan applicant based on their previous loan repayment history.
Also read: What is Classification Algorithm in Machine Learning?
Prediction
Prediction is the major functionality of data mining. It encompasses the classification functionality mentioned above but can also be regarded as a stand-alone feature. This functionality analyzes data and comprehends the relationship between data points and their respective classes.
In predictions, however, the core focus is statistical and machine learning techniques to predict any new data point. Here, all types of problems are solved, such as regression, forecasting, and classification.
For example, a bank predicts the amount of cash required in an ATM on various days.
Outlier Analysis
Outlier refers to data points that cannot be grouped given a cluster or class. They can, therefore, be treated as anomalies or exceptions.
For example, using outlier analysis to identify fraudulent credit card transactions to alert the user.
Evolution and Deviation Analysis
Lastly, evolution and deviation analysis is another functionality of data mining. In evolution analysis, models are created to analyze the evolving trends in data. Here, time-related data is characterized, compared, classified, and clustered. Deviation analysis, however, analyzes the measured and expected values and tries to find the cause of deviations among them.
For example, performing deviation analysis on weather forecasts having deviation between the forecasted and actual measured temperature.
After data mining functionalities, the next key aspect you should be aware of is the tools related to data mining.
Data Mining Tools
There are several tools out there that can be used for performing data mining. As it is a wide field encompassing several activities, from descriptive to predictive data mining, one often needs to know more than one tool. Still, knowing any one of the below-mentioned tools can greatly increase your capability to mine data effectively.
Python
Python is an open-source, general-purpose programming language. It is considered a great tool for data mining because of the thousands of Python packages that provide users with pre-existing code for automating various data mining tasks. The most crucial libraries include Pandas and NumPy, allowing users to perform most data preparation tasks.
In addition, libraries like scikit-learn, statsmodels, and TensorFlow can allow users to mine data by creating statistical, machine learning, and deep learning models. Matplotlib, seaborn, and similar libraries can be used for visualization and reporting.
Also read: What are the best Python Libraries for Machine Learning to learn in 2024?
R
Another open-source language commonly used for mining is R. Although it is partially designed with data science-related activities in mind and is relatively more complex than Python, R allows the effective performance of data mining. R programmers can utilize several thousand libraries available on CRAN for most data mining activities.
For example, while libraries like dplyr and reshape2 enable data preparation, libraries like Caret and H20.ai enable model building for solving regression and classification problems. A great advantage of R is visualization, where popular packages like ggplot2 and plotly can be used.
Also read: Benefits of Learning R Programming Language
SAS Enterprise Miner
SAS Enterprise Miner is a commercial platform businesses use because it is easy, scalable, and provides great reporting and summarization functionalities. It, however, is not ideal for performing complex tasks using machine learning or deep learning. Still, it’s better than its open-source competitors because of secure cloud integration and code scoring (ensuring the code is clean and free of expensive errors).
RapidMiner
Another crucial tool in the field of data mining is RapidMiner. It is a proprietary data mining tool that makes data preparation, predictive modeling, clustering, etc, easier than general-purpose languages like Python. Given its focus on data mining, complicated tasks can be easily completed with its drag-and-drop interface that eliminates the need for users to have extensive technical skills.
Orange
If you are familiar with Python and its libraries, like scikit-learn for data mining, Orange is a great open-source tool. Orange provides a visual front end that utilizes Python libraries like scikit-learn and NumPy.
This tool is ideal for newcomers who want to easily use Python libraries for data mining through a graphical user interface. Advanced users can use add-ons to mine data from external sources and deal with large datasets.
There are many other data mining tools that you can explore, such as Rattle GUI, KNIME, Excel, SAP, Tibco, SPSS, SPARK, and cloud platforms like AWS, Azure, and GCP. Given that data mining is crucial for businesses, we will now explore the various functionalities with examples.
Uses of Data Mining
In this section, we will first discuss the domains where data mining is actively used and then take examples of a few companies that actively employ data mining.
Domain Uses
It is used in several domains for various reasons, such as
- Retail: mining customer data, helping them design promotional offers, marketing campaigns, ads, market basket analysis, product recommendations, and supply chain management activities.
- Financial Services: mining financial records for creating risk models, detecting fraud transactions, vetting loan applications, etc.
- Insurance: mining customer demographic and historical data for policy approval, pricing, risk modeling, identifying prospective customers, cross-selling, etc.
- Entertainment: mining customer data with likes and dislikes and time spent on different content to recommend new content.
- Healthcare: mining patients’ records, reports, etc, to recommend the diagnosis, analyze X-rays, etc.
- Fraud Detection: mining historical transactions to identify anomalies in data points and alerting bank/credit card holders.
- Human Resource: mining employee data such as resumes, internal polls, surveys, and reviews to work on employee retention, promotions, pay raises, etc.
Other common data mining domains are manufacturing, education, sales, marketing, customer relationship management, operational optimization, etc. Let’s further understand the data mining functionalities with examples of specific companies.
Company Uses
Numerous companies use data mining to make their operation effective. A few important ones are-
- Air France KLM performs data mining to create a customer 360-degree view by integrating data from booking, trip searches, and flight operations with a call center, web, social media, and airport lounge interactions, allowing for personalized travel experiences.
- Dominos collected 85,000 unstructured and structured data from supply chain centers and point of sales systems to numerous channels such as social media, text messages, Amazon Echo, etc., resulting in improved business performance and one-to-one buying experience across touchpoints.
- E-bay collects information from buyers and sellers to mine data and find relationships between products, form product categories, asses desired price ranges, etc.
- Facebook-Cambridge Analytica is a controversial example of data mining where Cambridge Analytica Ltd. – a British consulting firm, deceivingly collected personal data from millions of Facebook users to analyze their voting behavior.
If you have found data mining interesting and wish to perform it, you must know its pros and cons. Let’s discuss this aspect of data mining, too.
Advantages and Disadvantages of Data Mining
To responsibly use data mining, you must know its advantages and disadvantages.
Advantages
Common advantages of data mining are-
- Improved Customer Service because of timely identification of customer issues and providing them with up-to-date information.
- Improved Supply Chain and better inventory management by spotting market trends and forecasting product demand accurately.
- Increased Production Uptime by mining operation data from manufacturing machines, sensors, and other industrial equipment, allowing companies to avoid unscheduled downtime.
- Better Risk Management is possible as by mining data; executives can better asses the legal, financial, cyber, and other risks.
- Reduction in Cost as data mining can bring operational inefficiencies to the surface and reduce redundancy and waste in corporate spending.
- Cost Efficient as it is less expensive than other statistical data applications.
- Automated Pattern Discovery is possible along with predicting behaviors and trends due to the availability of sophisticated data mining tools.
Disadvantages
Common disadvantages of data mining are-
- Difficult Tools create issues as data mining tools are sophisticated and often require a level of technical knowledge on behalf of the user to employ these tools effectively.
- Numerous Algorithms are used in data mining that differ in their design, making selecting the right algorithm a difficult task.
- Maintaining Data Quality is an issue as the data being mined is often full of errors, duplicates, inconsistencies, and omissions that, if not prepared properly, can provide misleading analytical results.
- Data Complexity is a huge issue for data mining as, given the vast data sources from sensors and IoT to social media and financial transactions, collating them in a single dataset for mining becomes difficult.
- Data Security and Privacy issues are of grave concern when performing data mining because as the places where the data is collected, stored, and analyzed expand, so does the chance of data breaches and cyber-attacks. Data mining is becoming challenging as data can contain personal, confidential, and sensitive information that requires protection, and there are multiple regulations to abide by, such as CCPA, HIPAA, GDPR, etc.
- Scalability is another issue with data mining because the data size is growing rapidly, making the resources required to perform data mining more costly and time-consuming.
- Interpretability is a major challenge with data mining because it often employs sophisticated and complex models that are difficult to interpret, making it difficult to address challenges like model bias.
Before concluding our discussion on data mining, let’s also explore its future trends.
Future of Data Mining
Data mining is a crucial activity, and its future seems bright. However, the expectations from professionals involved in it are evolving rapidly. The rapid increase in data size expects data mining professionals to possess knowledge about databases, big data computing, and information analysis.
Additionally, companies are increasingly employing machine learning, artificial intelligence, and cloud-based data lakes to automate data mining on big data. Cloud-based solutions are increasingly making data mining easier and more cost-effective for smaller and bigger companies. Therefore, in the future, these technologies will play a crucial role in this field.
Conclusion
Modern businesses gather data about their products, customers, employees, manufacturing lines, storefronts, marketing activities, etc. While seemingly random, all this information can tell a whole story about where the business is and where it is heading if analyzed properly. To do so, companies today rely heavily on data mining tools, techniques, and applications.
Today, a data science professional must be proficient with data mining. It allows companies to compile data, analyze the result, and develop actionable insights so that leadership can execute operational strategies.
FAQs:
- What are the six data mining capabilities?
The key six data mining capabilities, also referred to as data mining functionalities, are
- Class/concept description
- Frequent pattern, correlation, association, and clustering analysis
- Classification
- Prediction
- Outlier analysis
- Evolution and deviation analysis
- What is a data mining function in a data warehouse?
It plays a crucial function in data warehousing. Data warehouses store, manage, and organize large amounts of data, enabling businesses to analyze and uncover hidden patterns, relationships, and insights for making informed decisions.
We hope this article helped you understand the concept behind data mining. If you wish to know more about data mining and want to learn the tools associated with it, then get in touch with us.
Related Reading Resources