Data science is credited with the inception of the fourth industrial revolution. It is one of the dominating concepts that is driving businesses across the globe. Data Science has given brands the power to analyze customer intents, market trends, and financial risks better than ever. And aiding to this, one of the hottest jobs in the market is Data Engineering – a role that requires an amalgamation of analysis and programming – and works closely with a data scientist. This article will act as a guide to data engineering interview questions and answers that can give you the edge in your next interview.
Data Engineering: Timeline Analysis
Like every other sector, the Data Science job market faced the brunt of the Covid-19 pandemic. The churn rate in the number of job openings and hiring grew steadily, bringing it to an all-time low in July 2020. The number of data science jobs fell by 17% during this time.
However, the pandemic paved the way for contactless transactions. Even the smallest vendor moved to UPI-based payment apps. All kinds of businesses moved online, aiming to leverage the new-found digitization trend.
As a result, data generation grew by terabytes and petabytes. As one thing leads to another, this change in the consumer-brand relationships created urgent requirements for data experts who can handle this raw unstructured data and derive business insights and patterns from them.
The demand for skilled data scientists increased by 56% by the end of the first quarter of 2020. By 2021, engineering and data scientists became the top job roles with the highest recruitment activities in India. Research shows that in April 2022, the demand for data scientists in India grew by 30.1%. As a result, India’s contribution to the global demand for data scientists grew to 11.6% in 2022 from 9.4% in 2021.
Hello, Data Engineers!
Data engineering is a field associated with a set of activities & tasks that enables organizations to capture data from various sources, process it, and make it ready for further use, such as Business Analytics, AI & Data Science Solutions, etc. Data Engineering is a superset of Enterprise Data Ware Housing & Business Intelligence, along with some elements of Software Engineering. This field integrates with a specialization around the ‘Big Data Distributed systems”, “Stream Processing,” and “Computation at Scale.”
Data Engineering Market Projection [Scope]
While the covid-19 pandemic slowed down the job market for a considerable time, the data science domain was one of the quickest to see steady growth post the pandemic. The pandemic, in a way, paved the way for the rise and dominance of the data engineering job role. The primary reasons for this were:
- Fast digitization of the world
- Steady ecosystem to train aspiring data engineers
- A pool of data to analyze
- Increases adoption of data-based solutions in companies, big and small
- Regular government initiatives to facilitate data centers
 Research states that India’s data Engineering market is currently valued at $18.2 billion (in 2022). This number is predicted to grow at a CAGR of 36.7% in another five years, touching $86.9 Billion by 2027 .
Research states that India’s data Engineering market is currently valued at $18.2 billion (in 2022). This number is predicted to grow at a CAGR of 36.7% in another five years, touching $86.9 Billion by 2027 . 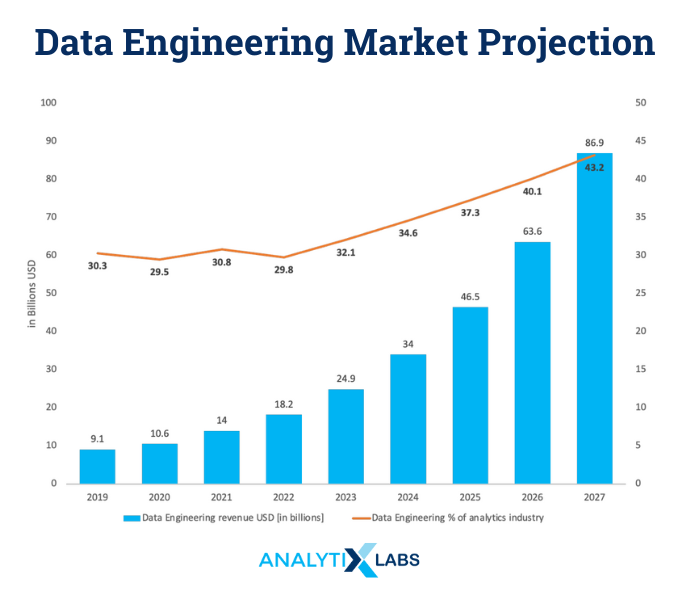 The demand for skilled data Engineers is growing by leaps and bounds, and there is no stopping. Every day new jobs are opening up for data engineers that you can apply for. While applying is part one, there are around 3-4 steps before you land the job. Here is an overview of what you can expect.
The demand for skilled data Engineers is growing by leaps and bounds, and there is no stopping. Every day new jobs are opening up for data engineers that you can apply for. While applying is part one, there are around 3-4 steps before you land the job. Here is an overview of what you can expect.
- You find an amazing opportunity, and you apply.
- Your resume goes through automated filtering before a recruiter reviews it. [Learn how to optimize your resume for automated systems].
- You receive an intimation from the recruitment team for a quick “chat” or a call [read Interview stage 1].
- You clear this round. Next, you will face a technical round where you can exhibit the skills and knowledge you have garnered through practical learning and experience.
- Last comes the HR round. Sometimes, you might go through an additional round where you interact with the CEO or any of the stakeholders in the company.
- Voila! You are now negotiating salary and other details about your role.
Data Engineering Interview Questions [with answers]
This cheatsheet will guide you to face the technical round like a pro . The first round usually is about your expectations from the role in question, why you have applied, and a general overview of your knowledge. Note: We have put together 31 questions that most recruiters, hiring managers, and CMO swear by when interviewing data engineers. These questions apply to newbies as well as senior data engineers. Let’s get started.
1. Do you think Data engineers and Data Scientists are same?
What you can say: Not really. Data Scientists are the ones who build and train predictive models with data that is cleaned and analyzed. On the other hand, data engineers maintain the system for data scientists to access and interpret data.
2. Do you know anything about data modeling?
What you can say: Yes. To start, data modeling is different from predictive modeling. Data modeling visually defines the various datasets available to the organization, their structure, type, format, and their relationship with each other. The whole process is done under the backdrop of the business requirements of the stakeholder. This is an essential aspect of data engineering as this helps you and others to classify and arrange a vast amount of data.
3. What is the Standard Design Scheme in Data Modeling?
What you can say: There is two main design schema used in data modeling:
- Star Schema
- Snowflake Schema
Also Read: Structured Data In Big Data
4. What is difference between Structured and Unstructured dataset?
What you can say:
| Structured Data | Unstructured Data |
|---|---|
| Stored in database management systems (DBMS) | Stored in an unmanaged file structure |
| Less flexible because it is dependent on Schema | Flexible in nature |
| Difficult to scale | Easy to scale |
| Easy to analyze | Hard to analyze |
| High performance since structured query can be performed | Low performance |
5. What are the critical skills that you have for this job role?
What you can say: —> Newbies: From my practical learning and industry projects, the skills that I have for this job role include:
- Knowledge of Mathematics (especially probability and linear algebra)
- Statistics (inferential as well as descriptive)
- Machine Learning
—> Experienced Professionals: From my experience, I think for this role specifically, the skills I have are [include the ones mentioned above along with additional skills that you have mastered while working]. Note: This data engineering interview question does not require you to say a set specific answer. It is a way to see your skills, whether you understand the core responsibility of being a data engineer, and how much you are willing to learn.
6. What tools and frameworks are used by data engineers?
This is another data engineering interview question with similar intent as the last one. What you can say: The standard tools include Hadoop, SQL, Python, etc. Note: Review the job descriptions properly before you sit for an interview. Every job description has a “requirement” section that mentions tools they expect the candidate to know. Make sure you don’t miss out on those. While the ones mentioned above are standard tools, sometimes a job may require a special addition. For instance, here’s an overview of:
- Demand for key tools by experience(%)
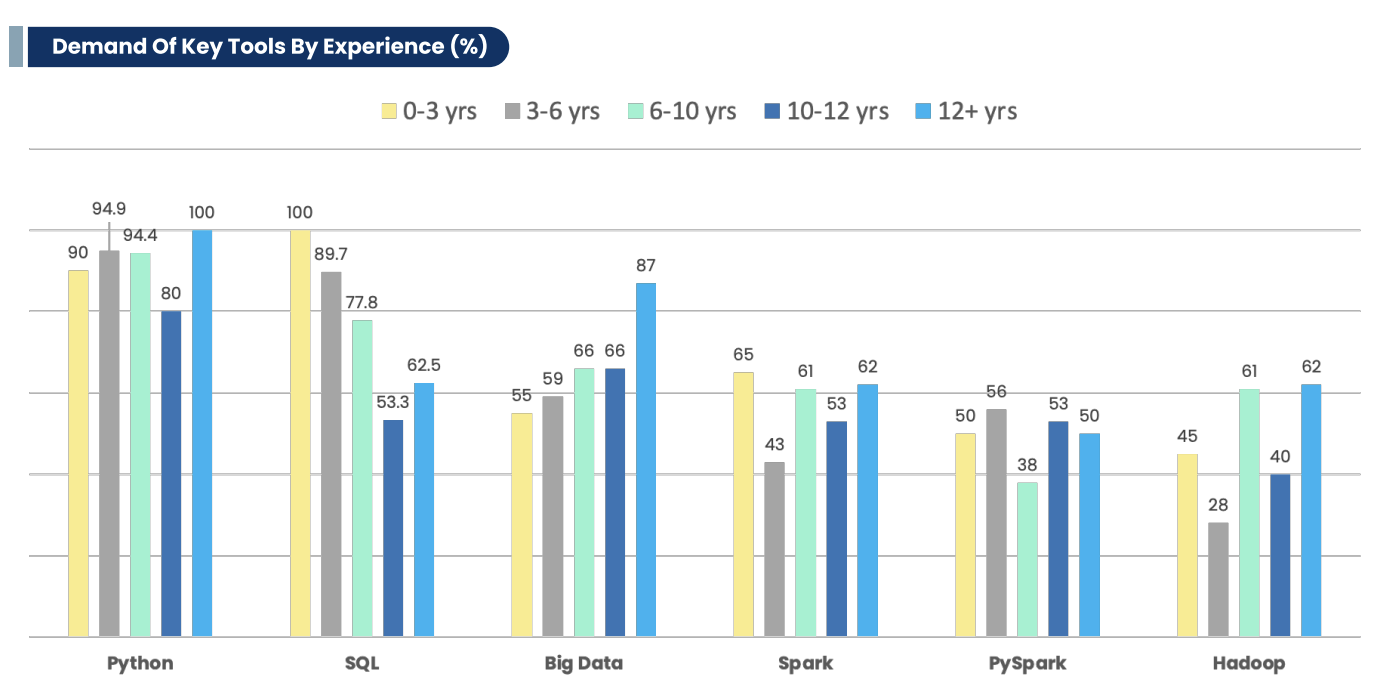
7. Do you know about Big Data and its four V’s?
What you can say: Big Data refers to the significant amounts of data that may or may not be structured and requires a non-traditional process for storing and managing it. The Four V’s are: Volume, Veracity, Velocity, and Variety.
Read more on Big Data Architecture
8. What is Hadoop? What is it’s main feature?
What you can say: Hadoop is open-source software that allows big data management using a network of machines (computers). Its main features are
- It is open source
- Can be easily scaled
- Provides easy and faster data processing
9. What are the significant components of Hadoop?
Data engineering interview questions will always include questions on Hadoop. So, exploring Hadoop well before you sit for the interview is a good idea. What you can say:
- Hadoop common: The basic libraries used by the Hadoop system
- HDFS: It is the distributed file system Hadoop uses to store data
- Hadoop MapReduce: It allows data processing of big data
- Hadoop YARN: It enables the management of the resource in Hadoop clusters
Also Read: How to Learn Hadoop? Beginner’s Guide.
10. You mentioned HDFS. Can you explain what it is in a little more detail?
What you can say: HDFS, aka. Hadoop Distributed File System is the data storage mechanism used by Hadoop. It allows data transfer between computers by breaking data into smaller chunks and distributing them to different nodes. Two types of nodes are involved in HDFS- NameNode that can be only one and DataNode that can be many.
11. Explain NameNode of HDFS.
A common pattern in any senior data engineer interview questions is to form a question from your previous answer. This is common to all interviews in most cases. What you can say:
- NameNode is responsible for storing vital metadata about data nodes and helps in keeping track of all the clusters.
- NameNode receives Block Report and Heartbeat, the two types of messages from the data node.
Learn more about NameNode here.
12. How does NameNode interact with DataNode?
What you can say: As I mentioned just now – Namenode interacts with the data node by sending reports (as seen above) or through a mechanism of heartbeat that is a signal to confirm if the data node is still operational.
The next question is more advanced and mostly falls under senior data engineer interview questions. Infact, all questions from here on are for senior data engineers. However, a few apply to juniors and new data engineers, depending on the job responsibilities.
Data engineering interview questions can also be framed around the possible scenarios you might face daily.
13. What is Block and Block Scanner?
What you can say: The block is the smallest unit in the Hadoop ecosystem. When Hadoop receives data, the data is stored in smaller chunks known as blocks. The concept of a block scanner comes into play to verify the blocks presented on a DataNode. For example, suppose the block scanner identifies a corrupt data block. In that case, the DataNode sends a report to the NameNode, and Namenode, in turn, creates a new replica of the corrupted block.
14. What is COSHH?
What you can say: To positively impact the timeline of task completion, scheduling is done at the cluster and application levels. This process is known as Classification and Optimization-based Scheduling for Heterogeneous Hadoop Systems (COSHH).
15. What do you know about Star Schema and SnowFlake Schema?
What you can say:
- The most basic data warehouse schema is known as the star schema. The name comes to form the shape of the schema, wherein at the center lies a fact table and other associated tables around it enabling querying of big data.
- An extension of the above-mentioned star schema, the snowflake schema looks like a snowflake as it further creates additional data by splitting data.
The most significant difference between the star and snowflake schema is that star has high chances of redundancy, is less complex, and thereby is faster. Snowflake, on the other hand, has fewer chances of redundancy but is more complex and consequently slow.
16. Do you anything about FSCK?
What you can say: Yes. The FSCK command stands for File System Check and is used to check file problems and inconsistencies.
Read about more commands in Hadoop like FSCK.
17. What is Rack Awareness?
What you can say: Rack Awareness is a concept where rack-id is assigned to each data node and name node for better network traffic and by reading and writing files to the closest rack.
18. What is Apache Spark? How do you think it is different from MapReduce?
What you can say: Apache Spark is a general-purpose, open-source data processing engine that performs distributed processing for dealing with big data. The most significant difference between Apache Spark and MapReduce is that while spark is faster as it retains data in the memory for prolonged use, MapReduce works on the disk and is not limited by the memory issue but is slower compared to apache spark.
19. Do you know about YARN?
What you can say: Yes. YARN is an abbreviation for Yet Another Resource Negotiator – one who is responsible for resource management in Hadoop.
20. What is HIVE? What is its use in Hadoop?
What you can say: Hive is an essential data warehouse system that allows users to use SQL commands to read, write and manage big data.
21. What are Skewed tables in Hive?
Among the common senior data engineer interview questions is the examination of the concept of skewed tables. What you can say: If in a table’s column some values appear frequently, then the data is considered ‘skewed‘. Hive stores such skewed values in a separate table when a user opts for the skewed option while creating a hive table. This allows for increased efficiency.
22. What are the data structures supported by Hive?
What you can say: The common data structures in Hive are array, map, struct, and union.
23. What is Metastore?
What you can say: In Hive, metadata information such as definitions, mappings, etc., are stored in metastore that can later be stored in an RDBMS.
24. What is data pipeline?
A data engineer interview cannot be without question on pipeline as it is one of the most critical tasks a data engineer performs.
What you can say: In simple terms, a data pipeline refers to the process of moving data from one place (usually the source) to the other (typically a data warehouse). However, it’s more complex than that because the data is transformed and optimized during the transportation so that it is in a productive state once it reaches its designation.
25. Why do you want to work in a cloud computing environment?
The data engineer interview questions can also be centered around cloud computing as most organizations use cloud computing to park their data; therefore, you must know why cloud computing is essential.
What you can say: In the present time, most companies prefer cloud computing to store their data. Its safer and easier to access. Other prominent reasons would be – flexibility, scalability, mobility, and ease of risk-free access to data from any location.
26. How do you deal with duplicate observations using SQL?
Whether its the junior or senior data engineer interview questions, SQL is often asked, and you must prepare for the same. What you can say: I can do this by using DISTINCT or UNIQUE keywords, combined with GROUPBY in some instances, and identify duplicates.
Also Read: Why Learn SQL?
27. How Python enables data engineers?
Among the data engineer technical interview questions can be questions related to python. While we won’t go into detail about python in this article, the common question that can be asked from you is about the python libraries and how data engineers use them.
What you can say: Libraries like NumPy can help in data processing, whereas pandas and scipy can be used for statistical analysis and data preparation.
Additional resources to refer:
28. What is Orchestration?
What you can say: As the IT department has become complex, so has the need to monitor and maintain the servers and applications. Therefore, IT departments have introduced automation in the configuration, and management of systems and applications, and this process is called orchestration.
29. How will you validate data?
When answering data engineering interview questions, you must remember the end goal of being a data engineer, i.e., to provide quality data to the stakeholders. Therefore it becomes necessary to validate data.
What you can say: There are multiple ways to validate data, such as checking data type, for range and outliers, for formats (especially for dates), and for data consistency and uniqueness check (to deal with duplicates and data redundancy).
30. What tools have you used in your recent projects related to data engineering or big data in general?
Among all the data engineer technical interview questions, you can be asked to explain your recent project involving data engineering or big data. Here you must present your projects, the tools used by you, the issues you faced, and how you resolved them. This is very important because practical knowledge is of utmost importance at the end of the day. What you can say: In my last project, my objective was to [explain the goal]. So, I did this – [explain the process you followed] using tools like [name the tools mostly used].
You can talk about more projects that prominently show how you can handle simple as well as complicated projects. Mention how you worked with a team and what were your contributions leading to the final result. Also, make sure to talk about the timeline in which you completed the project. This will help your hiring manager understand not just your skills but how agile you can be as a resource.
For instance, here’s an overview of the skills in demand: 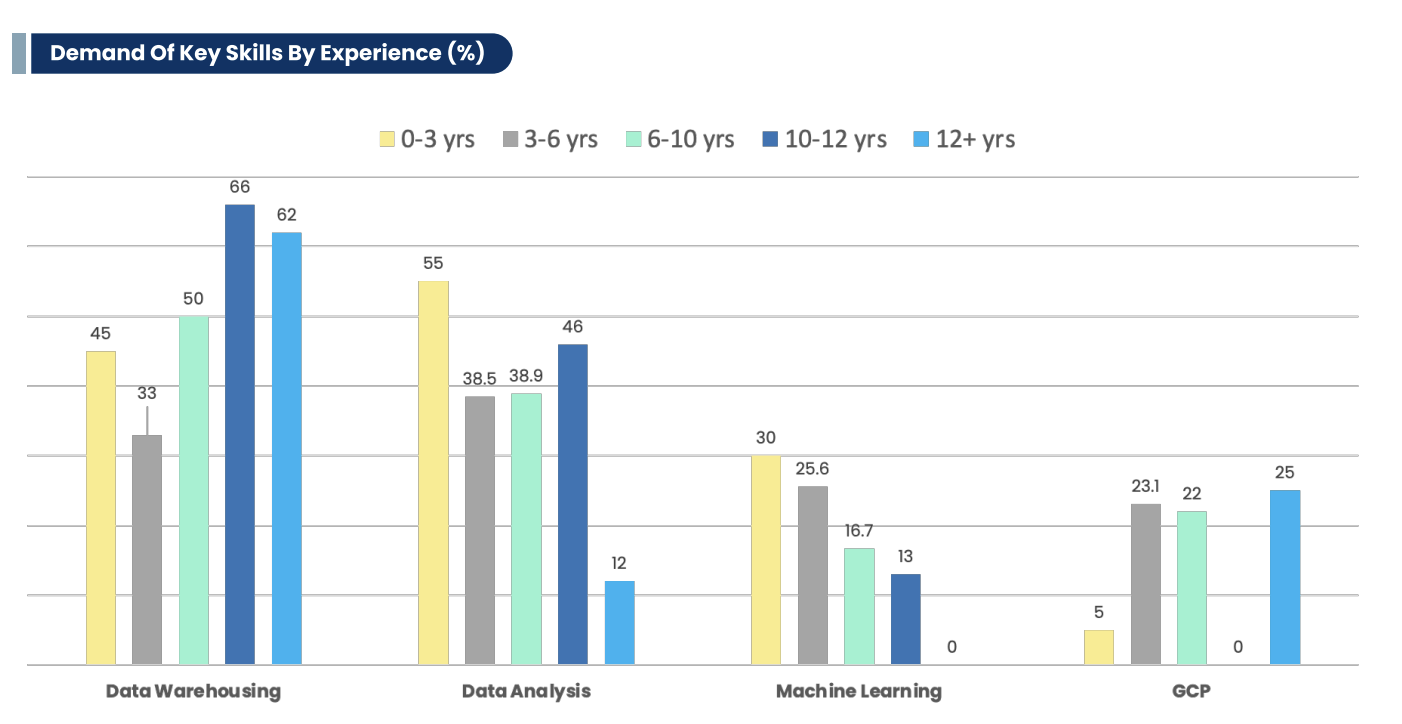
Pointers to Note:
- Data Engineers work primarily with Python (92%), SQL (82%)and Big Data (63%).
- In cloud technologies, data engineers work more with Azure or AWS as compared to Google Cloud Platform (GCP).
- Demand for Python remains almost 100% as data engineers progress in experience.
- Demand for SQL reduces as experience grows.
- Around 55% of Data Engineer beginners can work with Big data. The number goes up as experience increases to 87% for professionals with over 12 years of experience
31. Your take on Database vs. Data warehouse?
What you can say: A common confusion that beginners make is mixing up databases and data warehouses. Database deals with data manipulation, whereas data warehouse deals with selecting subsets of data.
More details on database vs. data warehouse vs. data lakes
This brings us to the end of the top data engineer interview questions. These are the most commonly asked questions and are worth taking note of before an interview, especially the Technical Rounds.
Preparing for other interviews in the domain? We have other blogs in the Interview Question Series for you:
- Top 50 Data Science Interview Q/A
- Top 40 Data Analyst Interview Q/A
- Top 60 AI Interview Q/A
- Top 40 Deep Learning Interview Q/A
- Top 35 BA Interview Q/A
- Top 30 Data Warehouse Interview Q/A
- Top 50 Excel Interview Q/A
- Top Puzzle Questions Asked in BA Interview
- Top 50 Python Interview Questions
Now, let’s take a look at the salary structure for Data Engineering job role in India. This will help you in your last step – negotiating your pay as per the industry standards.
Data Engineering: Pay Scale in India
The Data engineering ecosystem is gaining momentum for its role in driving business decisions. As a result, companies have opened doors to novice and experienced data engineers with lucrative packages and retention models.
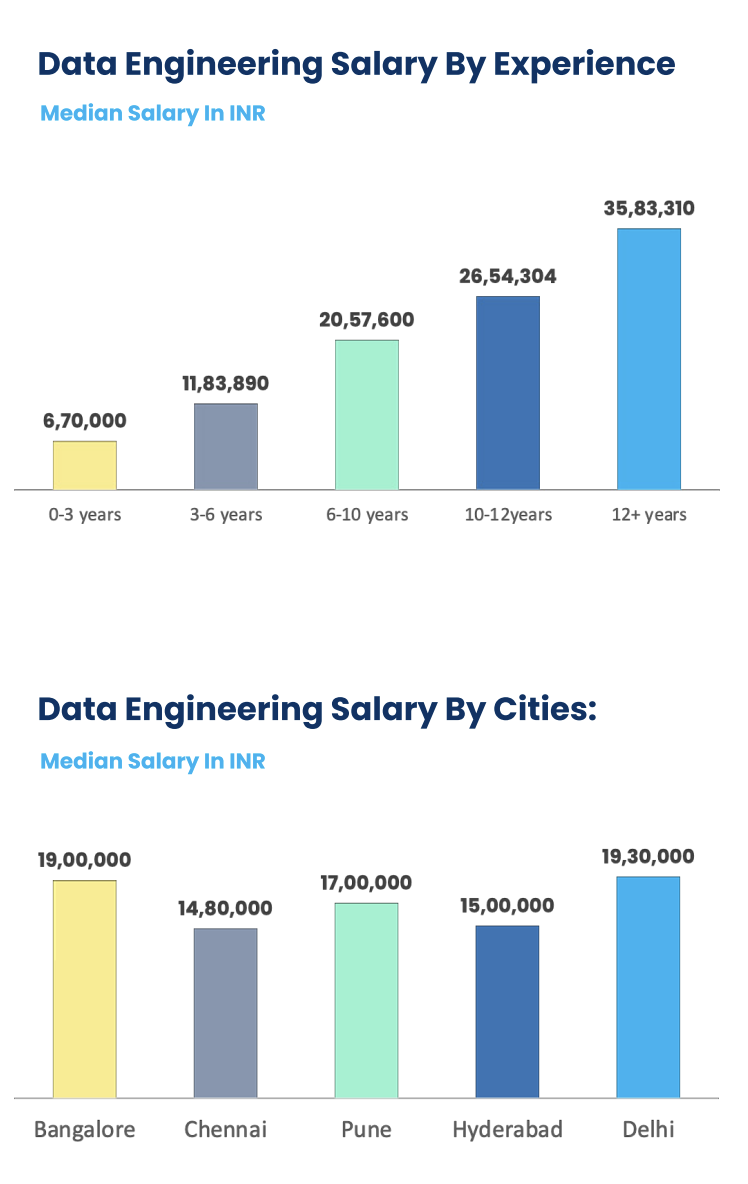
Data Engineering Salary by Experience & City:
- Data Engineers in the Delhi NCR region are the highest paid at 19.3Lakhs/annum.
- Despite the high living cost in Mumbai, Data Engineers’ average salary bracket is just 50,000 higher than that of Pune.
- Hyderabad and Chennai offer the lowest salary at 15L/annum and 14.8L/annum.
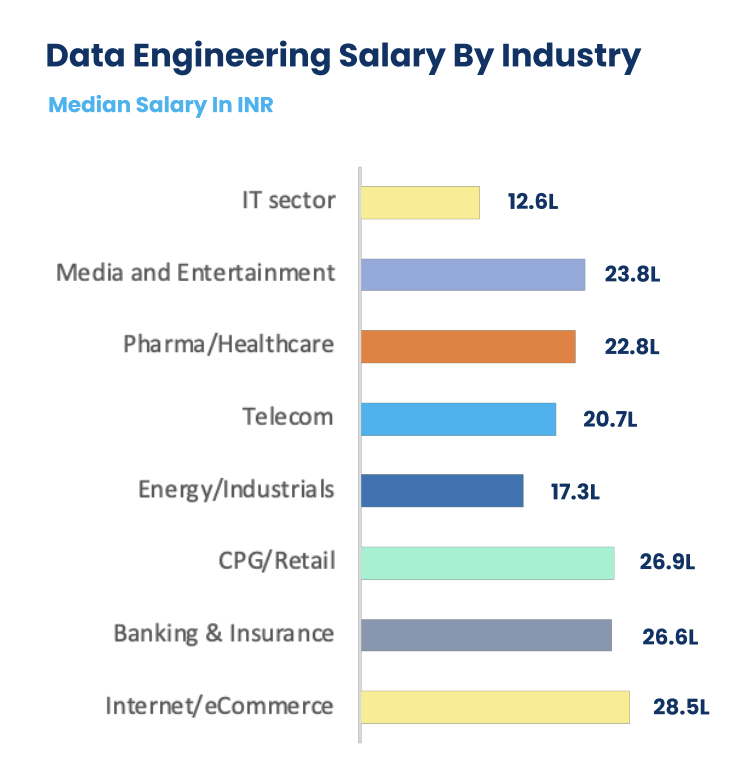
Data Engineering Salary by Industry:
- Data Engineers in the Internet/eCommerce sector earn the highest at INR 28.5L/annum.
- Data Engineers in Internet/eCommerce have 2.3 times higher salaries than data engineers in the IT sector. This is because the IT sector is more populated with “engineers”.
- Traditional industries like Energy/Industrials have an even lower pay range of 17.3L/annum.
 And that is a wrap! Wishing you good luck for your interview preparations and the interview.
And that is a wrap! Wishing you good luck for your interview preparations and the interview.