
In the real world, we need clean and structured data extracted from the bulk of raw data to work with a machine learning model. You may have heard that 80% of a data scientist’s time goes into data preprocessing and 20% of the time into model building. This isn’t false and is actually the case.
With this article, you will understand in detail the concept of data preprocessing in machine learning, the approach of data cleaning, the need for data preprocessing, and different data preprocessing techniques in machine learning. Followed by the data preprocessing steps in machine learning and a discussion of some of the most frequently asked questions.
What is Data Processing?
The concept of Data Processing is collecting, organizing, and transforming data into a set of useful information. It describes all procedures necessary in the processing of data to transform it into insight that can be used to take action.
It’s a crucial phase in any process because it makes decision-making easier and increases the value of the information. Strategic decisions are made using this data to enhance corporate processes.
Before processing can begin, data must be initially collected, involving tasks such as entering data into the database and scanning receipts at the point of sale. After gathering the data, it’s crucial to organize it.
Organizing data helps you understand what you have and how to use it efficiently in upcoming tasks. Data processing also includes tasks such as cleaning, confirming, improving, analyzing, and converting various forms of data.
Why do we need Data Preprocessing?
Data preprocessing is needed because good data is undoubtedly more important than good models and for which data quality is paramount. Therefore, companies and individuals invest much time in cleaning and preparing the data for modeling. The data present in the real world may not contain relevant, specific attributes and could have missing values, even incorrect and spurious values.
To improve the quality of the data, preprocessing is essential. The preprocessing helps to make the data consistent by eliminating any duplicates, and irregularities in the data, normalizing the data to compare, and improving the accuracy of the results. The machines understand the language of numbers, primarily binary numbers 1s, and 0s.
Recently, a significant portion of the generated and available data is unstructured, meaning it does not follow a tabular format or possess a fixed structure. The most consumable form of unstructured data is text, which comes from tweets, posts, and comments. Data in the format of images and audio often requires preprocessing as it is not readily compatible with the format that can be directly fed into a model.
So, for the parsing, we need to convert or transform the data so the machine can interpret it. Again to reiterate, data preprocessing is a crucial step in the Data Science process.
Data Preprocessing in Machine Learning
Data preprocessing is essential in machine learning to prepare the data for training and creating precise models. It takes several stages before submitting the raw dataset to machine learning algorithms.
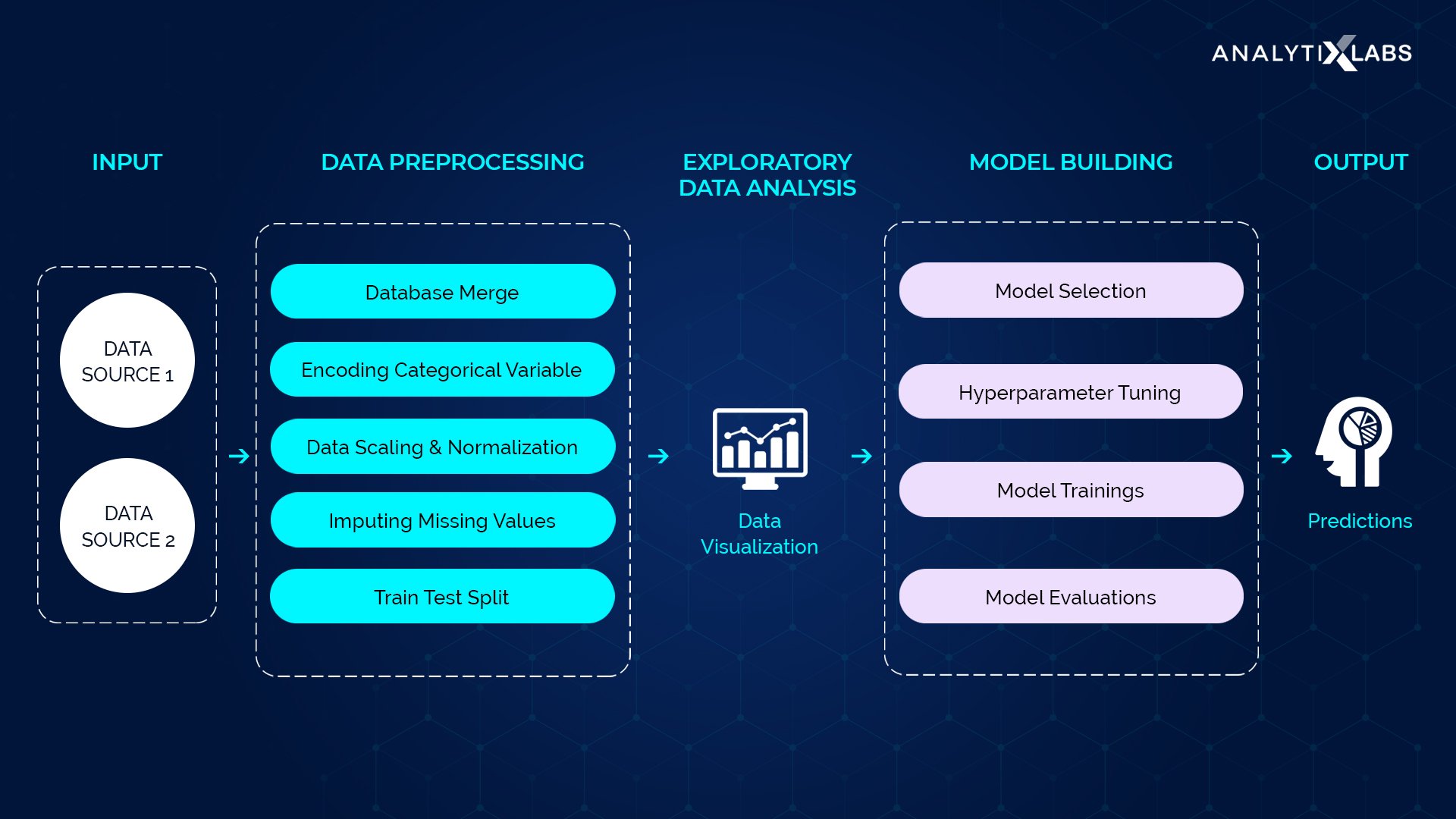
The following are some essential elements of machine learning’s data preprocessing:
-
Handling Missing Data:
Datasets often contain missing values, which can cause issues during model training. To address this, data preparation techniques are necessary. These techniques range from simple methods like mean, median, or regression-based imputations to more complex ones like multiple imputations.
-
Working with Outliers:
Outliers are extreme or incorrect data points that may negatively impact the model’s performance. Outliers must be recognized and handled during data preprocessing. If errors are errors, they can be eliminated, transformed using truncation or Winsorization, or treated as a separate class during modeling.
-
Scaling and Normalisation
Features with different sizes or distributions can impact the performance of certain machine learning algorithms. Scaling and normalization are two data preprocessing techniques that equalize the scale or distribution of the features.
Standardization (mean = 0, variance = 1) and min-max scaling (scaling values to a given range) are common scaling strategies.
-
Feature Selection and Dimensionality Reduction
Datasets frequently have a lot of features, some of which may be superfluous or redundant. Techniques for feature selection assist in selecting the model’s most instructive features. T-distributed stochastic neighbor embedding (t-SNE) and Principal component analysis (PCA) are two methods for reducing the number of dimensions while retaining the most crucial data.
-
Handling Unbalanced Data
Unbalanced datasets, in which one class has a disproportionate number of instances, might result in biased models that favor the dominant class.
Data preprocessing techniques, including undersampling the majority class, oversampling the minority class, or utilizing advanced methods like SMOTE (Synthetic Minority Over-sampling Technique), enhance the performance of the model. This is particularly effective when the dataset is balanced.
Also read: What is Classification Algorithm in Machine Learning?
What are the Data Preprocessing Techniques?
The data preprocessing techniques in machine learning can be broadly segmented into Data Cleaning and Data Transformation. The following flow-chart illustrates the above data preprocessing techniques and steps in machine learning: Source: ai-ml-analytics
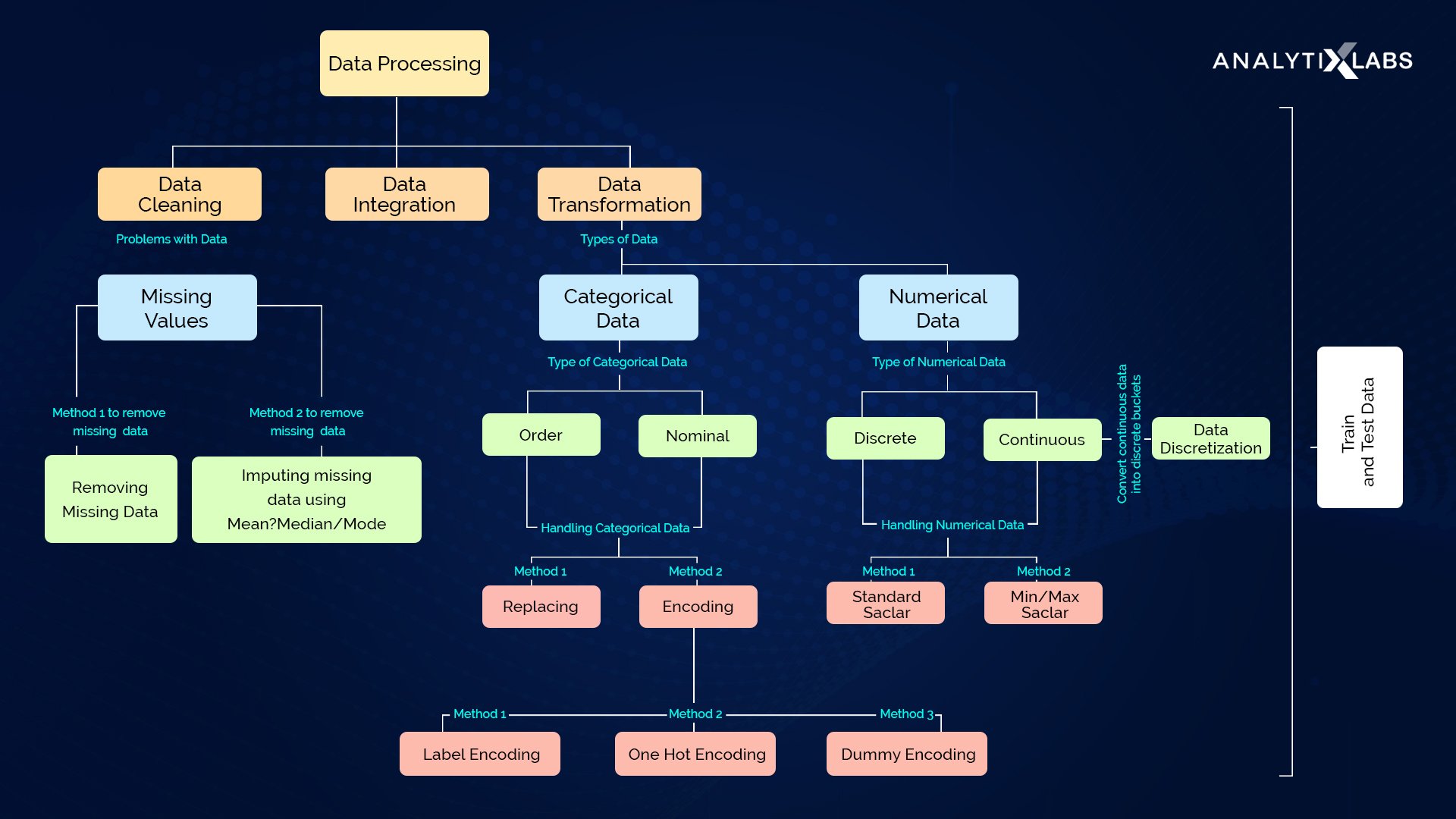
Data Cleaning/ Cleansing
As we have seen, the real-world data is not complete, accurate, correct, consistent, and relevant. The first and the primary step is to clean the data. There are various steps in this stage; it involves:
1) Making the data consistent across the values, which can mean:
- The attributes may have incorrect data types and are inconsistent with the dictionary. Correction of the data types is necessary before proceeding with data cleaning.
- Replace the special characters; for example, replace $ and comma signs in the Sales/Income/Profit column, i.e., making $10,000 as 10000.
- Making the date column format consistent with the format of the tool used for data analysis.
2) Check for null or missing values and negative ones. The relevancy of the negative values depends on the data. In the income column, a negative value is spurious though the same negative value in the profit column becomes a loss.
3) Smoothing of the noise present in the data by identifying and treating for outliers.
Please note the above steps are not comprehensive. The data cleaning steps vary and depend on the nature of the data. For instance, text data consisting of reviews or tweets must be cleaned.
And make the cases of the words the same, remove punctuation marks, and any special characters, remove common words, and differentiate words based on the parts of speech. Now, let’s understand how to handle the missing values and outliers in the data.
Handling the Null/Missing Values
The null values in the dataset are imputed using mean/median or mode based on the type of data that is missing:
- Numerical Data: If a numerical value is missing, replace that NaN value with mean or median. It is preferred to impute using the median value as the average, or the mean values are influenced by the outliers and skewness present in the data and are pulled in their respective direction.
- Categorical Data: When categorical data is missing, replace that with the value that is most occurring, i.e., by mode.
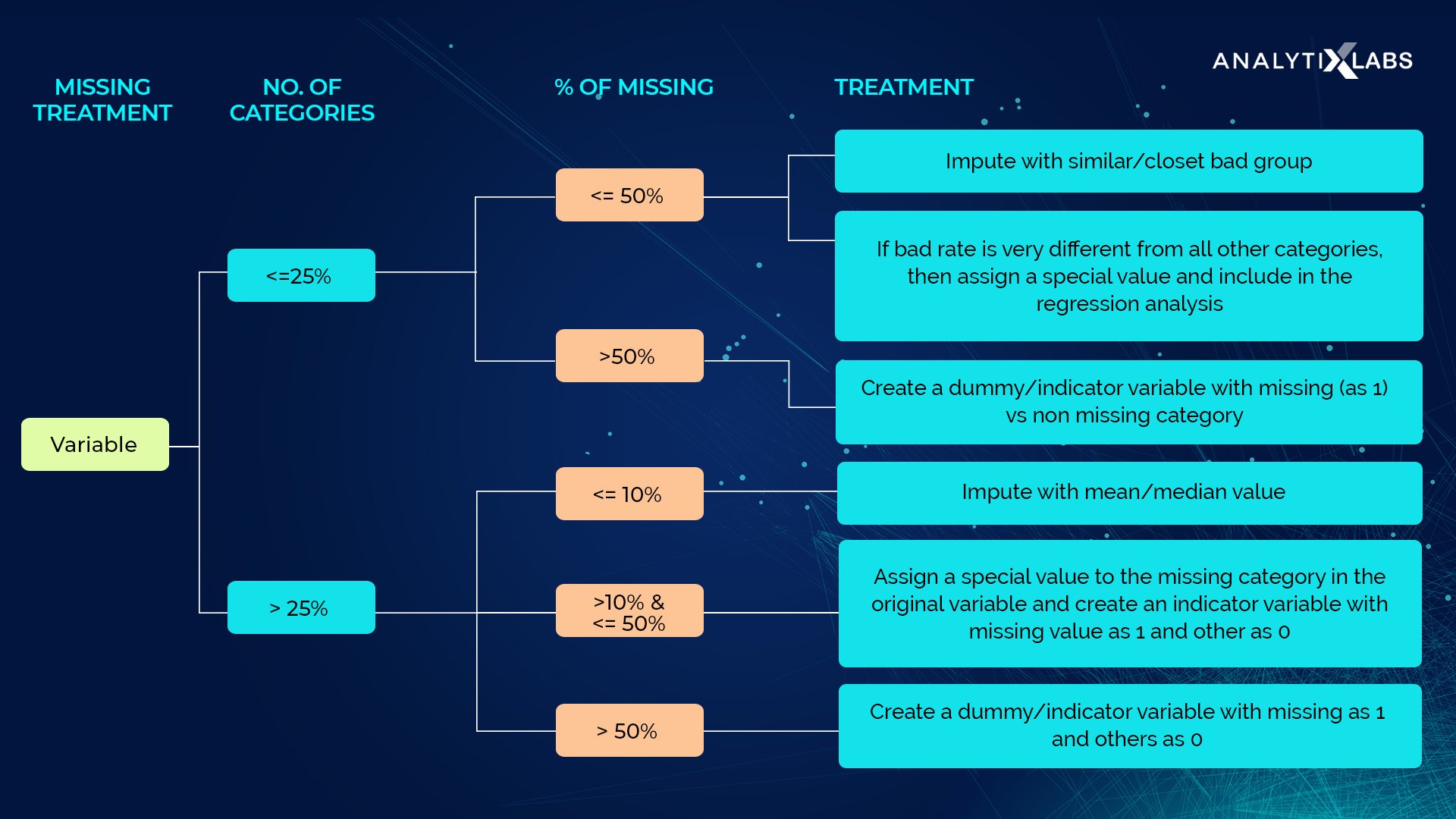
Now, if a column has, let’s say, 50% of its values missing, then do we replace all of those missing values with the respective median or mode value? Actually, we don’t. We delete that particular column in that case.
We don’t impute it because that column will be biased towards the median/mode value and will naturally have the most influence on the dependent variable. This is summarized in the chart below:
Outliers Treatment
To check for the presence of outliers, we can plot BoxPlot. To treat the outliers, we can either cap the data or transform the data:
-
Capping the data
We can place cap limits on the data again using three approaches. Oh yes! There are a lot of ways to deal with the data in machine learning 😀 So, can cap via:
-
Z-Score approach
All the values above and below 3 standard deviations are outliers and can be removed
There are numerous techniques available to transform the data. Some of the most commonly used are:
- Logarithmic transformation
- Exponential transformation
- Square Root Transformation
- Reciprocal transformation
- Box-cox transformation
Data Transformation
Data transformation is different from feature transformation, where the latter replaces the existing attributes with a mathematical function of these attributes. The transformation of the data we focus on is to prepare the numerical and categorical data machine. This is done in the following manner:
Numerical data
The numerical data is scaled, meaning we bring all the numerical data on the same scale. For example, predicting how much loan amount to give a customer depends on variables such as age, salary, and number of working years.
Now, in building a linear regression model for this problem, it would not be possible for us to compare the beta coefficients of the above variables as the scale of each variable is different from the others. Hence, the Scaling of the variables is essential. The two ways to scale data are Standardization and Normalization.
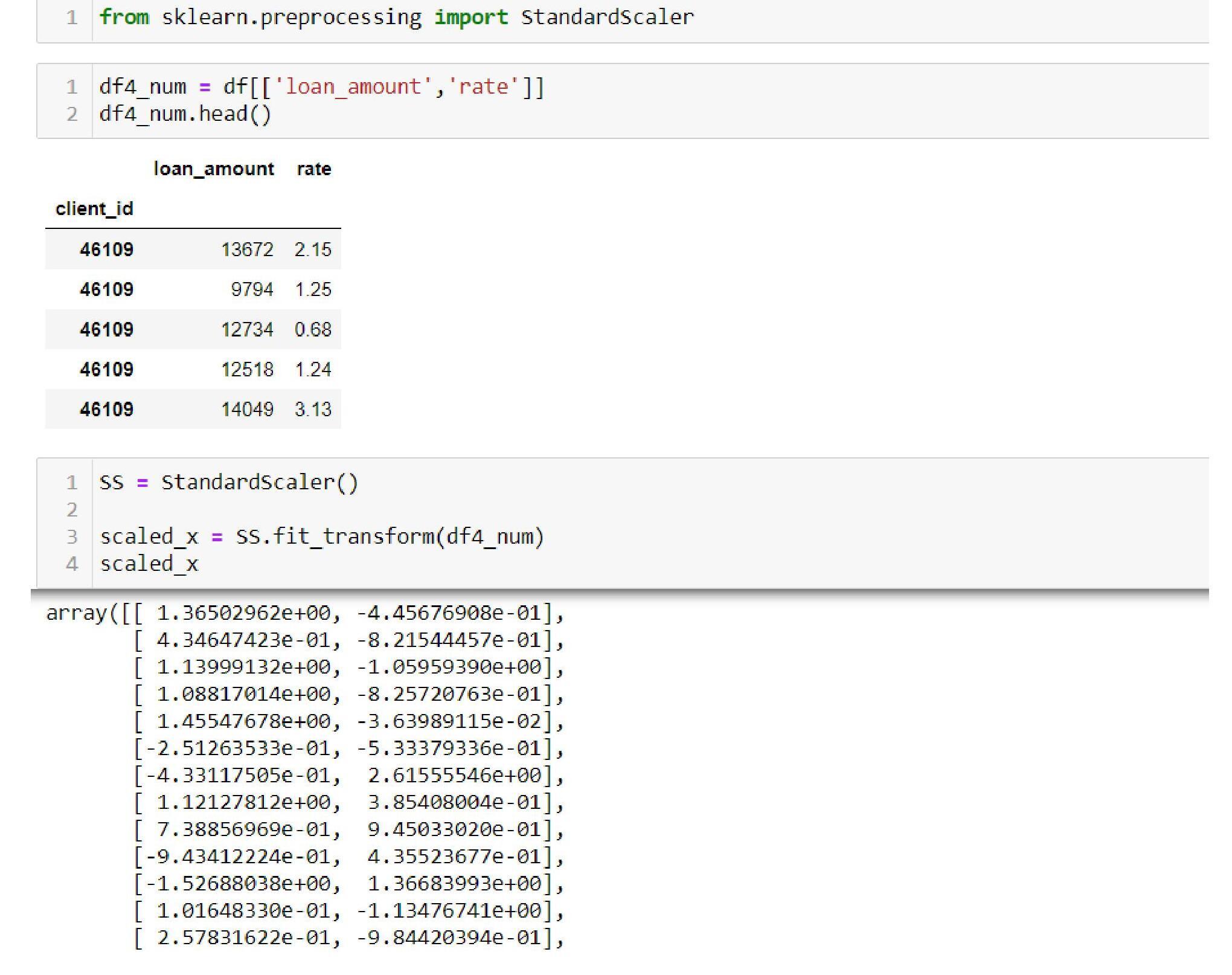
- Standardization: On the basis of the Z-score, the numerical data is scaled using the formula of calculating Z values = (x-mean)/standard deviation. The data range in the interval of -3 to 3.
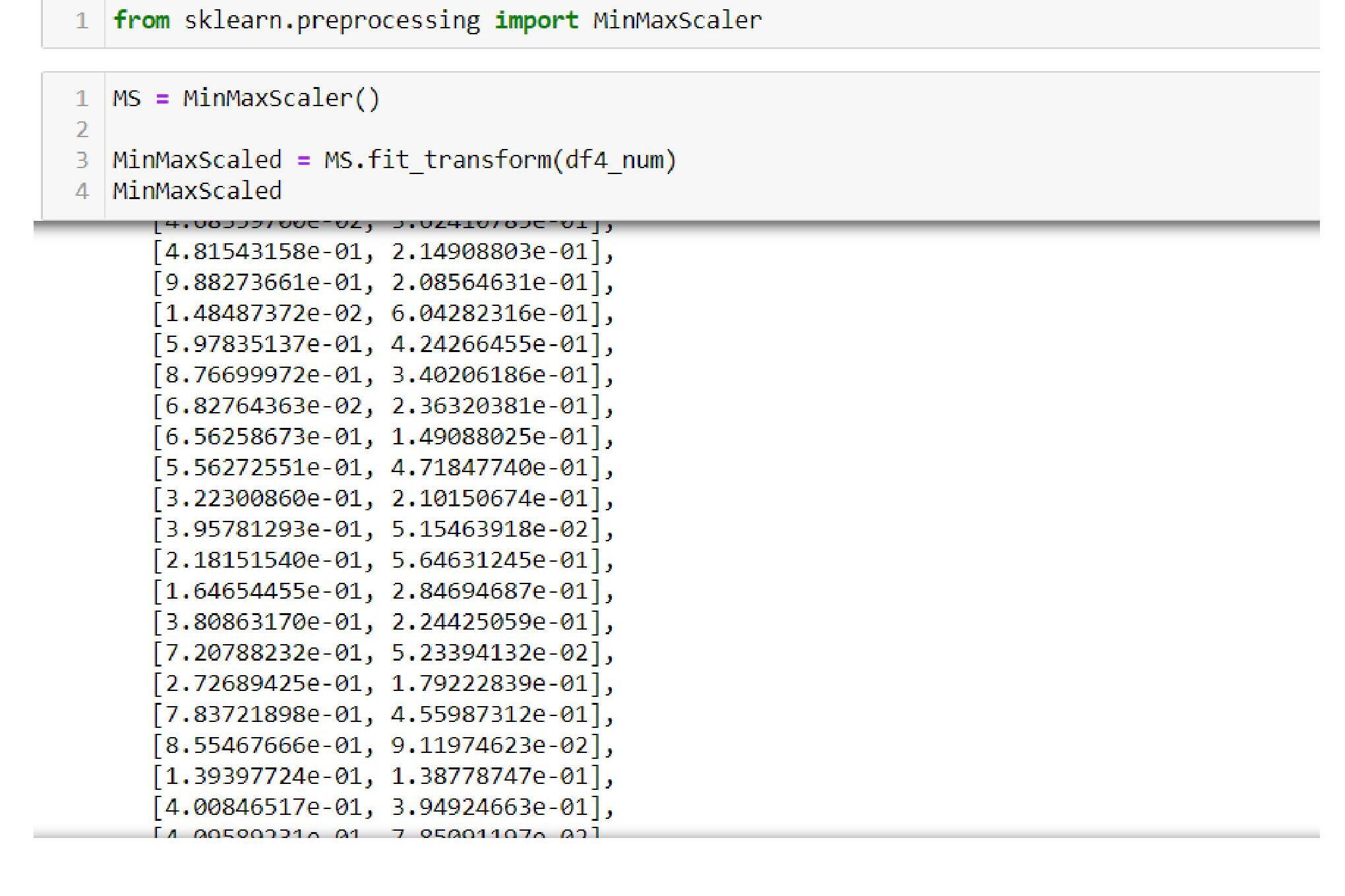
- Normalization: Here, the scaling happens using the formula: (x – min)/(max-min), reducing the data in the width of 0 to 1. This is also known as Min-Max Scalar.
Categorical Data
The categorical data can not be directly fed into the model. We have seen machines are black and white, either 1 or 0. So, to use the categorical data for our model-building process, we need to create dummy variables. Dummy variables are binary; they can take either the value of 1 or 0. If we have n types of sub-categories within a categorical column, we must employ n-1 dummy variables. There are two ways to create dummy variables:
- Pandas’ function: pd.get_dummies, and
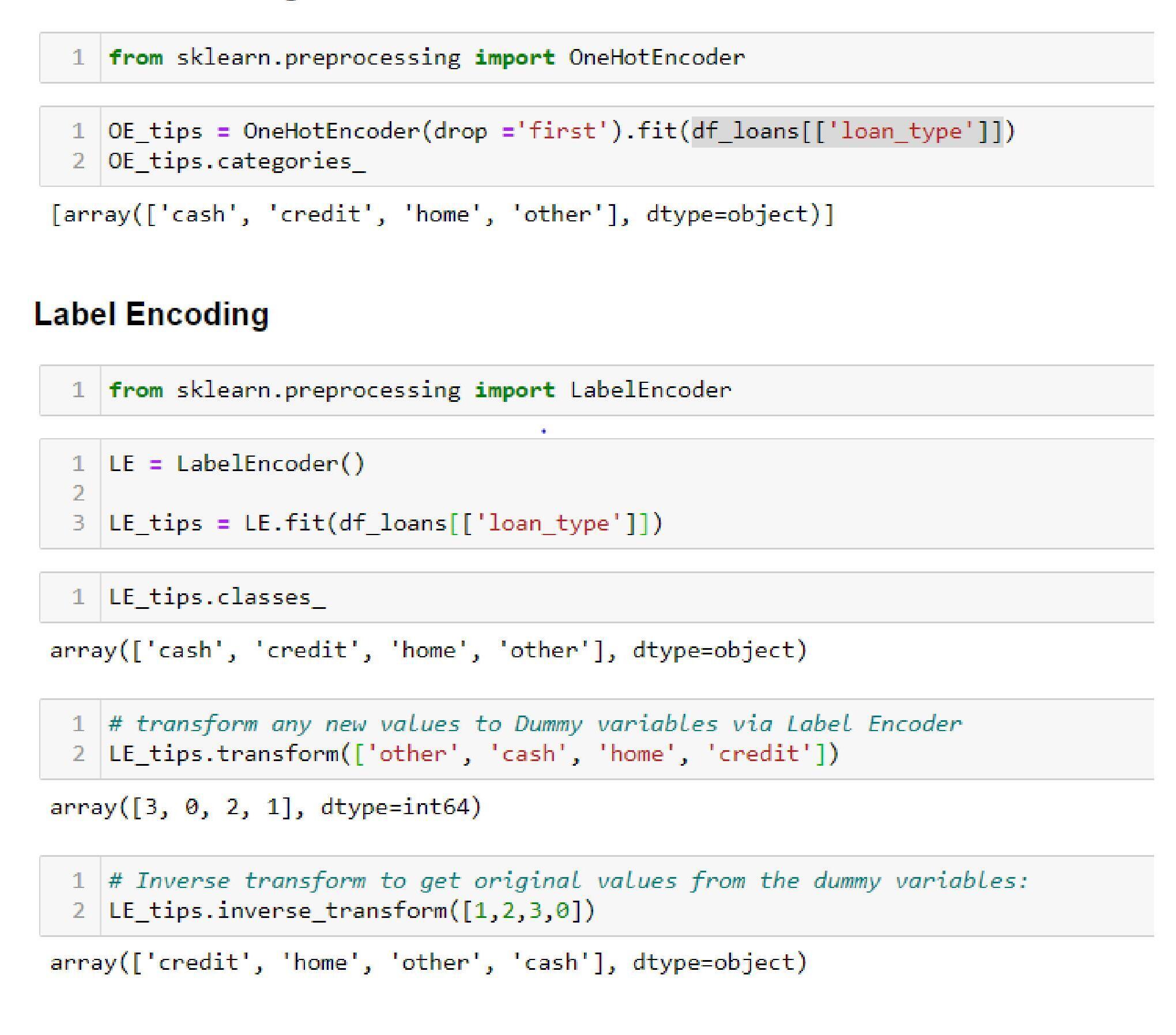
- sklearn’s in-built function of OneHotEncoder
There is one more way of dealing with categorical data, which is to use label encoding. The label encoder does not create dummy variables. However, it labels the categorical variable by numbers like below:
- Delhi –> 1
- Mumbai –> 2
- Hyderabad –> 3
Labeling encoding is limited: it converts the nominal data, which is the categorical data without any order, into ordinal data having order. In the above example, the three cities did not have order.
However, the post-applying label encoder has values 1,2,3, respectively. The machine will treat this data by giving precedence and treat the numbers as weights like 3 > 2 > 1 will make Hyderabad > Mumbai > Delhi. Hence, due to this limitation of label encoding, handling the categorical data is by creating the dummy variables.
Data Preprocessing Stage in ML
The steps in the processing of data in machine learning are:
- Consolidation after the acquisition of the data
- Data Cleaning
- Detection and treatment of missing values
- Treating for negative values, if any, present depending on the data
- Outlier detection and treatment
- Transformation of variables
- Creation of new derived variables
- Scale the numerical variables
- Encode the categorical variables
- Split the data into validation, training, and test set
The Data Cleaning stage consists of the following additional steps:
- Convert the data types if any mismatch is present in the data types of the variables
- Change the format of the date variable to the required format
- Replace the special characters and constants with the appropriate values
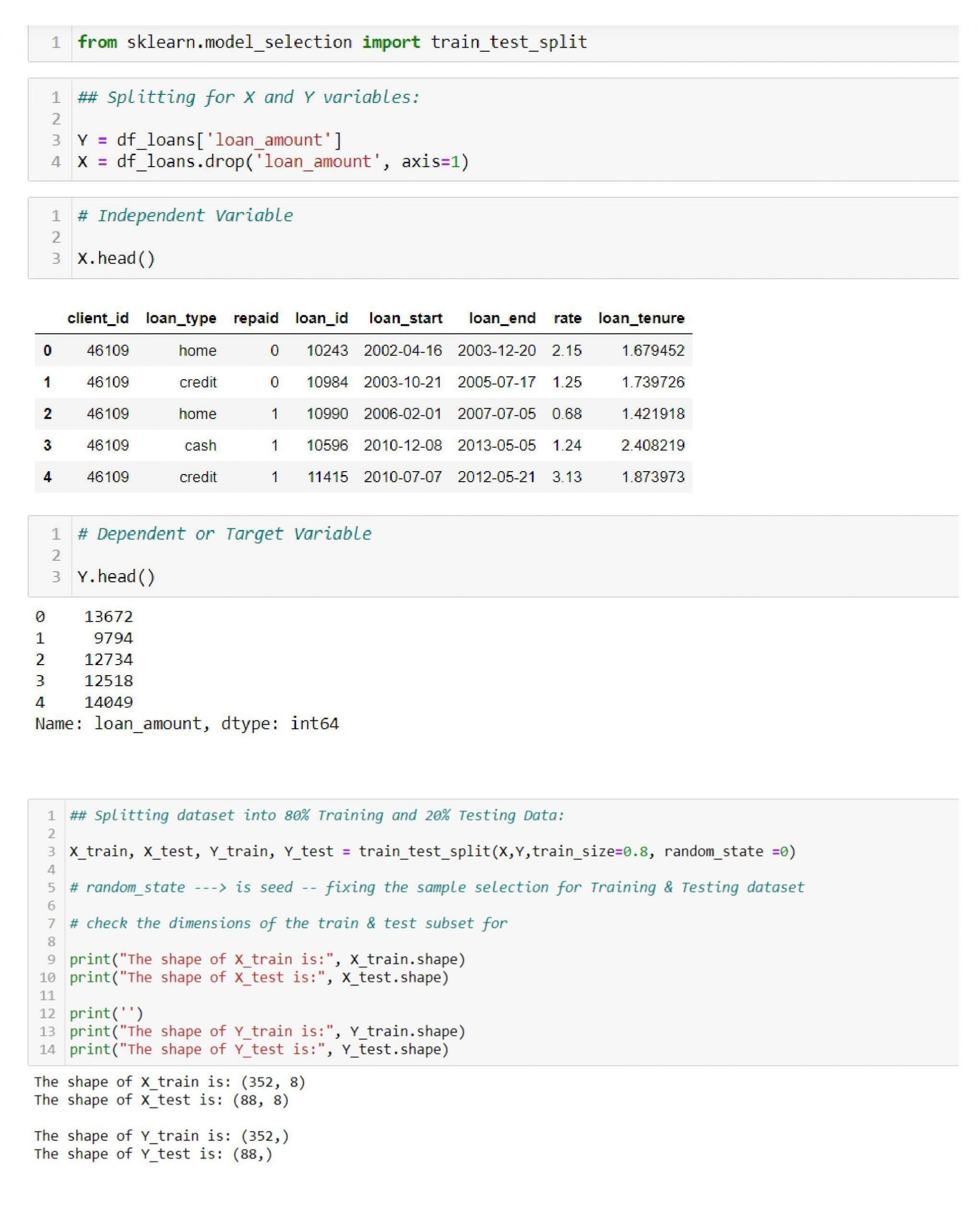
We will look into the above data preprocessing steps in machine learning with an example below. We will work with a dataset on loans. The loan data has the following features and shapes:
Importing the Data
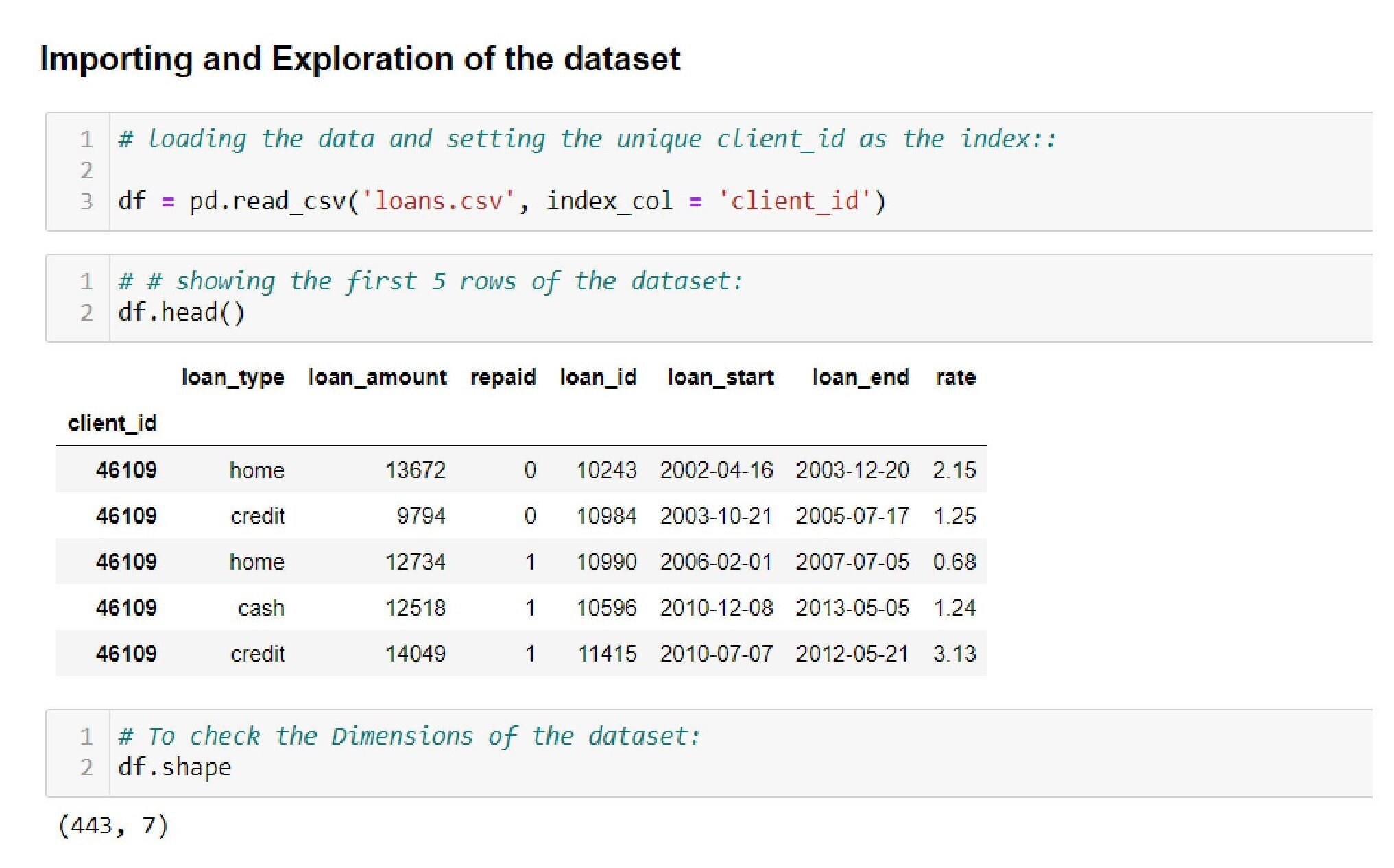
Conversion of the Data Types
In this data processing stage, post-checking the datatypes of the columns, convert the data types of the following features:
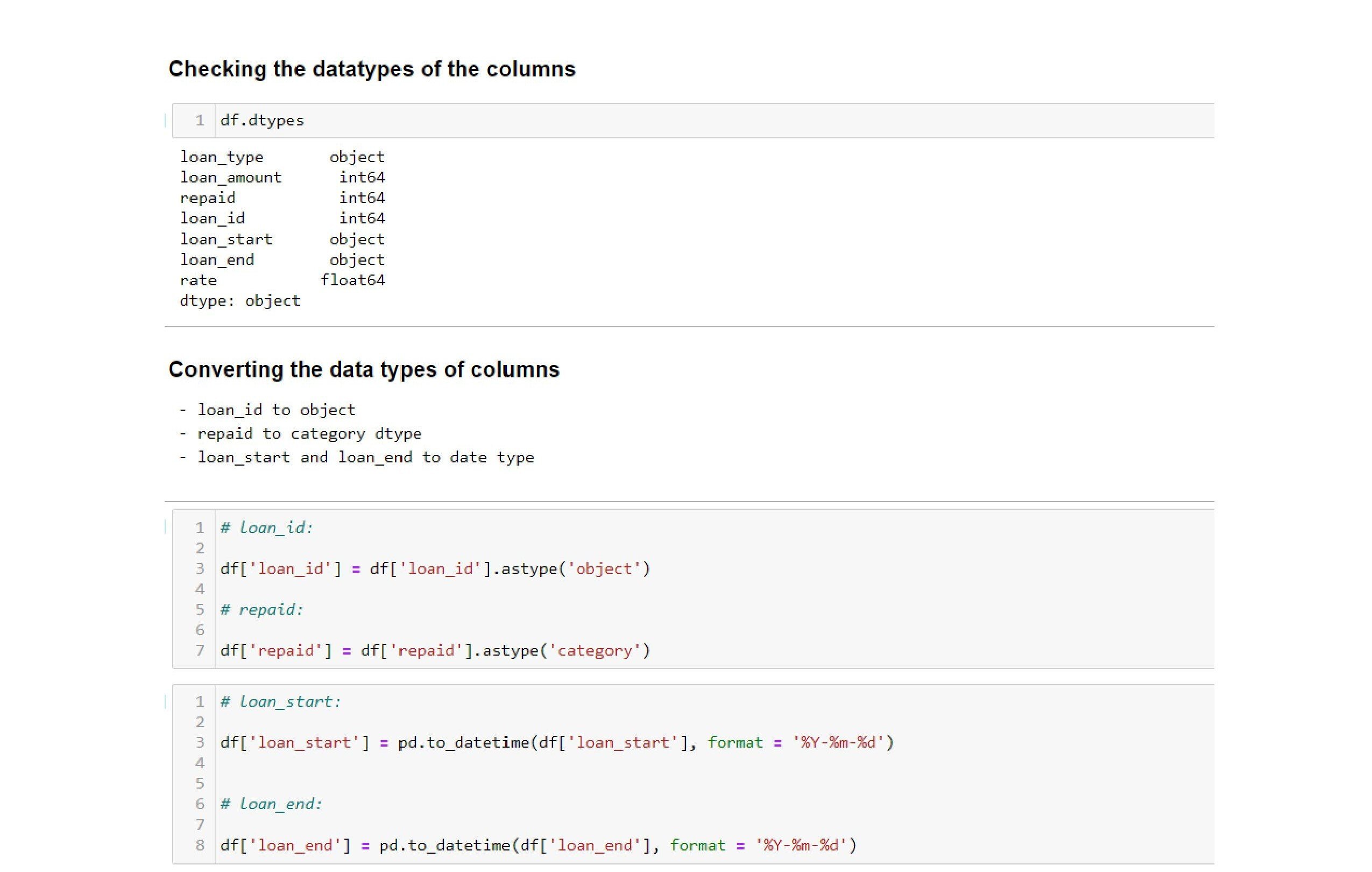
Missing Values
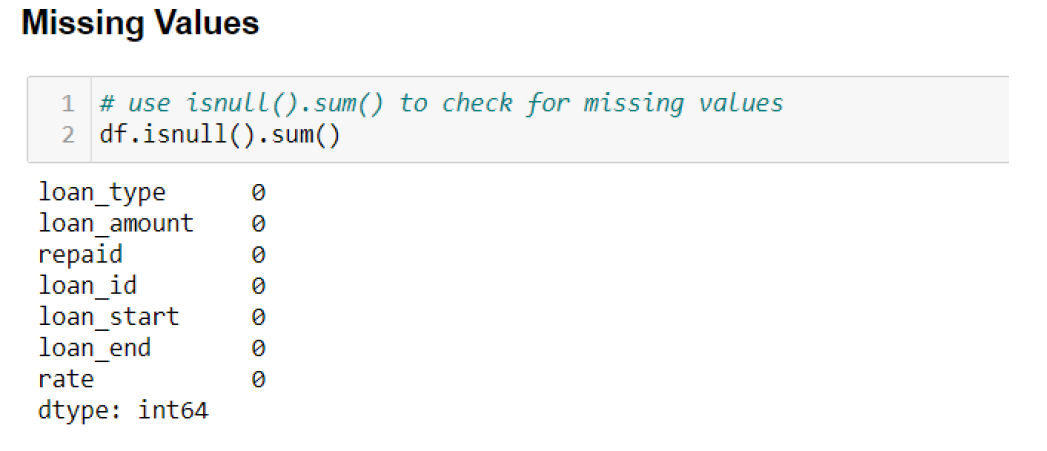
Outliers
- Z-score:
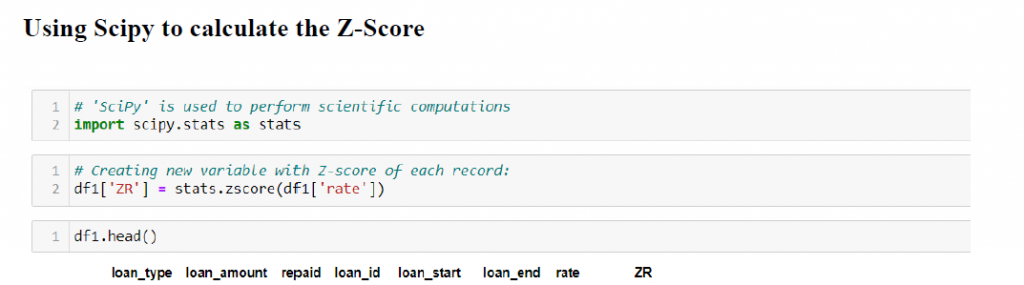
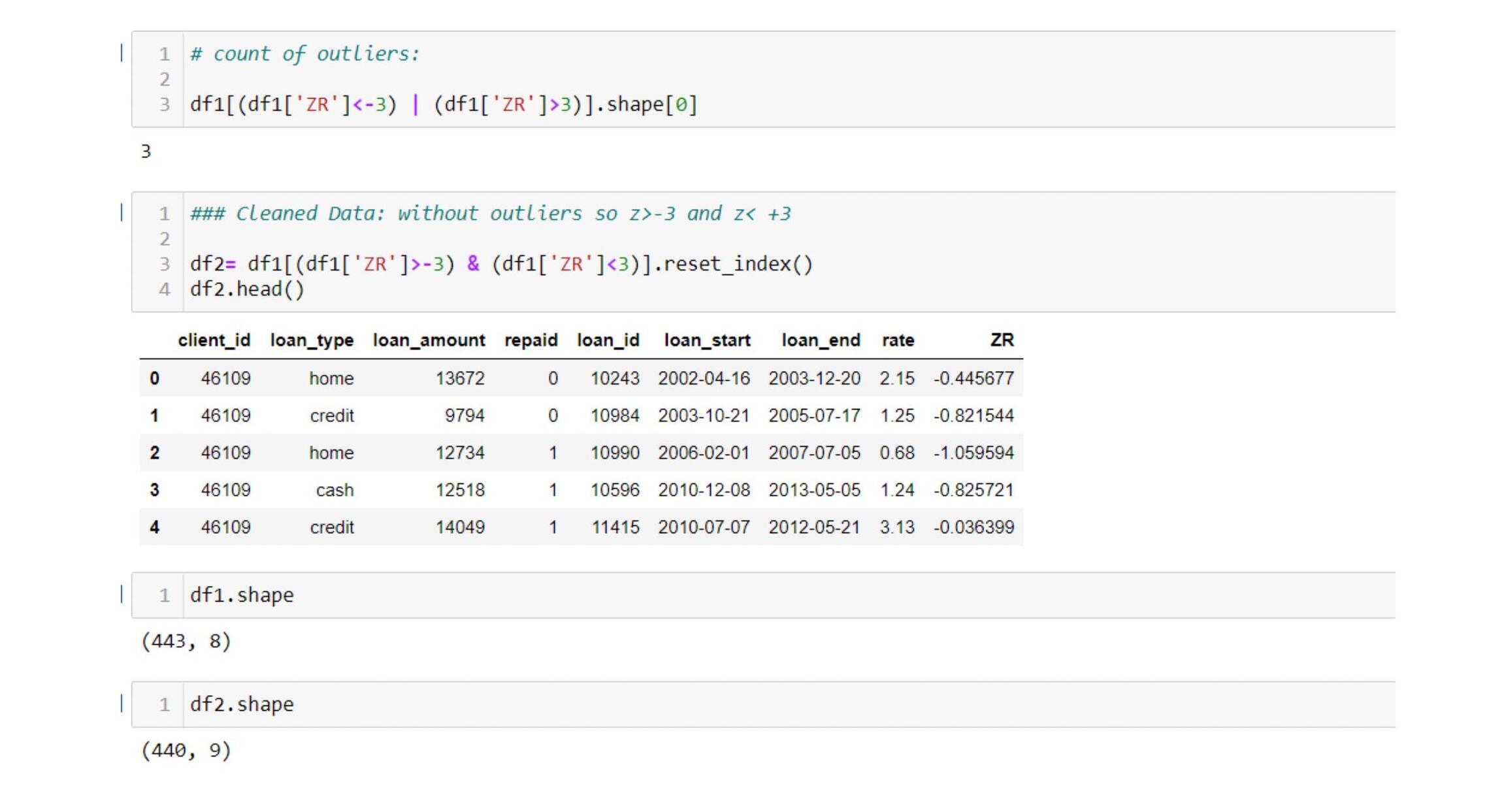
- IQR Method:
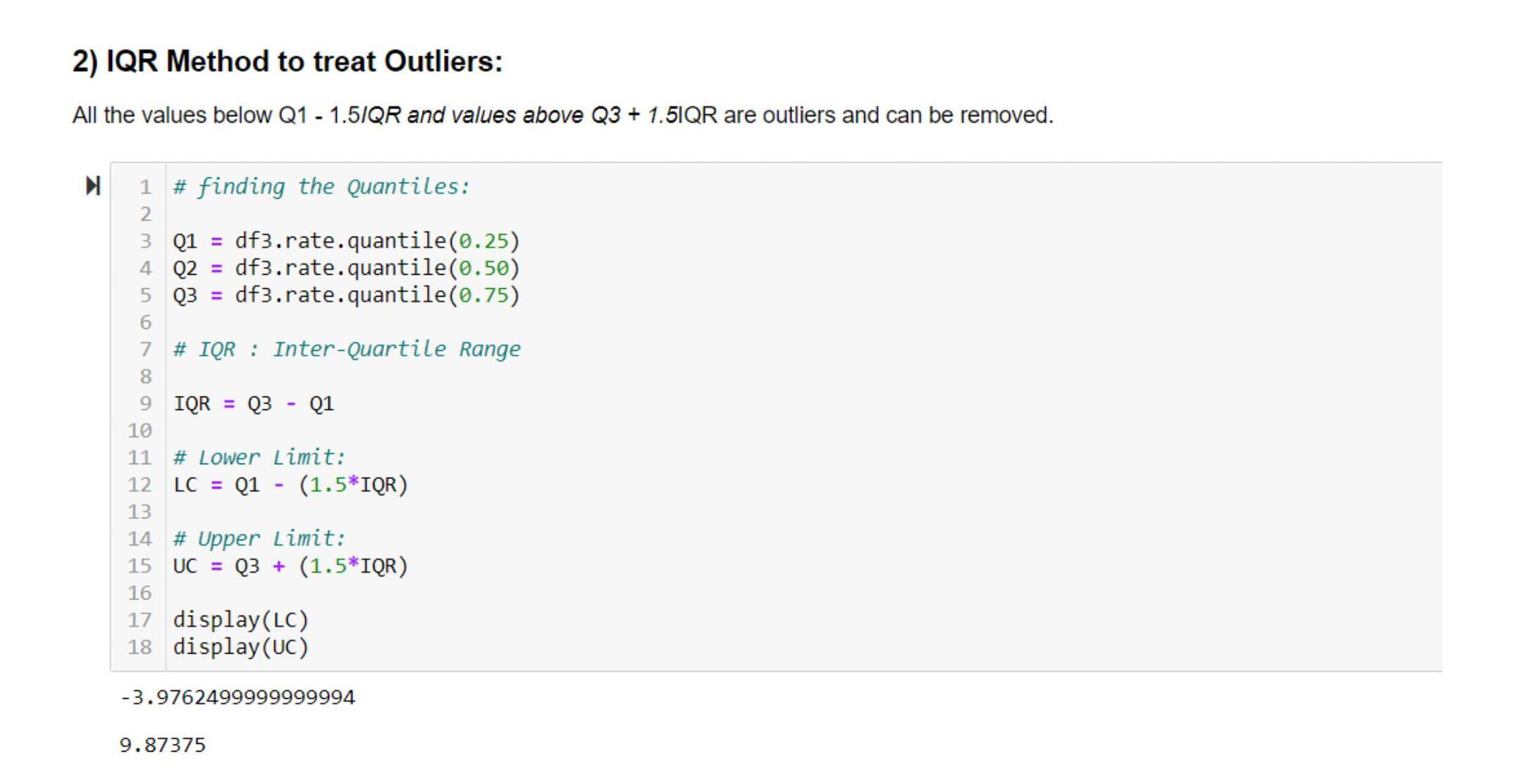
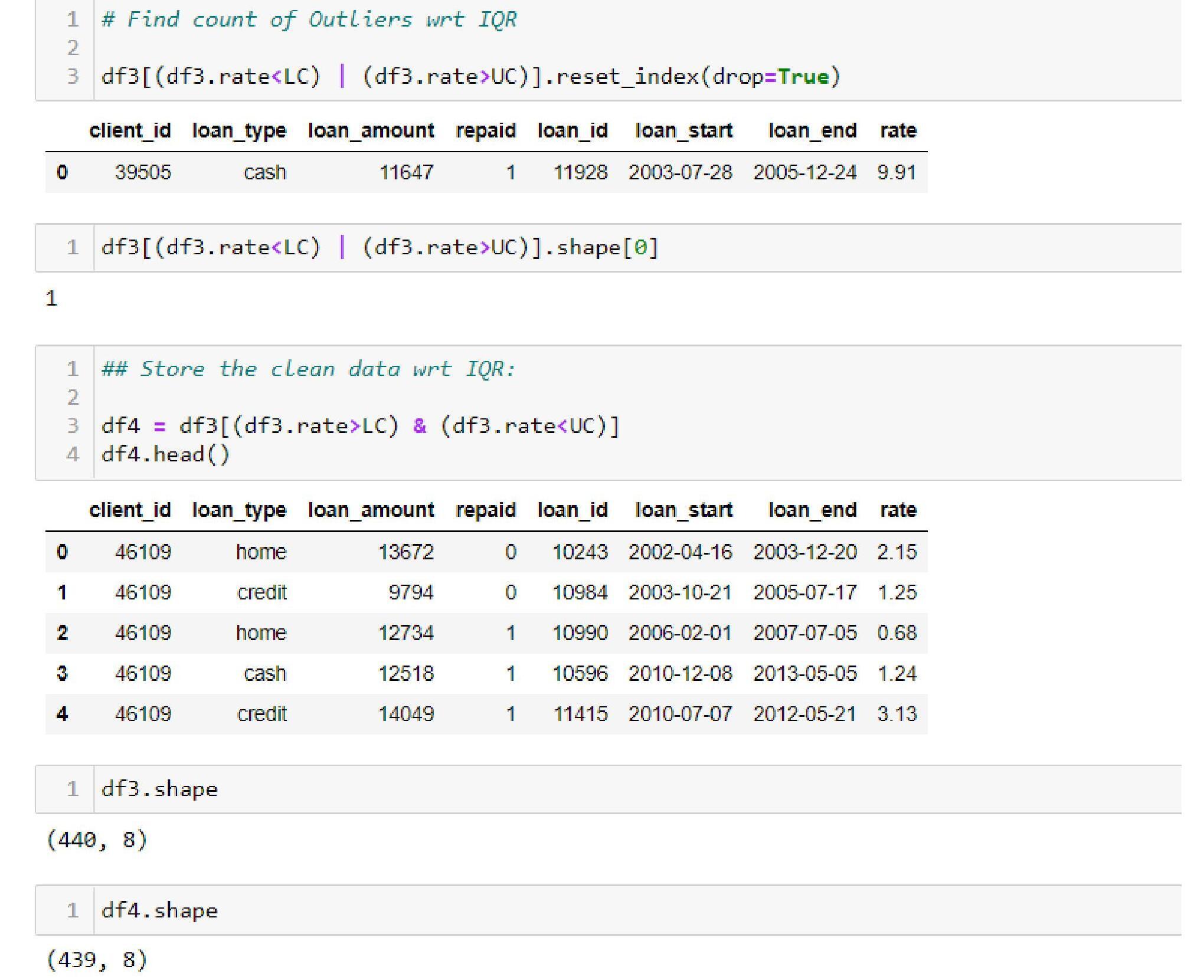
A crude way to know whether the outliers have been removed or not is to check the dimensions of the data. Both the above outputs show that the data dimensions are reduced, which implies the outliers are removed.
Scaling the Numerical Values
- Standardization or Z-Score approach:
- Normalizing or Min-Max Scaler:
Encoding the Categorical Variables
- Pd.get_dummies approach:
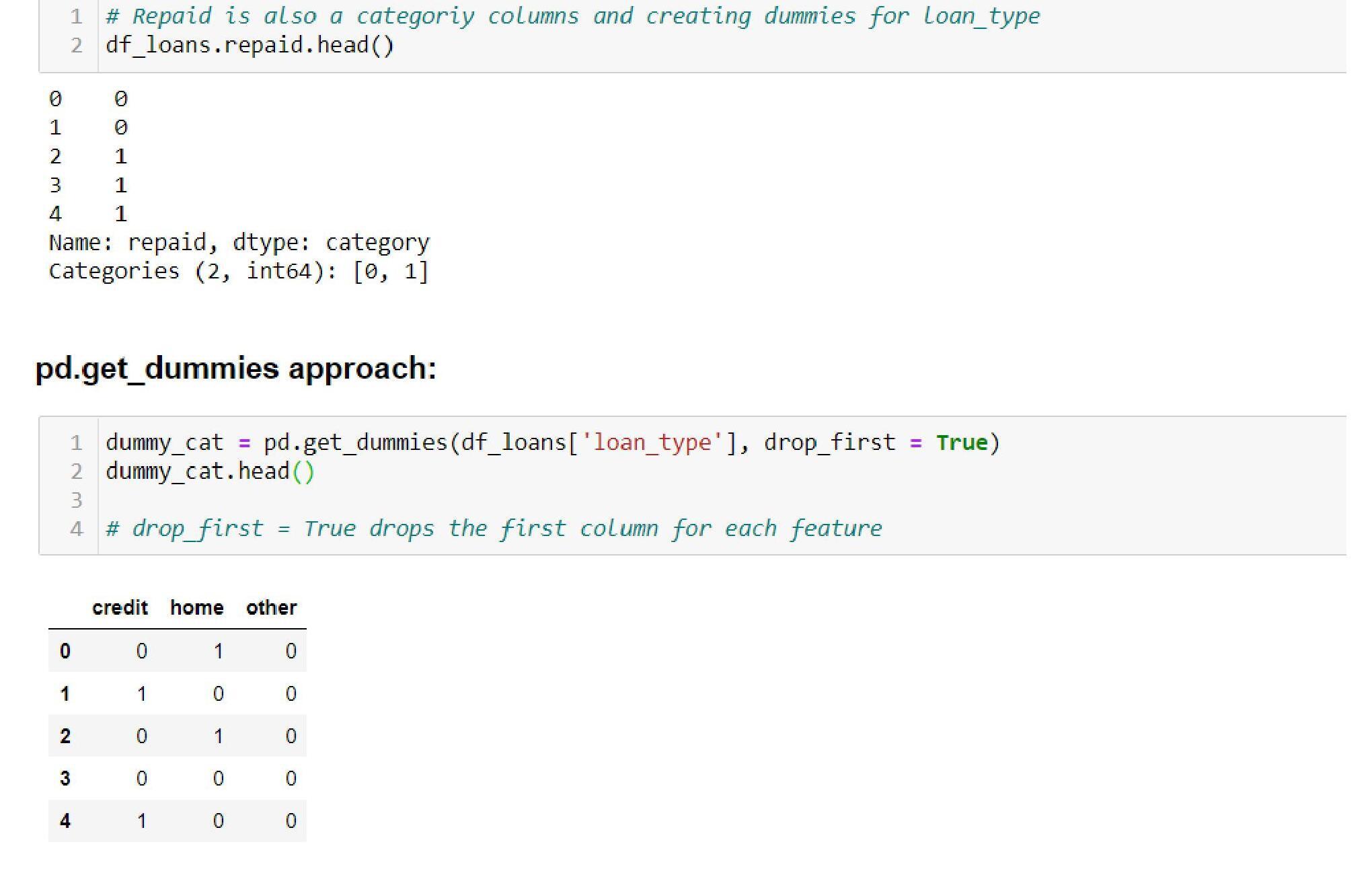
- One-Hot and Label Encoding:
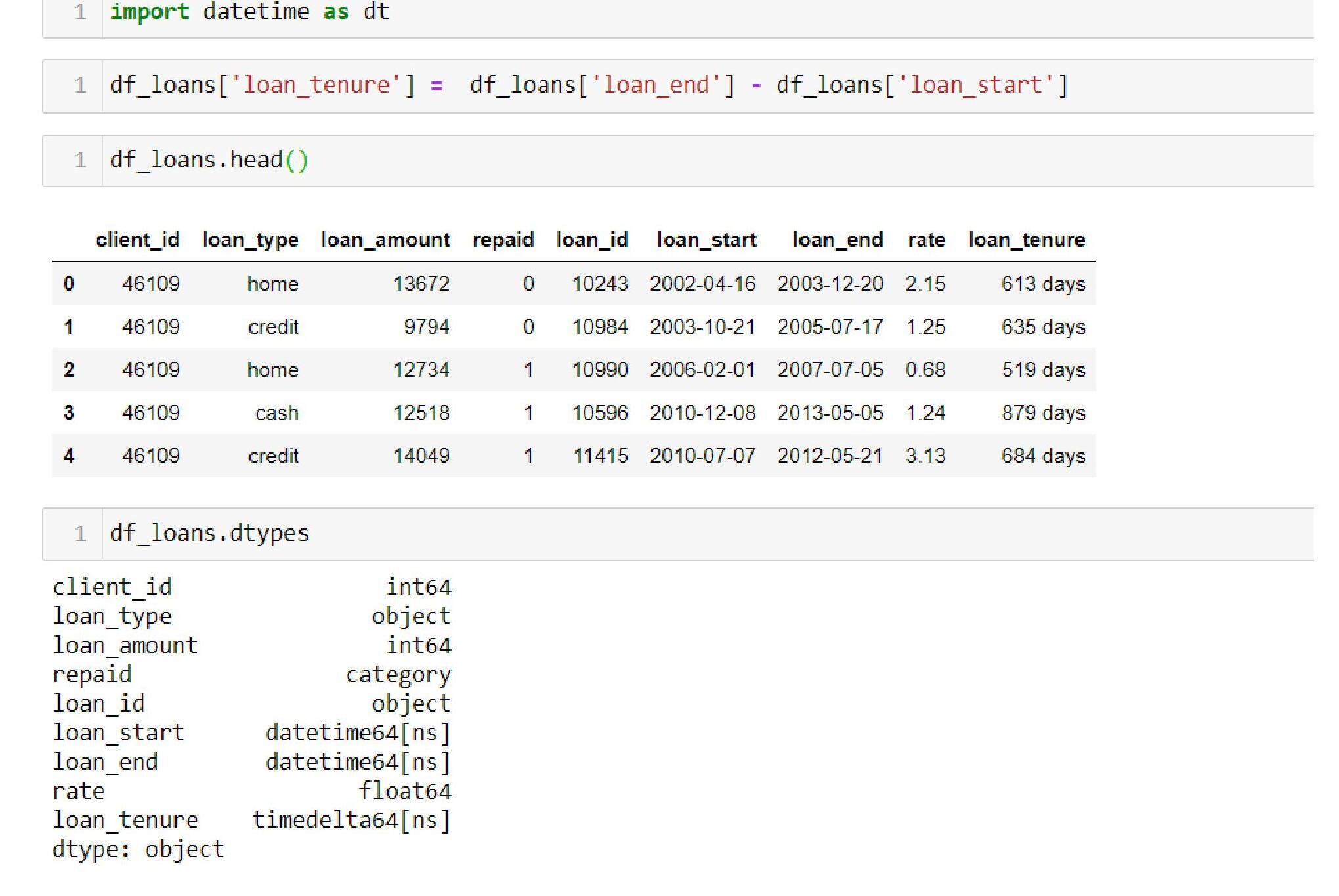
Creation of New Variables
We can use the loan_start and loan_end features to calculate the loan tenure.
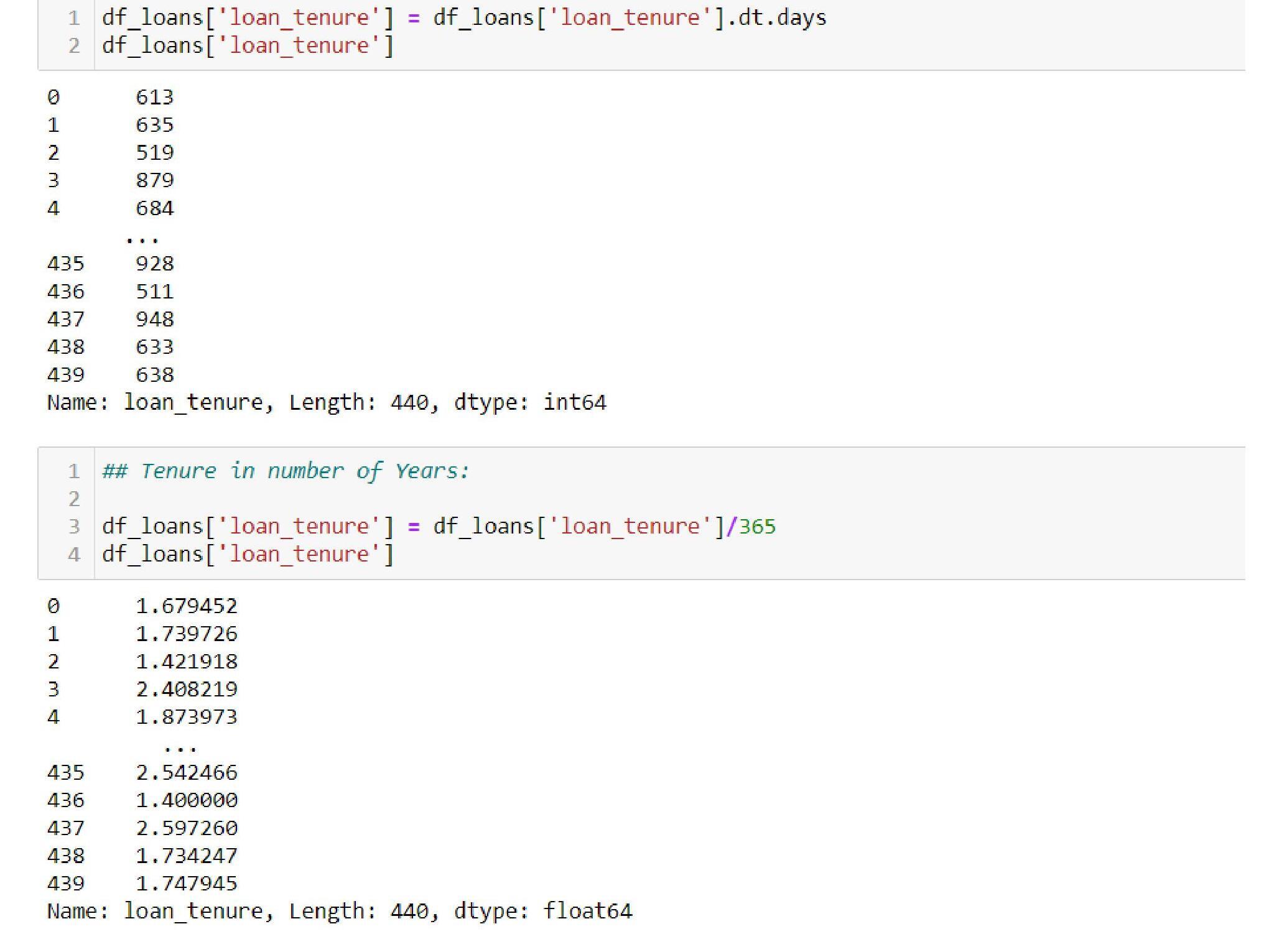
The number of days in the tenure is currently in TimeDelta. We want it to be integer hence will do the conversion as follows:
Splitting data into Train-Test sets
Post the data preparation, we can proceed to build the model by dividing this data into three parts. One is for training the model, the other is for validating the data, and the last part is for testing data. Training data is on which the machine learning algorithms are used to build the model. The model learns and identifies the hidden patterns in this dataset.
Validation data is used to validate the models that are built.
Using this data helps assess the model’s performance by checking the training and validation accuracy, which provides insights into the presence of overfitting or underfitting. It is then utilized to improve the model and fine-tune the parameters.
Training data is different from the above two sets. The unseen data on which the model is used to predict the values or classes, as the case may be.
Data Preprocessing in Data Mining
Data Preprocessing comes under the various steps that Data Mining involves. Under preprocessing, we convert the raw data into a more valuable, structured, and practical format. Different data preprocessing techniques in data mining, like cleaning, integration, selection, transformation, and reduction, help obtain the essential data. Here, we have discussed a few steps of data processing in data mining-
- Data cleaning: Under cleaning, the irrelevant, unstructured, and useless data get removed from the dataset. This step ensures the quality and accuracy of data and works on the reliability of the results we get from data mining.
- Data integration: This step leads to the formation of a single dataset comprising useful data from various sources. It may involve working on inconsistent data and record matching of datasets.
- Data transformation: This is the most crucial step of data preprocessing in data mining. This step converts the data into a usable format for data mining. It uses various techniques like discretization, normalization, and feature engineering.
- Data reduction: This step gives us the most important part of the data while reducing the size of the dataset. Data Reduction involves techniques of dimensionality reduction, sampling, and clustering.
- Data discretization: This phase transforms continuous data into discrete values to facilitate analysis. Decision trees and association rule mining are two examples of data mining methods that frequently employ them.
- Data formatting: This stage structures the data to suit the selected data mining technique. It may comprise tasks like transforming data into a specific data structure or encoding data in a specific format.
Learn more about Data Mining here.
Data processing example
Data Processing is used widely in various fields. As businesses grow, they need more accurate and large amounts of data to work with; and to upgrade their customer services and experiences; hence we have discussed some data processing examples.
- E-commerce : E-commerce businesses process massive amounts of client data for various uses. They examine client behavior, purchasing history, and preferences to personalize recommendations, improve pricing tactics, and enhance customer experience. Data cleaning, transformation, and analysis processes aid in extracting insightful information from the data.
- Financial Services : To identify fraudulent activity, determine creditworthiness, and conduct risk analysis, banks and other financial organizations process enormous amounts of transactional data. To make timely and well-informed decisions, data preprocessing techniques help uncover patterns, anomalies, and trends in financial data.
- Manufacturing : Data processing is used by manufacturing firms to enhance quality assurance, optimize production processes, and foresee equipment breakdowns. Analyzing sensor data from machines and manufacturing lines allows for performance monitoring, bottleneck identification, and implementation of predictive maintenance techniques.
Real-time data processing makes quick reactions to potential problems possible, reducing downtime and increasing production effectiveness. - Social media analysis : Social media networks process a huge volume of user-generated content, analyze the data, and extract insights using data processing techniques, including sentiment analysis, trend detection, and user profiling. Businesses can utilize this data to target marketing efforts better, understand client preferences, and increase user engagement.
- Transportation and Logistics : Data processing is essential for route optimization, forecasting of demand, and supply chain management in transportation and logistics. Processing GPS, sensor, and previous transportation data enables delivery route optimization, fuel savings, and increased operational effectiveness.
Concluding Thoughts
Data preprocessing in machine learning is the process of preparing the raw data in the form to feed the data into the machine learning model. Precisely, the need for data preprocessing is there due to the following reasons:
- The data is more relevant depending on the nature of the business problem.
- It makes the data more reliable and accurate by removing the incorrect, missing, or negative values (based on the data domain).
- The data is also more complete after treating for the missing values.
- The data becomes more consistent by eliminating any data quality issues and inconsistencies present in the data.
- The data is in a format that a machine can parse.
- The features of the algorithm are much more interpretable. Readability and interpretability of the data improve.
You may also like to read: KNN Algorithm in Machine Learning
FAQs – Frequently Asked Questions
Q1. What is the difference between balanced and imbalanced classes?
The number of observations belonging to each class in a classification problem is similar in balanced data. When the number of observations belonging to each class is not equally distributed, it forms imbalanced data. In one class, the number of observations is significantly lower than in the other class.
Q2. Which is the correct sequence of data preprocessing?
The sequence of data preprocessing follows:
- Consolidation post-data acquisition
- Data Cleaning:
- Convert the data types if any mismatch is present in the data types of the variables
- Change the format of the date variable to the required format
- Replace the special characters and constants with the appropriate values
- Detection and treatment of missing values
- Treating for negative values, if any, present depending on the data
- Outlier detection and treatment
- Transformation of variables
- Creation of new derived variables
- Scale the numerical variables
- Encode the categorical variables
- Split the data into validation, training, and test set
Q2. What is data cleaning in machine learning?
Data cleaning in machine learning creates reliable data by identifying inaccurate, incorrect, and irrelevant data and removing these errors, duplicates, and unwanted data. The data present may also be spurious, with missing or negative values that can impact the model.
Q3. What is the key objective of data analysis?
The primary objective of data analysis is to find meaningful insights within the data to use to make well-informed and accurate decisions.
Q4. What is the difference between Scaling and Transformation?
| Scaling | Transformation | |
| Purpose | The goal is to compare the variables as scaled variables on the same band can be compared, increasing the computational power (or the efficiency). | Transformation helps in the case of skewed variables to reduce skewness. In the case of regression, if the assumptions of regression aren’t met or if the relationship between the target and independent variables is non-linear, we can use transformation to linearize. |
| Impact on Data | Scaling has no impact on the data. All the properties of the data remain the same—only the range of the independent variables changes. | Transformation changes the data, and so does the distribution of the data. |
| Impact on Skewness, Kurtosis, Outliers | As the distribution remains the same so no changes in skewness and kurtosis. Scaling doesn’t remove outliers. | Transformation can decrease the skewness. It brings values closer, which can remove the outliers. |
Q5. What is the difference between Standardization and Normalization?
Normalization and Standardization are scaling techniques. Standardization raises the data based on the Z-score, using the formula (x-mean)/standard deviation, reducing the data width from -3 to 3. Normalization scales the data using the formula (x – min)/(max-min) and Min-Max Scalar. It reduces the data width from 0 to 1.
Q6. What is the difference between Label Encoding and One-Hot Encoding?
| Label Encoding | One-Hot Encoding | |
| How is the categorical data treated? | Labels the data into numbers | Converts the data into dummy variables, i.e., binary having 1 or 0 as values. |
| Example | Male: 1 Female: 2 | Var_Male: 1 and 0 / Var_Female: 0 and 1 |
| How to use it in Python? | It can be used via the sklearn package’s function called LabelEncoder | Either sklearn’s function can create dummies: OneHotEncoder, or Python’s inbuilt function: pd.get_dummies |
| Limitations of the method | Changes the nominal data into ordinal making the values given to the categories as weights, hence the machine accordingly giving those values importance. | The method creates extra redundant columns for each category, generating a different column. This increases the dimensions of the data. |
| Solution available | Employ Dummy creation or One-Hot encoding technique | Use the various methods available for dimensionality reduction |
Q7. List the different feature transformation techniques.
The common feature transformation techniques are:
- Logarithmic transformation
- Exponential transformation
- Square Root Transformation
- Reciprocal transformation
- Box-cox transformation
Q8. What is the final output of data processing?
A cleaned and transformed dataset, insights and summaries, visualizations and reports, predictive models, and decision support are the end products of data processing.
Q9. What are data processing algorithms?
Algorithms used in data processing are computer methods and strategies for transforming, analyzing, and extracting information from data. They are made to handle various jobs, including data transformation, cleansing, aggregation, integration, filtering, analysis, and modeling.
Algorithms used in data processing include those used in sorting, filtering, grouping, regression analysis, and machine learning.
Q10. What is data processing?
Data processing involves manipulating, transforming, and analyzing raw data to extract meaningful insights. It uses techniques, algorithms, and tools to organize, cleanse, integrate, and analyze data, aiming to derive value from it.
Q11. Why is data processing important in machine learning?
Data processing is crucial in machine learning as it establishes the basis for precise and valuable insights. It involves converting raw data into a suitable format for analysis.
Q12. How is data processed using a computer? Explain.
The procedure involves transforming unprocessed data into a format that machines can understand. Then it directs the data through the CPU and memory to reach output devices and modify the output through formatting or transformation.
- Confusion Matrix in Machine Learning
- Fundamentals of Cost Function in Machine Learning
- Decision Tree Algorithm in Machine Learning
- List Of Popular Machine Learning Tools In 2023
- What is Clustering in Machine Learning?
- Blockchain and Machine Learning
- What Are the Important Topics in Machine Learning?






1 Comment
Great article about data preprocessing in machine learning.Thanks for this article.