Data Scientists need resources to resolve specific business problems. Classification algorithms in Machine Learning help categorize data into distinct classes. These algorithms allow machines to identify the characteristics of an input and then assign them to pre-defined categories. Businesses can use such classification tasks to predict whether a customer is likely to purchase a product, determine if an image contains a particular type of object, and identify the language of a text.
This article specifically aims to resolve questions like classification in machine learning. It will also address the various aspects of the most common business problems. You will also better understand various aspects of machine learning classification.
A Brief About Classification in Machine Learning
Classification in machine learning is used to categorize data into distinct classes. It is one of the most common and important tasks in machine learning, as it helps us predict the outcome of a given problem based on input features.
In simple words, classification machine learning algorithms allow us to assign a label or category to a piece of data.
These labels are known as Classes.
It can be done by analyzing the properties of each instance (or object) fed into the system for classification.
The entire process involves supervised learning, i.e., where the objects with known properties (or labels) are used to train a model for future predictions. Once trained, this model can then be used to classify new instances.
| BUSINESS PROBLEM | DESCRIPTION |
|---|---|
| Regression Problem | When there is a requirement to predict numeric values in nature (real, continuous, discreet, etc.), there is a need to quantify the impact of numerous variables on a numerical entity (also known as the dependent or Y variable). |
| Classification Problem | This business problem is somewhat similar to regression problems. Here, there is a requirement to quantify the impact of variables (known as independent or X variables) on a dependent variable. However, they are different here, and the Y variable is categorical. Thus, a model will be developed based on the X variables and predicts observations into predefined classes. |
| Forecasting Problem | When values are required to be predicted over a time and the time acts as a predictor |
| Segmentation Problem | There are situations where a bulk of data needs to be categorized. However, no pre-existing classes can be used to supervise the model. Here the underlying patterns are to be detected and divided the observation into different categories. These categories are then defined by understanding the characteristics of the observations found in each particular class. |
Classification in machine learning is a supervised ML technique. It predicts group relationships for data instances in the dataset. It is a recursive process of recognizing, understanding and grouping the data objects using labels into pre-defined categories.
In simpler words, it identifies an appropriate set or class where every new observation belongs. The output variable can belong to more than one class or category. For example, when Google Photos classifies your photo containing people, waterfall, and geo-tagging. The same image is displayed in all three mentioned categories due to the metrics available.
Also Read: How Confusion Matrix in Machine Learning Helps Solve Classification Issues
Earlier, we understood what classification is in terms of machine learning. Let’s also understand what Classification is and the types, fundamentals, and properties.
Classification in Machine Learning aims to determine which category an observation belongs to, and this is done by understanding the relationship between the dependent and independent variables.
Here the dependent variable is categorical, while the independent variables can be numerical or categorical.
As a dependent variable allows us to establish the relationship between the input variables and the categories, classification is predictive modeling that works under a supervised learning setup.
Learn from AnalytixLabs
If you are new to the Machine Learning field and want to learn from a premium institution, you can check our online learning module for machine learning or book a demo with us.
Classification in Machine Learning: Terminologies
- Classifier: An algorithm that maps the input variable into a specific class.
- Feature: A metric or a measurable property of the scenario selected.
- Initialize: Assigning the classifier used.
- Classification Model: A model that categorizes the input data into two or more discrete groups.
- Evaluate: Evaluation of the model by finding the accuracy score and classification report.
Two-step procedure for classification:
- Learning Step (Training Phase): The initial step is the construction of the Classification Model. It is done by choosing algorithms to build a classifier by enabling the learning of the model using the training set available. Accurate results are obtained when the model is trained perfectly.
- Classification Step: The model predicts the class labels (sub-population) and observes the constructed model on test data. It estimates the precision of the classification rules. The resulting classifier is later utilized to allocate the class labels to the testing data instances where the values of the predictor features are known. Still, the value of the class label is unknown.
Why is Classification Used in Machine Learning?
Classification algorithms are used in Machine Learning to predict the class label of a given data point. It allows machines to learn and predict new data points, even when no class labels are known.
Classification machine learning is used for both supervised and unsupervised machine learning tasks.
Supervised classification involves assigning class labels to training data points, while unsupervised classification involves grouping data points into clusters without any prior knowledge about the possible class labels.
Also Read: Types of Machine Learning
Typical use cases are the recommendation systems to recommend items based on similarity scores between different class labels and anomaly detection tasks, such as detecting fraud or identifying malicious activities.
By applying classification algorithms to large datasets of labeled instances, machines can learn patterns and make predictions . These algorithms also detect patterns in data that might otherwise be difficult to uncover or identify.
How is Classification Algorithm Implemented?
Classification of Algorithms can be done through one of the following methods:
- Implementation Method
-
- Recursion or Iteration
- Procedural or Declarative (non-Procedural)
- Serial or Parallel or Distributed
- Deterministic or Non-Deterministic
- Exact or Approximate
- Design Method
-
- Greedy Method
- Divide and Conquer
- Dynamic Programming (DP)
- Linear Programming
- Reduction (Transform and Conquer)
- Classifications based on
-
- Research Area
- Complexity
- Randomized Algorithms
Understanding the Classifiers: Types of Classifications
Machine learning classification algorithms vary w.r.t. the relationship between the independent and dependent variables. Let us explore the algorithms used to classify the input examples into class labels.
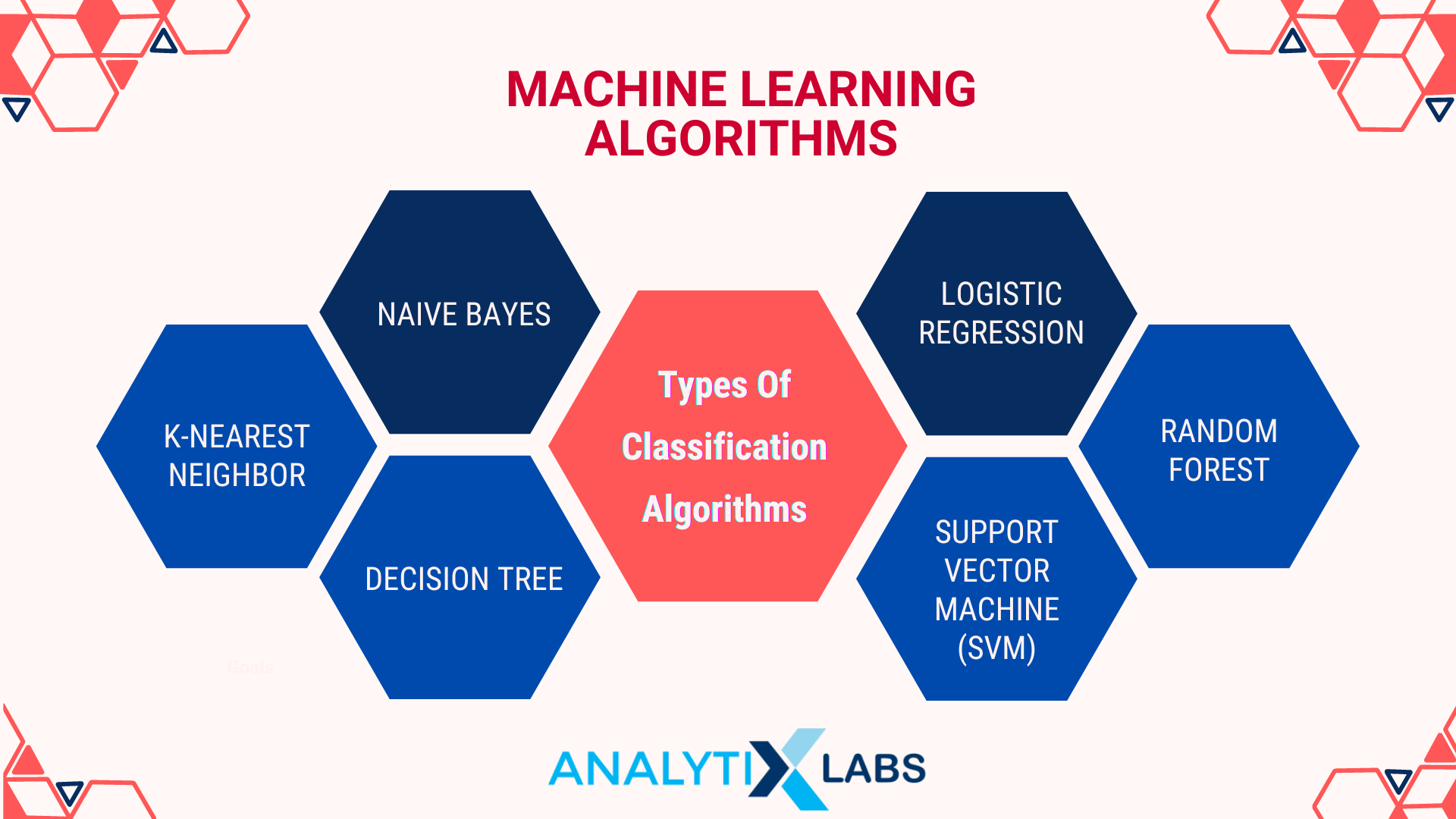
Naive Bayes
Bayes theorem calculates probabilistic classification, which uses prior knowledge and naïve assumption where the input features show strong independence from each other.
For example, taking an apple as an input, the classifier can label it under the category fruit, red color, and round shape, but all these will be attributed independently. It is the most used, fast, and simple machine learning classification algorithm, which works effectively even on small amounts of training data.
Mathematically, the Bayes theorem is stated as:
P(A|B) = P(B|A)* P(A)/ P(B)
where:
- P(A|B) is the probability of event A occurring, given that event B has occurred
- P(B|A) is the probability of event B occurring, given that event A has occurred
- P(A) is the probability of the event A
- P(B) is the probability of the event B
Also Read: How to use Naive Bayes Theory in Machine Learning
Real-life use cases include
- Text classification
- Disease prediction
- Sentiment analysis
- Spam filters
K-Nearest Neighbour
K-Nearest Neighbor classification models machine learning is instance based and works as a lazy learner. A lazy learner means it does not build an internal model. Rather, the data points in this classification are represented in n-dimensional space with n features defined.
The algorithm picks the class that is most common among the k neighbors of the data point. To assign labels to the nearest unobserved data points, the labeled points are used. The majority of the vote from the k nearest neighbors is taken, and whichever label has the vote from most neighbors is assigned to a new point.
The major advantage of KNN classification is its robustness towards noisy data. Despite the high computation cost, it is used in various industries successfully.
Common use cases are
- Video and image recognition
- Stock analysis
- Handwriting detection
Decision Trees
Classification models machine learning algorithm that aims to build a tree structure for visualizing a decision-making model. The classification is based on the equally exhaustive and mutually exclusive “if-then-else” situation. The branches of the model are developed by dividing the dataset into subsets by choosing the most important features in classification.
The tree is built using top-down recursive divide and conquer. As we go down the training set is eventually associated with an incremental decision tree. The final classification structure looks like a tree with nodes and leaves.
Singular units of the training data are used sequentially to learn and form rules. Once a rule is learned, the rows covering the rules are eliminated. The same process continues on the training set until the termination point is met.
A decision tree classification is simple to interpret and visualize. With little data preparation, the decision tree works well in complex problems like pattern recognition, data exploration, and identifying medical risks.
Logistic Regression
Logistic regression is a model that generates class-label predictions using a sigmoid function to find the dependency between the output and input variables. It uses multiple independent variables to determine an outcome.
The sigmoid function yields a probability output, which is then compared with a pre-defined threshold to assign the label to the object accordingly. It fits suitably for binary classification algorithms.
The major drawback of logistic regression is that it assumes data to be free from missing values, and the predictors are independent of each other.
Depending upon the nature of the output variable, the logistic regression algorithm can be categorized as Binary, Multinomial, or ordinal logistic regression.
Also Read: Logistic Regression with R
Popular use cases are
- Voting applications
- Churn classification
- Weather classification
Random Forest
Random forest classification is an ensemble learning method that is superlatively a collection of decision trees. Ensemble learning aggregates the results from multiple predictors.
It is a meta-estimator that incorporates the number of trees on different subsamples of training data sets. Later, their average is used to improve the accuracy of predictive modeling.
The classification constructs a multitude of decision trees in the training process, which generates output as a class which is the mode of regression prediction of the individual trees.
Well-known use cases are
- Social media share score prediction
- Performance score analysis
- Anomaly detection
Support Vector Machine (SVM)
Support vector machine represents the training data points in the space, separated by a gap between the two classes. The classifier aims to find a hyperplane in N-dimensional space (N being the number of features) that distinctly classifies the data points to either of the classes.
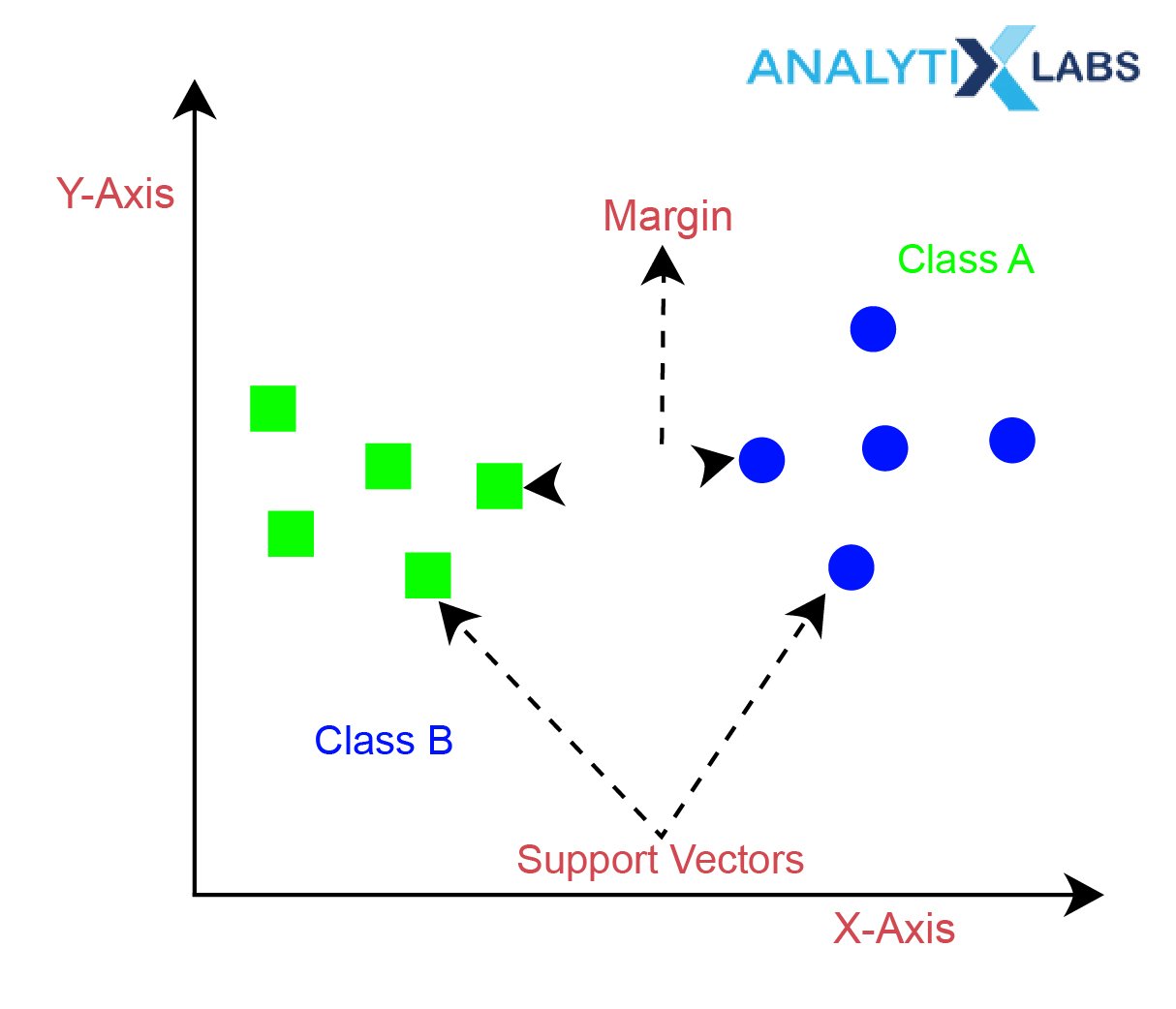
The margin can be defined as the nearest data points of each class to the selected hyperplane.
On the entry of a new point, the prediction is made to identify the data point category. SVM is a non-probabilistic binary classifier.
The regularization parameter used in SVM helps in optimization algorithms by overfitting the data. The classifier is highly efficient in high-dimensional spaces and is memory efficient.
Also Read: Introduction to SVM in Machine Learning
Widely known use cases are
- Finance and stock market suggestions
- Air Quality control systems
Predictive Modeling: Classifications
The classification process involves assigning class labels to input data; this is done by predicting the appropriate class to which a dataset must belong. This process is called predictive modeling. The requisite for the process modeling is the training dataset containing inputs and outputs to learn from.
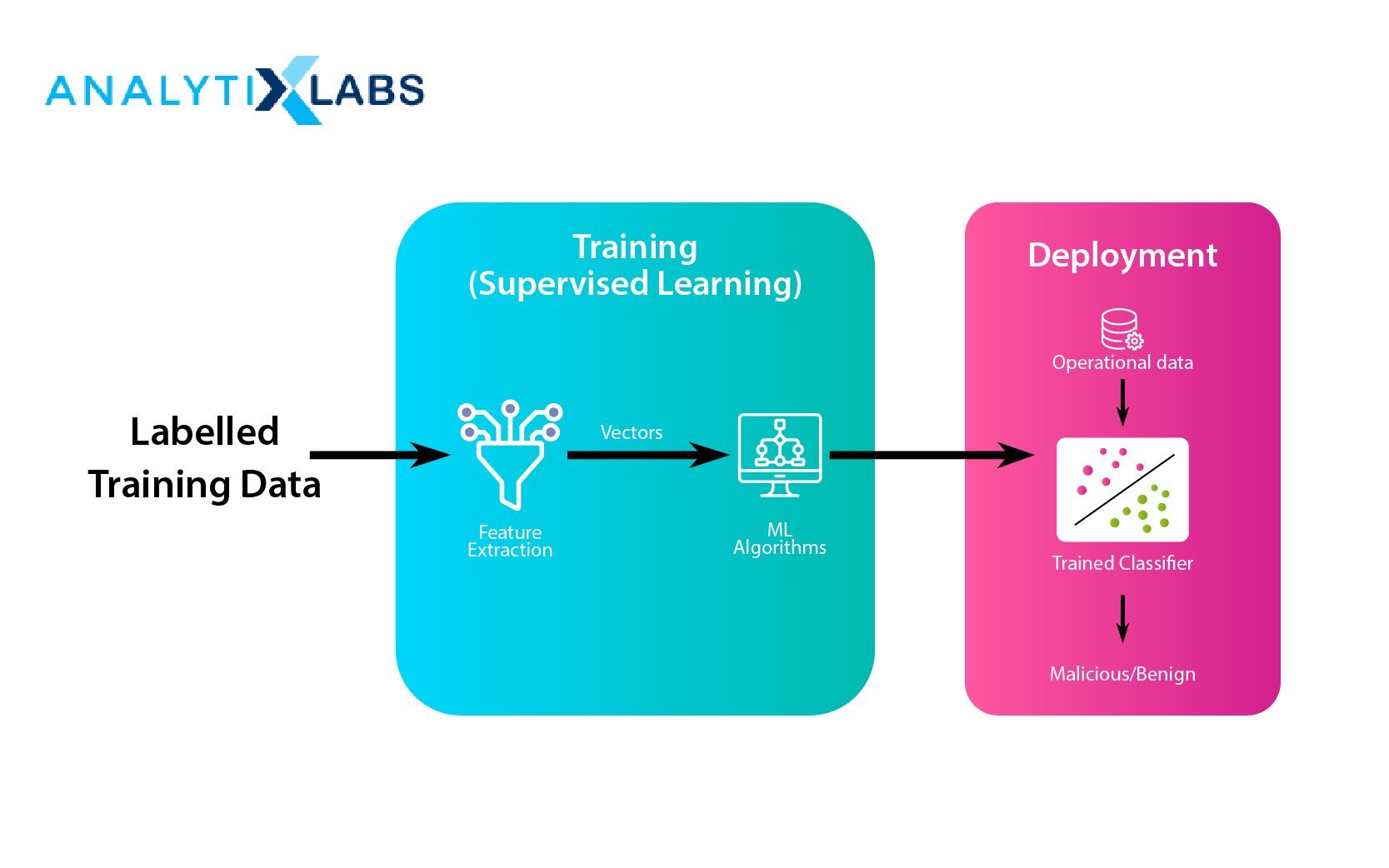
The training dataset is utilized to optimally estimate the mapping of the input data objects to the specific class labels. The class labels are mostly string variables that are mapped to numeric values.
For example, for mail filtering, classes can be labeled as spam = 0 and no spam = 1. The selection of the classification algorithm for modeling classification prediction depends upon the results.
Classification accuracy is the metric used for evaluating predictive modeling performance. To understand the classification relationship between the dependent variable and the independent variables must be observed.
Types of Classifications
The dependent variables discussed in the previous section are categorical, while the independent variables can be categorical or numeric. The type of classification in machine learning depends upon the nature of the dependent variable. Some of the major machine learning classification methods are explained in this section.
Binary & Multi-Class Classification
- Binary Classification:
Binary classification algorithms are the simplest and most crisp classification types. The classification task uses only two class labels. One is considered in a normal state, and the other is considered in an abnormal state. The dependent variable may have a value of 0 or 1. A 0 value represents a False or negative state, while A value of 1 represents a True or positive state. It is used when the classification is a YES or a NO.
The classification returns a discrete value covering all cases with a categorical value of 1 or 0. Consider the case of Cancer cell detection.
Two classes can be ‘No Cancer detected’ and ‘Cancer detected’.
The former is the normal state (value 0), and the latter is the abnormal state (value 1). Undergoing the modeling using the training dataset, the input can be classified into these classes.
Examples of binary classification algorithms include email spam detection and churn prediction.
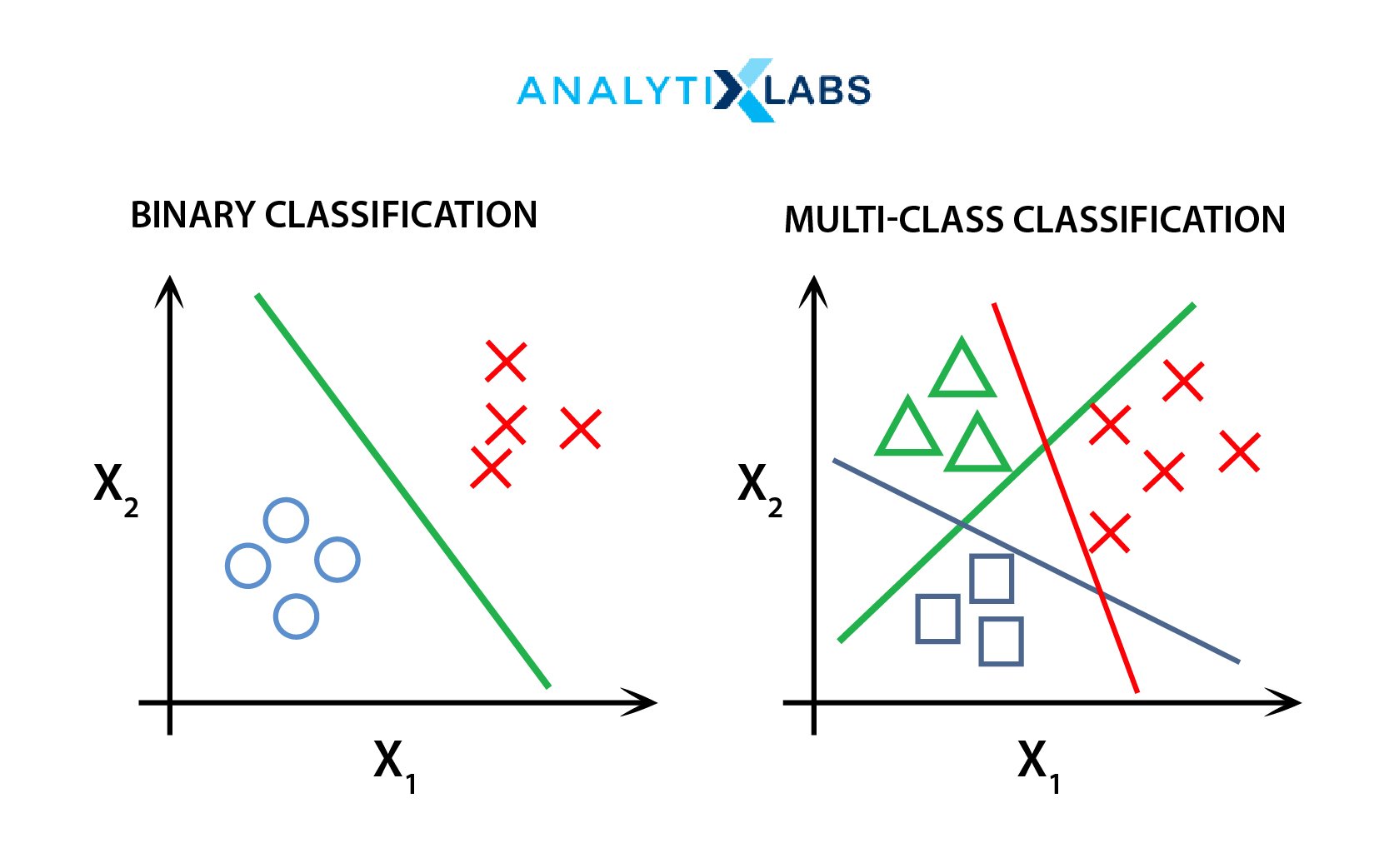
- Multi-class Classification:
Multi-class classification is among the advanced machine learning classification methods having more than two classes. Unlike binary classification, the examples can belong to more than one class based on the categories.
The classification problems do not have fixed labels. Thus they can be used to classify problems that can fall into multiple categories.
Multi-class classification uses categorical distribution where the input event can have multiple endpoints. So, predicting the relationship of the input with the output labels is to be modeled.
The multiclass classifier mode is built using the Random Forests and Naive Bayes classification algorithms. Plant species classification, and face classification, are examples of multiclass classification.
Multi-label Classification
Multi-label classification specifically handles classification tasks where the input can be assigned to two or more class labels, out of which one or more classes may be predicted. The classification in this type has the ability to predict multiple labels.
Photo classification is the best example to understand this classification; a single photo can have multiple objects like a photo taken on a highway can have a face, car, roads, trucks, and even hills in the background. So the single image can be labeled under all the categories.
Imbalanced Classification
This classification technique is where the number of examples in each of the classes is unequally distributed. It can be taken as a binary classification task where the majority of outputs fall in either of the two classes.
In other words, the task may have a weighted normal state or abnormal state. Fraud detection and Outlier analysis are examples of Imbalanced classification.
Classification Examples
Email Classification
Among the most traditional and early uses of classification is email segregation. Emails were often required to be classified as spam or not spam (i.e., being worthy of being in the inbox). It is done by developing a classifier model that goes through the content to identify if the email is spam or not.
To develop such a classification model, a large amount of well-labeled email is required so that in the training phase, enough data is available. As inherently this is a text-based problem, the email content is converted into features where each feature is a word.
The observation for the model is whether a particular word was present / how many times the word was present in a document.
While the traditional email classifiers dealt with binary problems (Spam or Not Spam), modern-day Email classifiers identify if the email is spam and the email’s topic/nature, such as social, advertisement, notifications, etc.
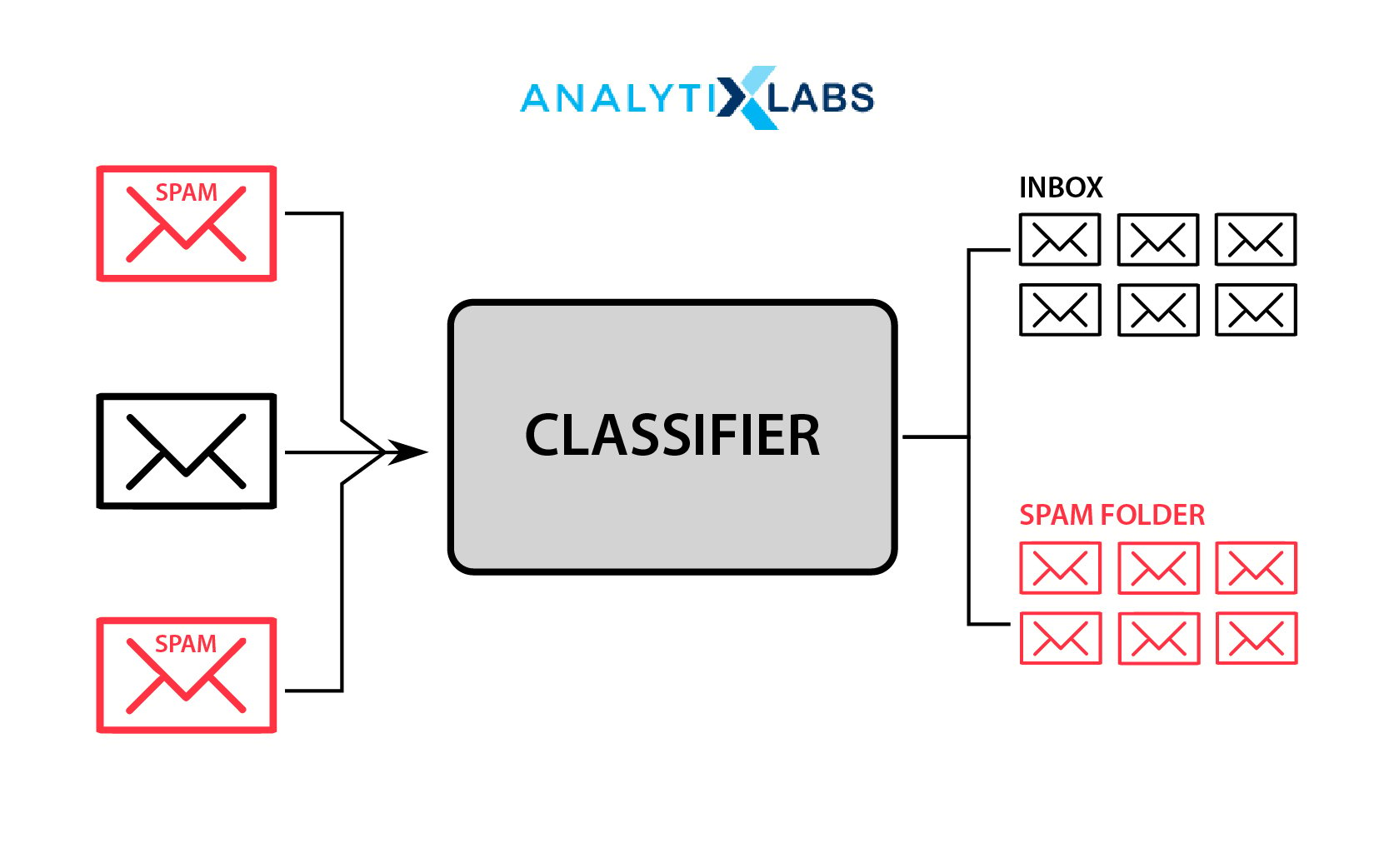
Similar models are increasingly being used in messaging applications. They classify SMS into similar categories offering a better understanding of the user experience. It helps users by preventing the tedious task of deleting unnecessary messages.
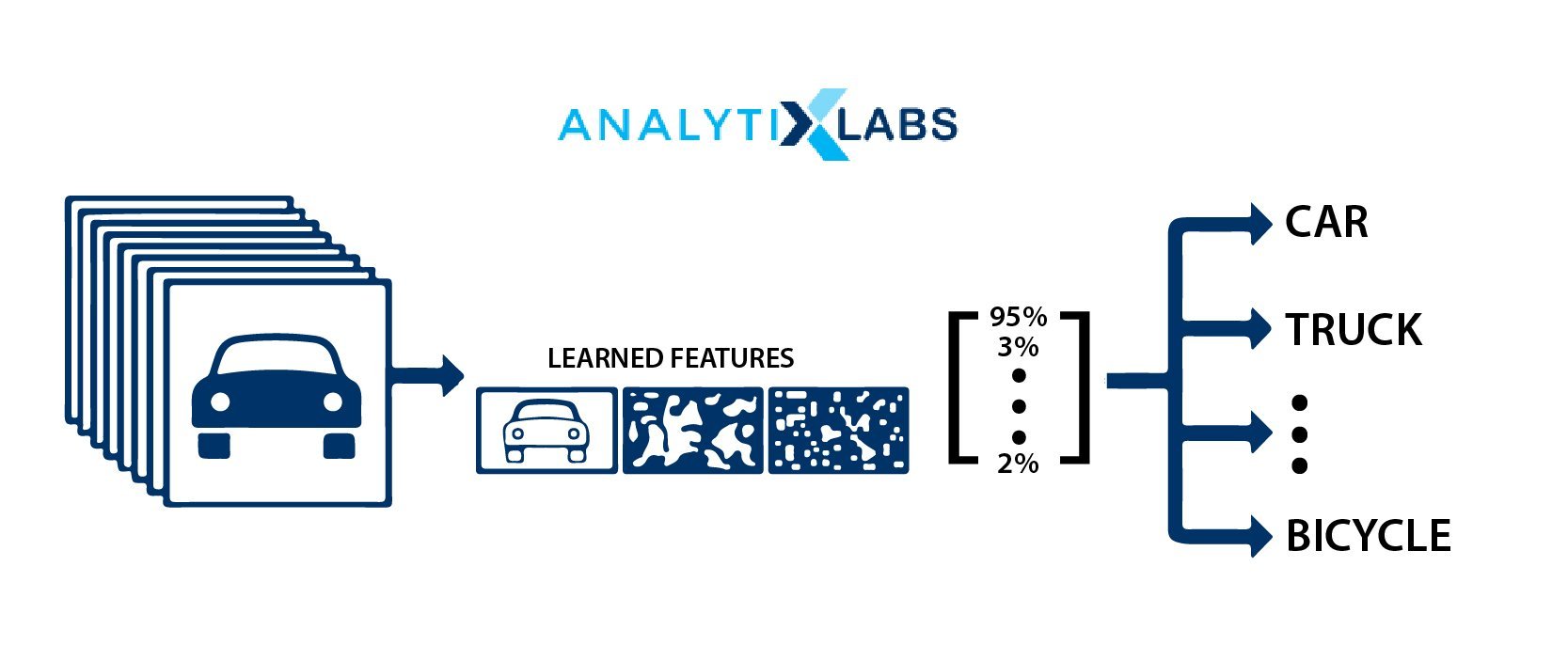
Image Classification
The business problem that has haunted most industries and has been a challenge for researchers for a long time is Image Classification. It is finally possible today with algorithms such as Support Vector Machines and Artificial Neural Networks.
These algorithms have made it possible to classify an image with unprecedented accuracy. In theory, the most basic form of classification can be differentiating cats from dogs or identifying numbers from images. However, the real use case of image classification is rather varied. The common image classification use cases include-
- The automobile industry has extensive use of image classification, especially those trying to create self-driving cars.
- Security Agencies are increasingly using image classification to identify culprits, while home security systems heavily rely on Image classification to raise alarms in case of an intrusion.
- Image classification’s lifesaving application has been in healthcare, where it has enabled the early detection of diseases and has helped develop robots that use computer vision to perform complicated surgeries.
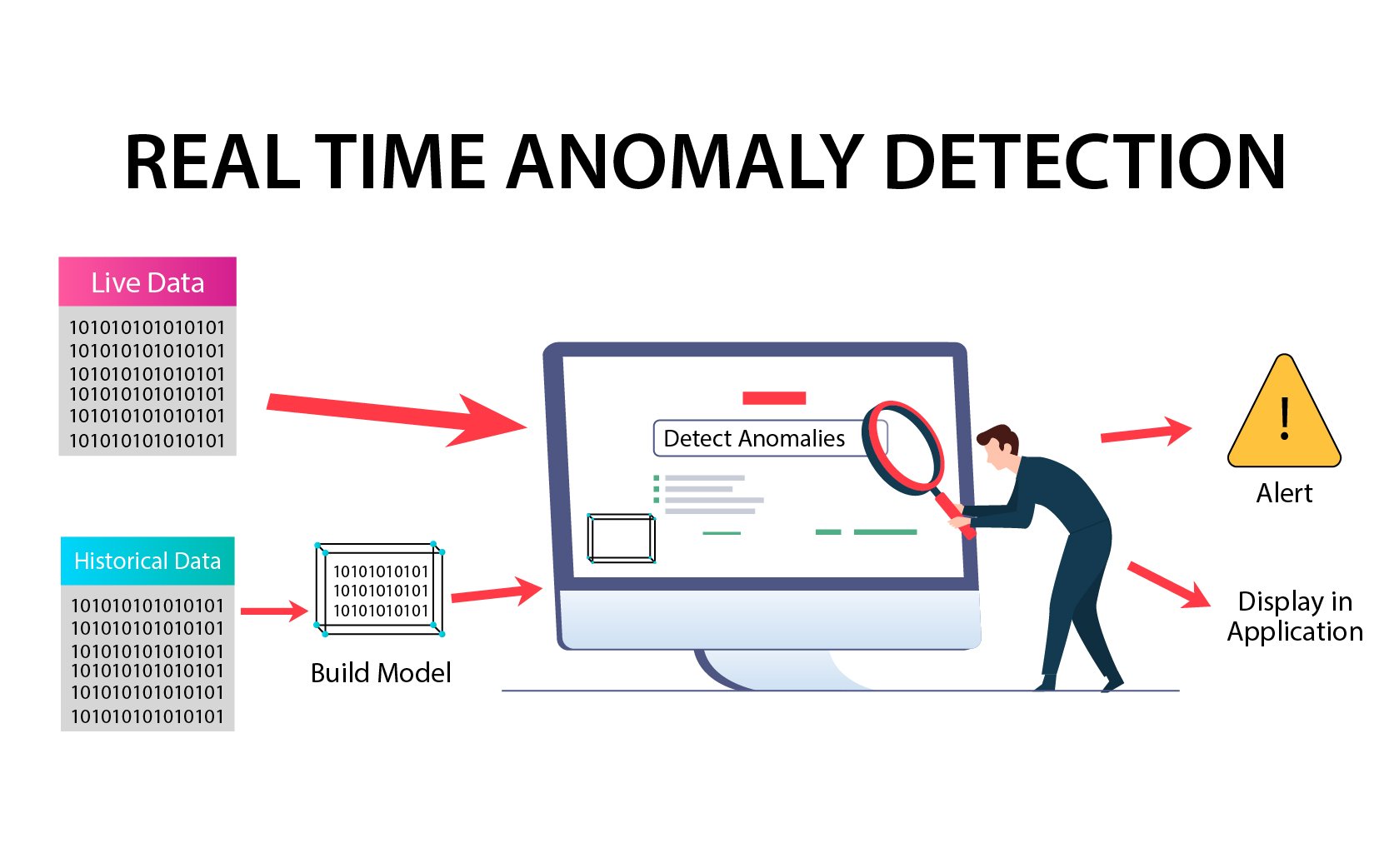
Anomaly/Fraud Detection
A critical use case of classification is in Banking, Financial Services, and Insurance (BFSI domains). Finding fraud transactions is of utmost importance, and sophisticated classification algorithms are created and implemented to work in real-time.
Also Read: Guide to Anomaly Detection
For example, a fraud detection model may determine a transaction as a fraud based on the unusual location, purchased product, transaction amount or time, etc. Similar concepts can be applied to find plausible loan defaulters, other non-repayers, etc.
Conclusion
Classification is an integral tool for statistical problem analysis. The classification technique uses categorized training data to label related datasets. Various techniques are available for class modeling.
Depending upon the relationship between the dependent and independent variables, classification and classifiers can be selected to get optimal class labeling. The algorithms have different data processing and feature engineering techniques for the classification process.
For any Data Scientist, learning classification is of utmost importance. Aspirants must focus on all the dimensions of classification- business problems that can be solved through classification, inner workings of algorithms, evaluation, and validation mechanism of a classification model.
FAQs
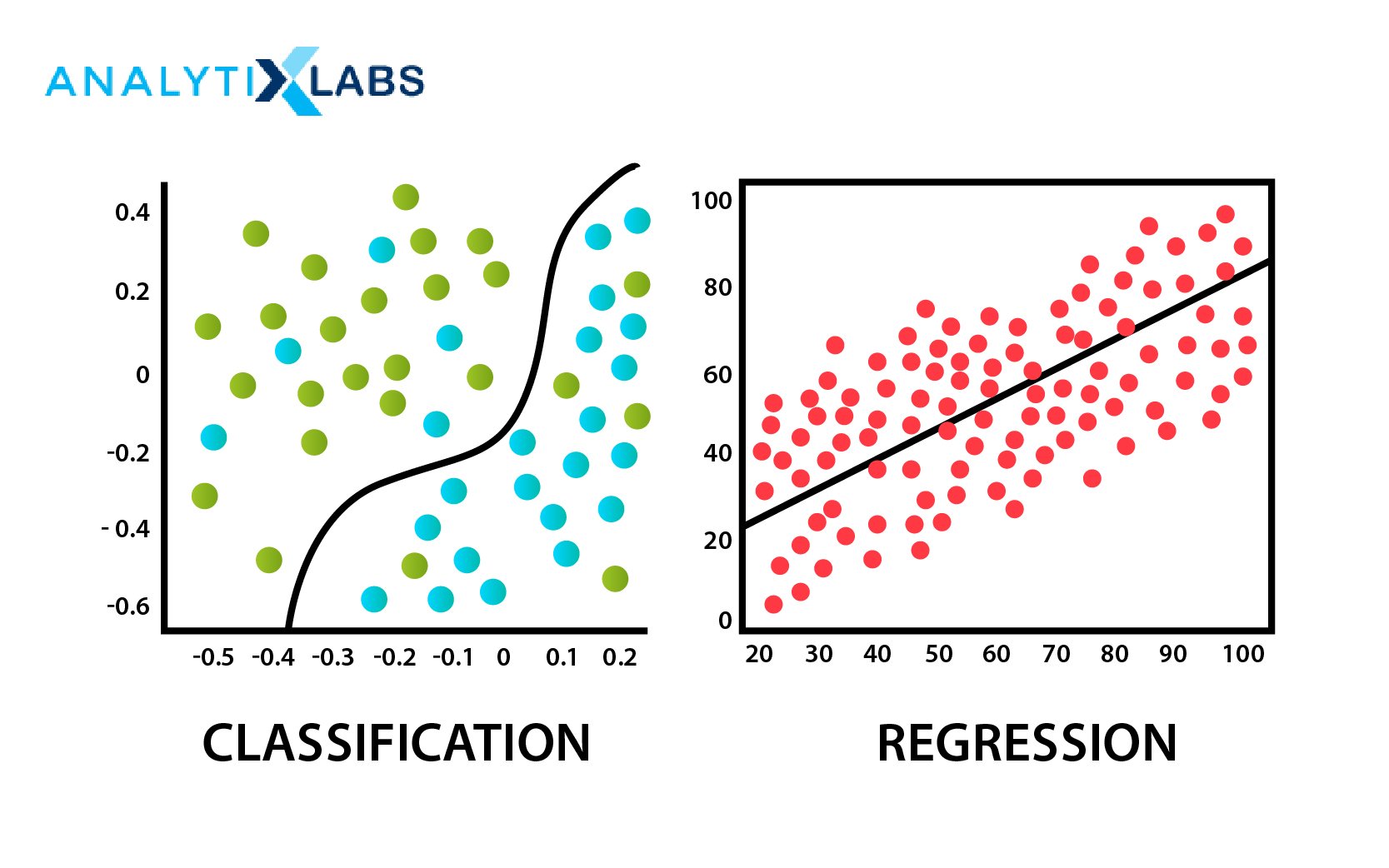
- What are Classification and Regression in Machine Learning?
Classification and Regression are the same. While working in the machine learning setup, try to identify the pattern between input variables (X variables) and the target variable (Y variable).
The difference is that in classification, the categorical Y variable is comprised of classes, etc., whereas in regression, the Y variable is a continuous numerical variable. The difference impacts the functioning of the involved algorithms and model evaluation methods.
- What is the use of Classification?
Classification is an integral part of machine learning, which allows useful categorization for businesses.
- For example, it can help businesses classify their customers into different segments based on their characteristics such as age, gender, income levels, and more. This categorization can then be used to better target specific customer groups with marketing campaigns or product offerings.
- It can also be used in fraud detection to quickly identify any suspicious activity that does not fit the usual pattern. Additionally, classification algorithms are often used for sentiment analysis of text data, which helps organizations understand the feelings behind customer reviews and feedback.
- Furthermore, it is also useful in Natural Language Processing (NLP) tasks such as automated answering customer queries and machine translation.
- Ultimately, classification gives businesses valuable insights into their own data and allows them to make better decisions that drive growth and increased profits.
Additional Resources to Read