The most lucrative and pursued field today is Data Science. It is undoubtedly here to stay for many years to come, as it is estimated that by 2025, 463 exabytes of data will be generated every day globally! With this much data generated daily, there will certainly be a demand for skilled people to understand this data, leverage this data, and drive meaningful insights. If we want to step into this field, we need specific skills for it.
Of all the skills needed to be a data scientist, having at least one programming language is minimum. The most sought-after programming language for a data science job is Python. Python is so popular because it is open-source, easily interpretable, and similar to writing in English.
We will look at what all topics come under data science, and the heart of this article lies in the important python interview questions for data science. I have divided the python interview questions for data science based on their utility: general python interview questions, Pandas, and Data Visualization questions. These are equally important and fall under the Data Science interview questions as well. The questions are not ordered.
AnalytixLabs, India’s top-ranked AI & Data Science Institute, is led by a team of IIM, IIT, ISB, and McKinsey alumni. The institute provides a wide range of data analytics courses inclusive of detailed project work, which helps an individual fit for the professional roles in AI, Data Science, and Data Engineering. With its decade of experience in providing meticulous, practical, and tailored learning, AnalytixLabs has proficiency in making aspirants “industry-ready” professionals.
Introduction to the Wide Range of Data Science Topics
The sky is literally the limit when it comes to data science. Based on your interest, you can go as much in-depth and learn as much as you want. Having said that, some broad areas are part of every data science job. We’ll look at an overview of these topics here; for a detailed explanation, you may refer to the article on What is the syllabus of Data Science?
The topics under data science essentially include Data Analysis, Data Munging, Data Visualization, Statistics, Programming, Machine Learning.
-
Data Analysis and Data Munging: Data Analysis is the process of transforming data to discover meaningful insights to derive a conclusion or make a decision. Data Munging is to clean the raw data, uncover the hidden patterns within the data and make the data ready for further analysis.
-
Data Visualization: This step is needed to graphically illustrate how the data is described. With the help of charts, tables, images and graphs one can present the data visually.
-
Statistics: Having processed and cleaned the data, we need some tools to understand how the data is, the various columns are related to each other, that’s where the Statistics comes in play. Check this out to learn about Basic Statstics Concepts for Data Science.
-
Programming: As said earlier, one basic programming language is a must to know to be in the field of data science. The reason programming language is must is because given the nature of the data available, and where the data is increasing at a lightning speed as each day progresses. It is imperative to have that can not only entail such data but also process it fast.
-
Machine Learning: Machine learning is the branch of Artificial Intelligence, where a machine learns by itself that is by making its own mistake without being explicitly programmed. There are broadly three types of Learning under machine learning: Supervised, Semi-Supervised and Unsupervised. Each type of learning focuses on different business objectives and has various algorithms under each that can be used to solve these business problems.
Let’s see what some of the important python interview questions are:
Python Interview Questions for Data Science
Q2.1. Is Python an object-oriented language? What is object-oriented programming?
Yes, Python is an object-oriented programming language meaning it can enclose the codes within the objects. The property allows the storage of the data and the method in a single unit called the object.
Q2.2. What is a Python module? How is it different from libraries?
A module is a single file (or files) containing functions, definitions, and variables designed to do certain tasks. It is a .py extension file. It can be imported at any time during a session and needs to be imported only once. To import a python module, there are two ways: import or from module_name import.
A library is a collection of reusable functionality of codes that allows us to perform a variety of tasks without having to write the code. A Python library does not have any specific context to it. It loosely refers to a collection of modules. These codes can be used by importing the library and by calling that library’s method (or attribute) with a period(.).
Q2.3. What is PEP8?
PEP 8 is coding convection. It consists of coding guidelines that are a set of recommendations for Python language about making the Python more readable and usable for another person.
Q2.4. Name mutable and immutable objects.
The mutability of a data structure is the ability to change the portion of the data structure without having to recreate it. Mutable objects are lists, sets, values in a dictionary.
Immutability is the state of the data structure that cannot be changed after its creation. Immutable objects are integers, strings, float, bool, tuples, keys of a dictionary.
Q2.5. What are compound data types and data structures?
The data type that is constructed using simple, primitive, and basic data types are compound data types. Data Structures in Python allow us to store multiple observations. These are lists, tuples, sets, and dictionaries.
Q2.6. What is the difference between a list and a tuple?
List:
- Lists are enclosed with in square []
- Lists are mutable, that is their elements and size can be changed.
- Lists are slower than tuples.
- Example: [‘A’, 1, ‘i’]
Tuple:
- Tuples are enclosed in parentheses ()
- Tuples are immutable i.e cannot be edited.
- Tuples are faster than lists.
- Tuples must be used when the order of the elements of a sequence matters.
- Example: (‘Twenty’, 20, ‘XX’)
Q2.7. What are list and dictionary comprehension? Give an example of each.
- Python comprehensions are syntactic constructs providing a way to build a list, dictionary or set based on the existing list, dictionary or set whilst altering or filtering elements.
- These are generally more compact and faster than normal functions and loops for creating lists.
- Must avoid writing very long comprehensions in one line to ensure that code is user-friendly and to maintain the readability.
Example of List comprehension:
[i for i in range(10,60) if i% 10 == 0]
Output: 10,20,30,40, 50
Example of dictionary comprehension:
keys = [‘i’, ‘ii’ ,’iii’, ‘iv’]
values = [‘this’,’month’,’is’,’March’]
d = {i:j for (i,j) in zip(keys, values)}
print (d)
Output: {‘i’: ‘this’, ‘ii’: ‘month’, ‘iii’: ‘is’, ‘iv’: ‘March’}
Q2.8. What is tuple unpacking? Why is it important?
A tuple can be unpacked in sense its elements can be separated in the following manner:
Example: We have tuple x = (500, 352)
This tuple x can be assigned to two new variables in this way: a,b = x
Now, printing a and b will result in: print(a) = 500 and print(b) = 352
Tuple unpacking helps to separate each value one at a time. In Machine Learning algorithms, we usually get output as a tuple. Let’s say x = (avg, max), and we want to use these values separately for further analysis then can use the unpacking feature of tuples.
Q2.9. What are generators and decorators?
A generator is a function returning an iterable or object over which can iterate that is by taking one value at a time. A decorator allows us to modify or alter the functions, methods, and classes.
Q2.10. What is the difference between %, /, and //?
% is the modulus operator that returns a remainder after the division.
/ is the operator that returns the quotient after the division.
// is the floor division that rounds off the quotient to the bottom.
Example:
11 % 2 —> output = 1
11 / 2 —> output = 5.5
11 // 2 —> output = 5
Q2.11. What is the difference between is and ‘==’ ?
‘==’ checks for equality between the variables, and ‘is’ checks for the identity of the variables.
Q2.12. What is the difference between indexing and slicing?
Indexing is extracting or lookup one or particular values in a data structure, whereas slicing retrieves a sequence of elements.
Q2.13. What is the lambda function?
- Lambda functions are an anonymous or nameless function.
- These functions are called anonymous because they are not declared in the standard manner by using the def keyword. It doesn’t require the return keyword as well. These are implicit in the function.
- The function can have any number of parameters but can have just one statement and return just one value in the form of an expression. They cannot contain commands or multiple expressions.
- An anonymous function cannot be a direct call to print because lambda requires an expression.
- Lambda functions have their own local namespace and cannot access variables other than those in their parameter list and those in the global namespace.
Example: x = lambda i,j: i+j
print(x(7,8))
Output: 15
Q2.14. Explain zip() and enumerate() function.
The zip() function takes multiple lists as input and creates those into a single list of tuples. It does so by taking the corresponding elements of each of the lists as a parameter. It continues this process until it finds the pairs of the tuples.
Example: We have two lists:
l1 = [‘A’, ‘B’,’C’,’D’] and l2 = [50,100, 150, 200].
zip(list1, list2)
Output: A list of four tuples: [(‘A’,50), (‘B’,100), (’C’,150), (’D’,200)]
In case the length of the lists is not the same, then the zip() function will not generate the tuples once the list with the shooter length ends.
The enumerate() function also takes a list as input and creates a list of tuples. However, its output is: the first element of the tuple is the position of that element in the list and the second element of the tuple is the actual value of the element in the list.
In short, enumerate() function assigns an index to each item in an iterable object that can be used to reference the item later. It makes it easier to keep track of the content of an iterable object. It returns (position, value). It can only take one list at a time as an input as it takes the position of all the elements.
Example:
list2 = [“apple”,”ball”,”cat”]
e1 = enumerate(list2)
print(e1)
Output: [(0, ‘apple’), (1, ball’), (2, ‘cat’)]
Q2.15. How do map, reduce and filter functions work?
Map function applies the given function to all the iterable and returns a new modified list. It applies the same function to each element of a sequence.
Reduce function applies the same operation to items of a sequence. It uses the result of operations as the first param of the next operation. It returns an item and not a list.
Filter function filters an item out of a sequence. It is used to filter the given iterable (list, sets, tuple) with the help of another function passed as an argument to test all the elements to be true or false. Its output is a filtered list.
Q2.16. What is the difference between del(), clear(), remove(), and pop()?
- del(): deletes the with respect to the position of the value. It does not return which value is deleted. It also changes the index towards the right by decreasing one value. It can also be used to delete the entire data structure.
- clear(): clears the list.
- remove(): it deletes with respect to the value hence can be used if you know which particular value to delete.
- pop(): by default removes the last element and also returns back which value is deleted. It is used extensively when we would want to create referencing. In sense, we can store this deleted return value in a variable and use in future.
Q2.17. What is the difference between range, xrange, and range?
range(): returns a Python list object, which is of integers. It is a function of BASE python.
xrange(): returns a range object.
arange(): is a function in Numpy library. It can return fractional values as well.
Q2.18. What is the difference between pass, continue and break?
Pass: It is used when you need some block of code syntactically, but you want to skip its execution. This is basically a null operation. Nothing happens when this is executed.
Continue: It allows to skip some part of a loop when some specific condition is met, and the control is transferred to the beginning of the loop. The loop does not terminate but continues with the next iteration.
Break: It allows the loop to terminate when some condition is met, and the control of the program flows to the statement immediately after the body of the loop. If the break statement is inside a nested loop (the loop inside another loop), then the break statement will terminate the innermost loop.
Q2.19. What is Regex? List some of the important Regex functions in Python.
Regular Expression or RegEx is a sequence of characters that are used to create search patterns. In Python, the following RegEx functions are mostly used:
- match(): it checks for a match only at the beginning of the string.
- search(): it locates a substring matching the RegEx pattern anywhere in the string
- sub(): searches for the pattern and replaces with a new value
- split(): it is used to split the text by the given RegEx pattern.
- findall(): it is used to find all the sub-strings matching the RegEx pattern
Q2.20. What are namespaces in Python?
A namespace is a naming system that is used to ensure that every object has a unique name. It is like space (for visual purposes, think of this space as a container) is assigned to every variable which is mapped to the object. So, when we call out this variable, this assigned space or container is searched and hence the corresponding object as well. Python maintains a dictionary for this purpose.
Q2.21. What is the difference between global and local variables?
Global variables are the ones that are defined and declared outside a function, and we need to use them inside a function. A variable declared inside the function’s body or the local scope is known as a local variable.
Q2.22. What is a default value?
Default argument means the function will take the default parameter value if the user has not given any predefined parameter value.
Q2.23. What does *args, **kwargs mean? When are these used?
*args and *kwargs are keywords that allow a function to take the variable-length argument.
*args:
- It is used to pass a variable number of arguments to a function
- It reads the value one by one and prints the value
- It is used when we are not sure of how many arguments will be passed to a function.
- The symbol * is used to indicate to take in a variable number of arguments
*kwargs:
- It is used to pass a keyworded, variable-length argument list
- It is used when we do not know how many keyword arguments to be passed to a function
- The symbol ** is to indicate pass through keyword argument
- This helps to unpack a dictionary
Q2.24. What is the difference between print and return?
The print does not store any value. It simply prints the value, whereas return gives the value as an output that can be stored in a variable or a data structure.
Q2.25. What is the use of the With statement?
With statement helps in exception handling and also in processing the files when used with an open file. Using this way:
with open(“filename,” “mode”) as file_name:
We can open and process the file, and we do not need to close the file explicitly. Post the with block exists., then the file object is closed. The With statement is resourceful and ensures that the file stream process is not stopped, and in case an exception is raised, it ends properly.
Q2.26. What is the difference between conditionals and control flows?
Conditionals are a set of rules performed if certain conditions are met. The purpose of the conditional flow is to control the execution of a block of code if the statement’s criteria match or not. These are also referred to as ternary operators. These single-line if-else statements consist of true-false as outputs on evaluating a statement.
Control Flows are the order in which the code is executed. In Python, the control flow is regulated by conditional statements, loops, and call functions.
Q2.27. How is exception handling achieved in Python?
With the help of exception handling, we can prevent the breaking of codes if an error is faced during the run time of the code. In Python, can implement the exception handling using two keywords: try and except.
Try tries to execute the code that belongs to it.
Except is used after the try block and catches all the specific errors which would appear on running the codes under the try block.
Except
For example: adding an integer with a string is not possible. How would exception handling work in such a scenario is:
try:
a = 9 + ‘Alphabet’
except:
a = 40
print(a)
This will give the output of 40.
If had only given the command as:
a = 9 + ‘Alphabet’
print(a)
Then, Python would return the TypeError: unsupported operand type(s) for +: ‘int’ and ‘str’
Q2.28. When to use for loop and while loop?
For loop is used when you know beforehand which elements need to be iterated. If you want to iterate over every element of the data structure, then use For loop. On the other hand, the While loop is used to check for some conditions on the variables. Here, we know the exact condition to run but do not know how many times to run the loop.
Q2.29. What is a class and object?
A class is a user-defined prototype which basically is a blueprint that defines the nature of a future object. An object is an instance of the class. Therefore, classes can construct instances of objects. This is known as instantiation.
Q2.30. What is a docstring?
Python document strings (or docstrings) describe what the function does. These are within the triple quotes. Also, it can be accessed using two ways: one via __doc__ attribute and via by adding a period (.) next to the function name and pressing tab. It is a way to associate documentation with Python modules, functions, classes, and methods.
Pandas and Visualization
Q3.1. What is the difference between series and vectors?
Vectors: It can only assign index positions values as 0,1,…, (n-1).
Series: It has only one column. It can assign custom index positions values that are for each and every data series. Examples: cust_ID, cust_name, sales. Series can be created from the list, array, dictionaries.
Q3.2. What is the difference between data frames and matrices?
| Data Frames | Matrices |
|---|---|
| Data frames are a collection of series that share a common index. | A matrix in Numpy is constructed with multiple vectors. |
| It can hold multiple series, which are of different data types. | It can hold only one data type in the entire two-dimensional structure. |
| For example, the customer data has various columns as cust_id, customer_name, age, gender, sales. These are each individually a series that is of a different data type. |
Q3.3. What is the difference between lists and arrays?
An array is a data structure that contains a group of elements where the elements are of the same data type, e.g., integer, string. The array elements share the same variable name, but each element has its own unique index number or key. The purpose is to organize the data so that the related set of values can be easily sorted or searched.
Q3.4. What is the difference between .iloc and .loc?
| .iloc | .loc |
|---|---|
| It is referred to as the internal index: 0,1,2…, (n-1). | It is referred to as the external, labeled, or custom index. |
| It is only for the indexes. | It is only for the labels. |
| Example: stores.iloc[0:9] will return the rows with 0,1,2,3,4,5,6,7,8 as the indices. | Example: stores.loc[0:9] will return the rows with 0,1,2,3,4,5,6,7,8,9 as the indices. |
| It works in the same manner as Python’s range function works; that is, the last element is not included. | Here, the upper bound is included. |
Q3.5. What is the difference between merge, join and concatenate?
Merge is used to merge the data frames using the unique column identifier. By default, the merge happens on an inner that is the intersection of all the elements. Syntax: pd.merge(df1, df2, ‘outer’, on=’custId’)
Join is used to join the data frames using the unique index. The left join is the default which means it takes all the exclusive ids of the data frame that exists on the left table. It will return all the indexes on the left side of the table and NaN for the corresponding values that don’t exist on the right table. Syntax: df1.join(df2)
Concatenate: It joins the data frames basically either by rows or columns. Syntax: pd.concat(df1,df2)
Q3.6. What is the apply() function?
apply() function is vital and comes in handy to apply on data frames and series. It can be applied to each and every value of the Pandas series and data frames. The process of how the apply() function works on a column and ensures that it is still present in a dataframe and iterated in a loop for all the remaining columns.t can be used for both in-built and user-defined functions. It can also be with lambda functions. Example: df.apply (lambda x: x**2)
Q3.7. When do we use crosstab and pivot_table?
CrossTab:
- The crosstab function can operate on Numpy arrays, series or columns in a dataframe.
- Pandas does that work behind the scenes to count how many occurrences there are of each combination.
- Why even use a crosstab function? The short answer is that it provides a couple of handy functions to more easily format and summarize the data.
- CrossTab values won’t work unless aggfunc is explicitly mentioned and vice-versa.
- gives ValueError: values cannot be used without an aggfunc. | aggfunc cannot be used without values.
- The syntax for CrossTab only allows:
- pd.crosstab(index=df[],columns=df[],values=df[], aggfunc=)
In Pivot_Table:
- If don’t give explicitly values to pivot table then by default it takes ALL the numeric columns as values
- Average is by default operation that pivot table works on
- aggfunc automatically works without even mentioning the values in the values argument and can be used without explicitly passing values.
- The syntax for Pivot_Table follows both:
- Using -> df.pivot_table(index=[],columns=[],values=[]) and
- pd.pivot_table(df, index=[],columns=[],values=[])
Q3.8. How do you use groupby?
Groupby allows to group rows together based on a column and performs the aggregate function on those combined rows. Example: df.groupby(‘Company’).mean()
Q3.9. What are ways to reshape a pandas dataframe?
There are three ways of reshaping the dataframe:
- stack(): reshaping via stack() converts the data into stacked form that is the columns are stacked row wise.
- unstack(): is reverse of stacking. This function is used to unstack the row to columns.
- melt(): The function is used to manage the data frame into a format where one or more columns are identifier variables.
Q3.10. What is the difference between duplicated and drop_duplicates?
Duplicated checks if the records are duplicates or not. It results in True or False. False indicates that there is no duplication. Drop_duplicates drops duplicate by a column name.
Q3.11. Which all Python libraries have you used for visualization?
Matplotlib: It is the standard data visualization library useful to generate two-dimensional graphs. It helps plot histograms, pie charts, bar or column graphs, scatterplots, and non-Cartesian coordinates graphs. Many libraries are built on top of Matplotlib, and its functions are used in the backend. Also, it is extensively used to create the axes and the layout for plotting.
Seaborn: Based on Matplotlib, Seaborn is a data visualization library in Python. It works really well for Numpy and Pandas. It provides a high-level interface for drawing attractive and informative statistical graphics.
Q3.12. List some of the categorical, distribution plots.
Distribution Plots:
- displot: Figure-level interface for drawing distribution plots onto a FacetGrid.
- histplot: Plots univariate or bivariate histograms to show distributions of datasets.
- kdeplot: Plots univariate or bivariate distributions using kernel density estimation.
Categorical Plots:
- Catplot: Figure-level interface for drawing categorical plots onto a FacetGrid.
- Stripplot: Draws a scatter plot where one variable is categorical.
- Swarmplot: Plots a categorical scatter plot with non-overlapping points
- Boxplot: Plots a box plot to show distributions with respect to categories.
- Violinplot: Plots a combination of boxplot and kernel density estimate.
- Boxenplot: Draws an enhanced box plot for larger datasets.
- Pointplot: Shows the point estimates and confidence intervals using scatter plot glyphs.
- Barplot: Shows the point estimates and confidence intervals as rectangular bars.
- Countplot: Show the counts of observations in each categorical bin using bars.
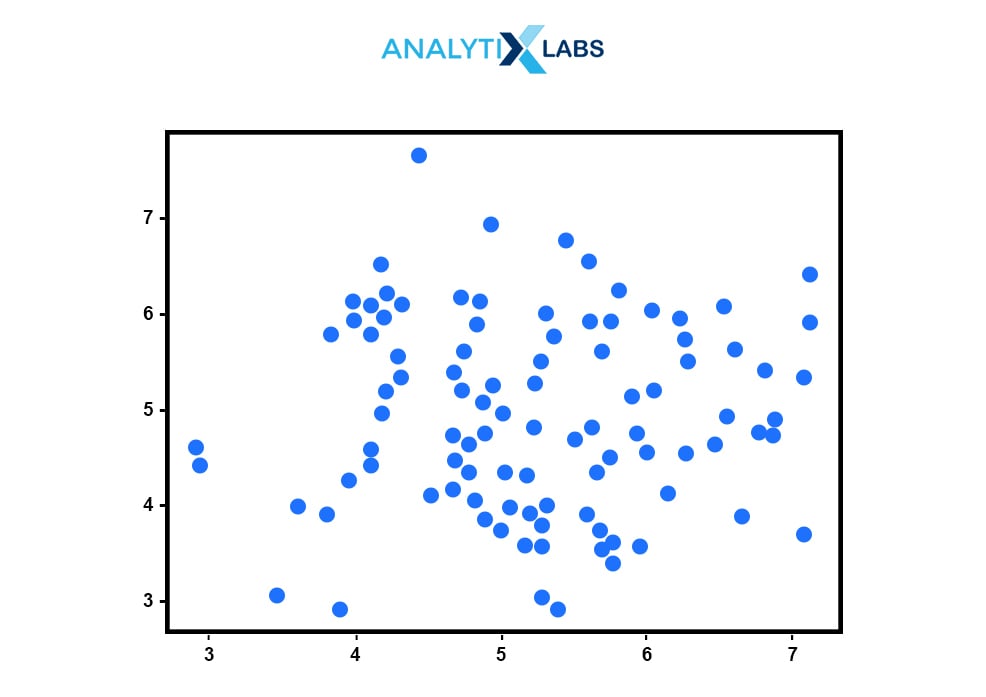
Q3.13. What is a scatter plot?
A scatter plot is a two-dimensional data visualization that illustrates the relationship between observations of two different variables. One is plotted along the x-axis, and the other is plotted against the y-axis.
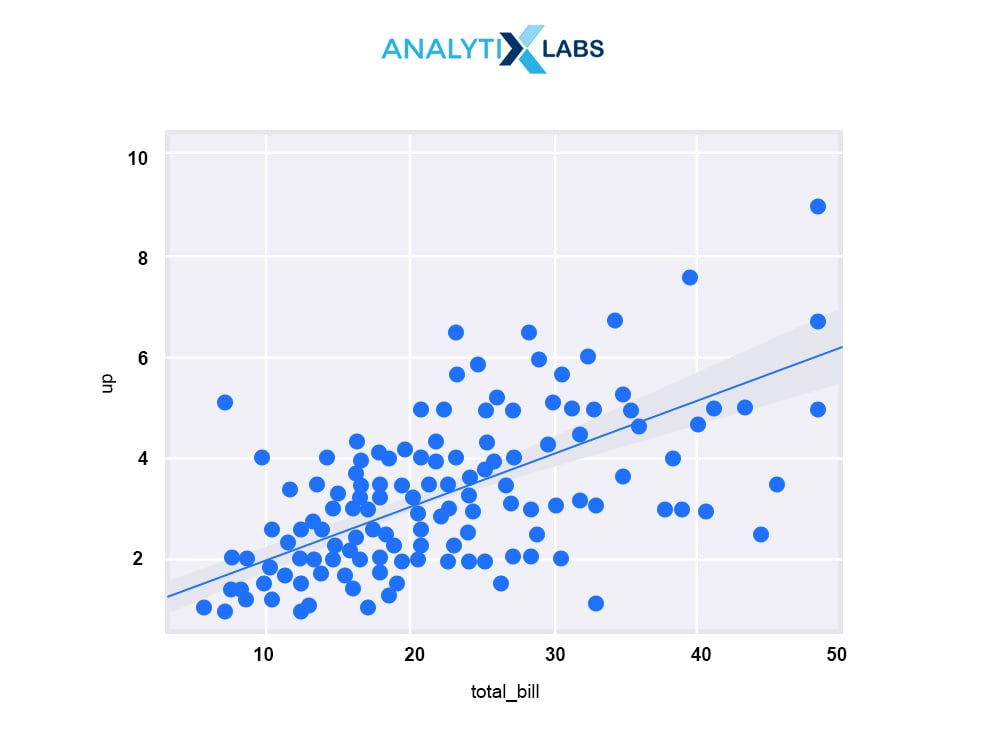
Q3.14. What is the difference between regplot(), lmplot() and residplot()?
regplot() plots the data and a linear regression model fit. It will show the best fit line that can be drawn across, given the set of all observations.
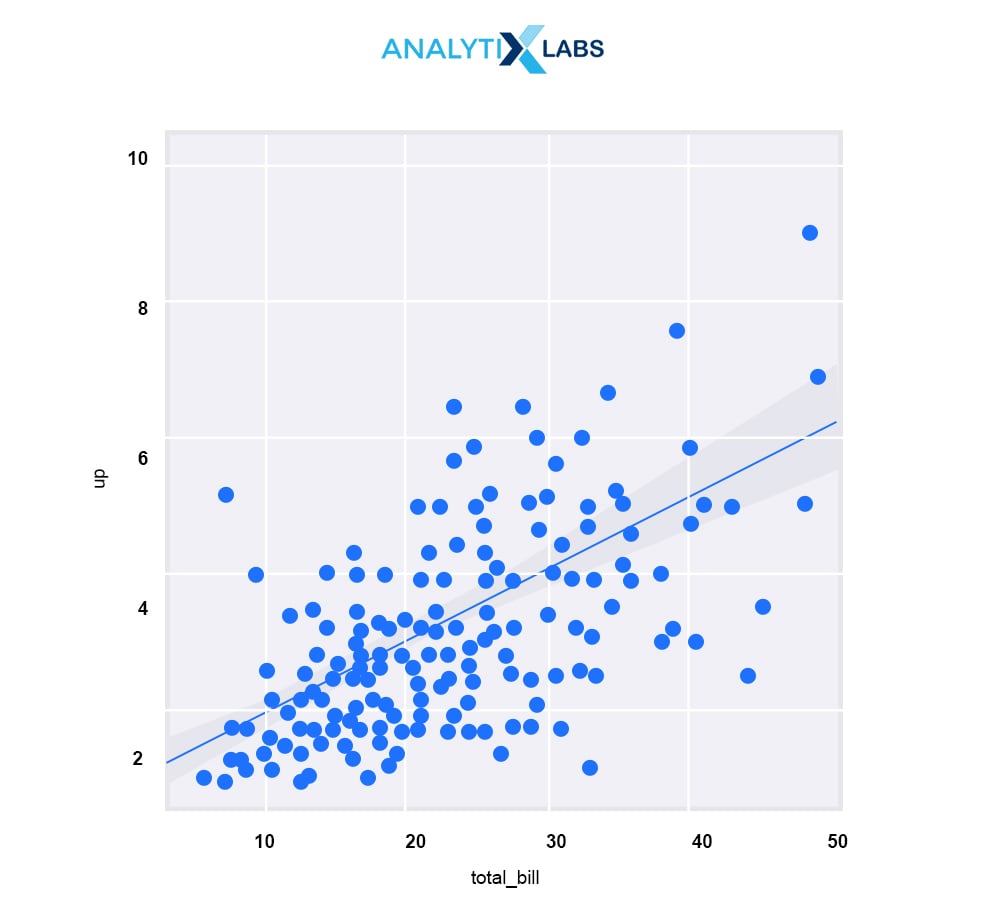
lmplot() plots the data, and the regression model fits across a FacetGrid**.** It is more computationally intensive and is intended as a convenient interface to fit regression models across conditional subsets of a dataset. lmplot() combines regplot() and FacetGrid.
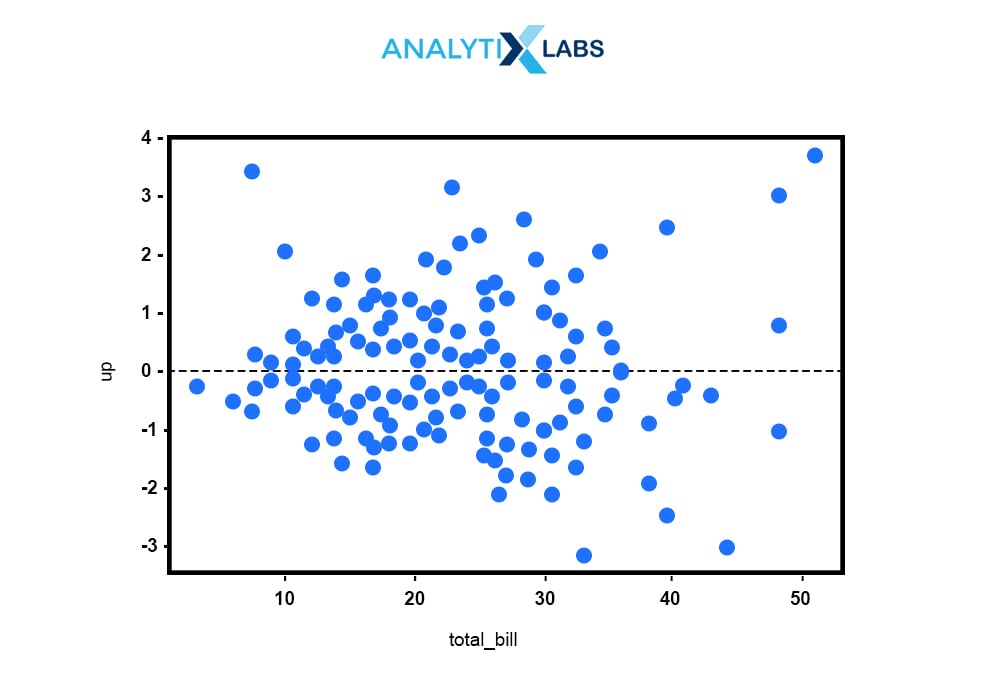
residplot() plots the errors or the residuals between X and Y, creating a linear regression equation for the same.
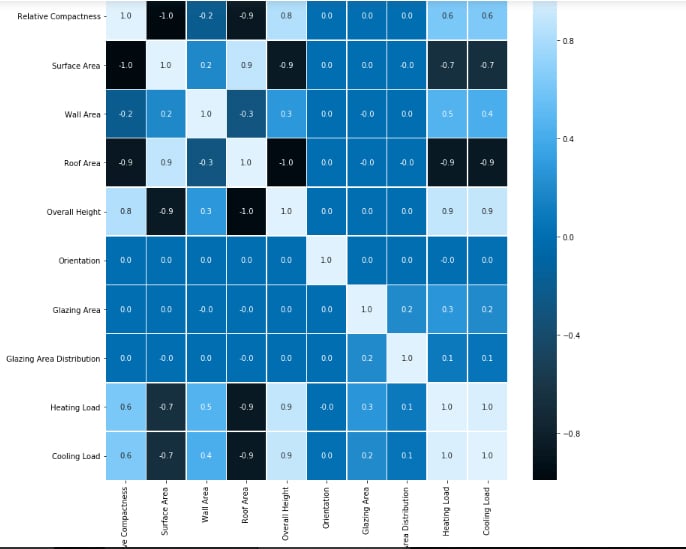
Q3.15. What is a heatmap?
A heatmap is a two-dimensional graphical representation of data containing individual values in a matrix format. The values show the correlation values and are represented by various shades of the same color. The darker shades indicate a higher correlation between the variables, and lighter shades reflect lower correlation values.
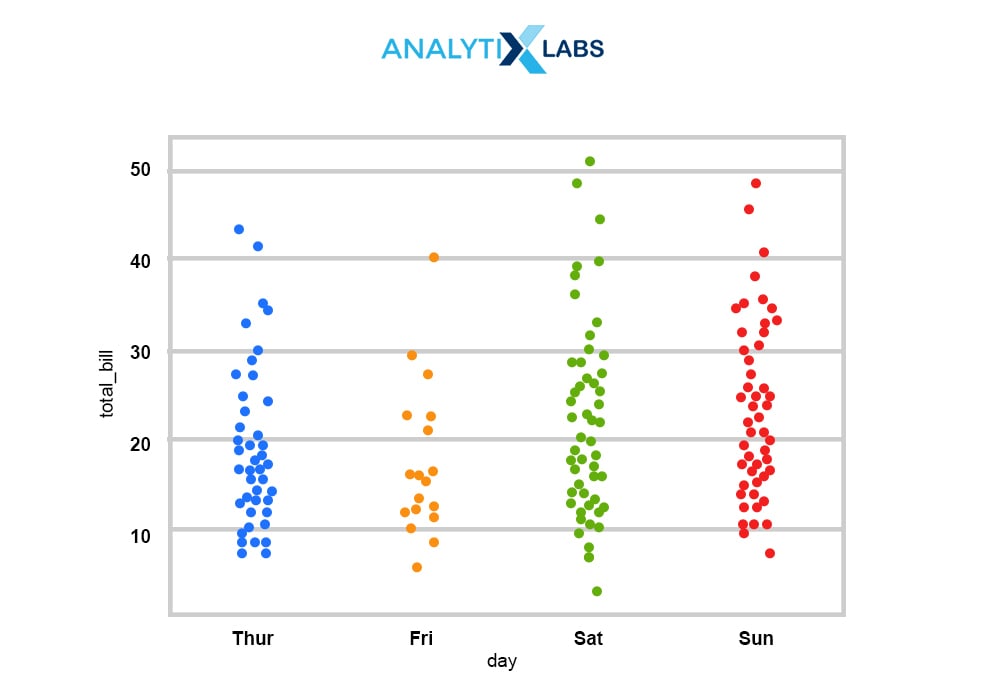
Q3.16. What is the difference between stripplot() and swarmplot()?
Strip Plot: It plots a scatter plot where one variable is categorical. A stripplot() can be drawn on its own, but it is also a good complement to a box plot in cases where one wants to show all observations and some representation of the underlying distribution.
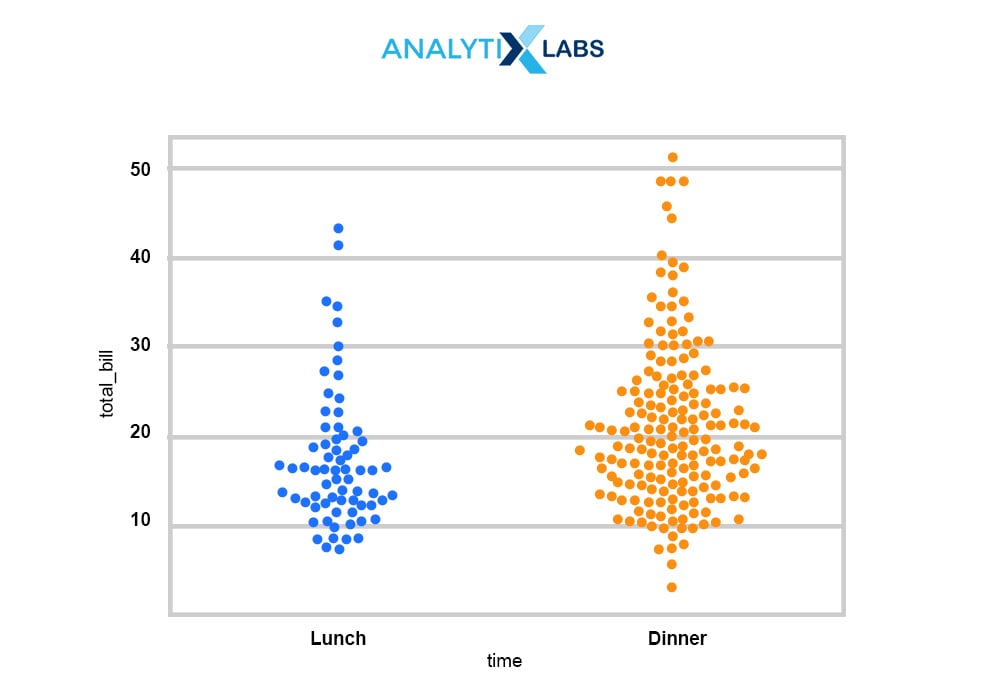
Swarm Plot: It is also used to plot a categorical scatter plot; however, it is with non-overlapping points here. swarmplot() is similar to stripplot(), but the points are adjusted (only along the categorical axis) not to overlap. It is a better representation of the distribution of values; however, it does not scale well to large numbers of observations. This style of the plot is sometimes called a “beeswarm.”
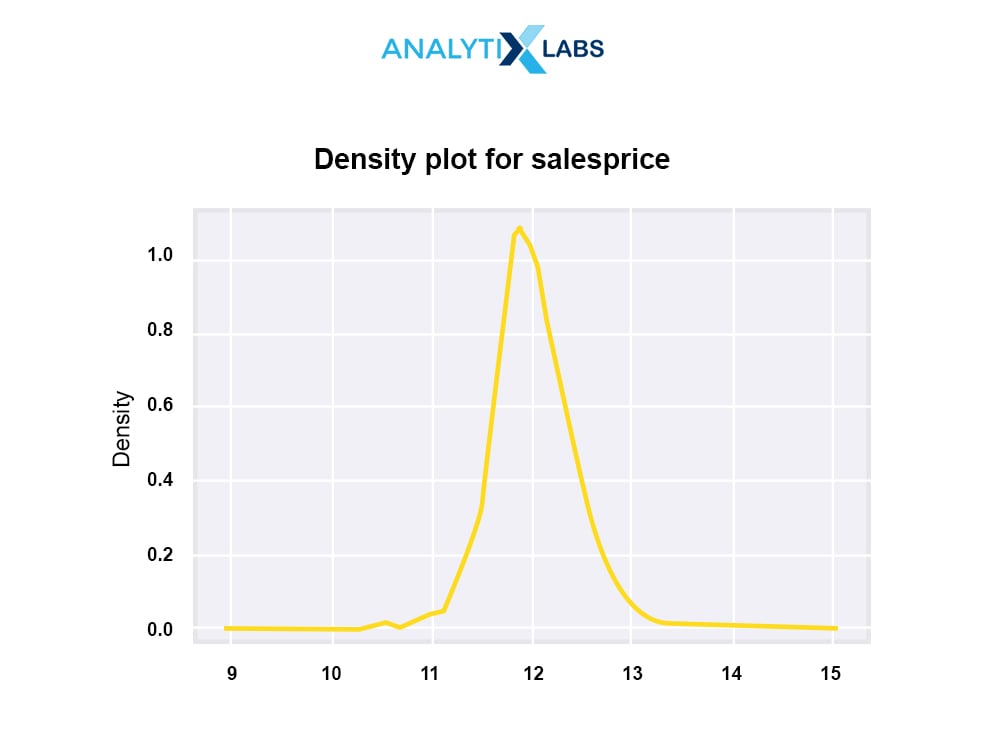
Q3.17. What is the purpose of density plot or kde plot? Where are these used?
A density plot visualizes the distribution of data over a continuous interval or time period. A variation of the histogram density plot uses a kernel for smoothing the plot values. This allows smooth noise. The peaks of a density plot illustrate where the values are concentrated over the interval.
Q3.18. How is violinplot() different from boxplot()?
A box plot (or box-and-whisker plot) shows the distribution of quantitative data that helps compare between variables or across levels of a categorical variable. A box plot is the visual representation of the statistical five-number summary of a given data set.
The box shows the quartiles of the dataset while the whiskers extend to show the rest of the distribution, except for points that are determined to be “outliers” using a method that is a function of the inter-quartile range.
A violin plot plays a similar role as a box and whisker plot. It shows the distribution of quantitative data across several levels of one (or more) categorical variables such that those distributions can be compared.
Unlike a box plot, where all of the plot components correspond to actual data points, the violin plot features a kernel density estimation of the underlying distribution.
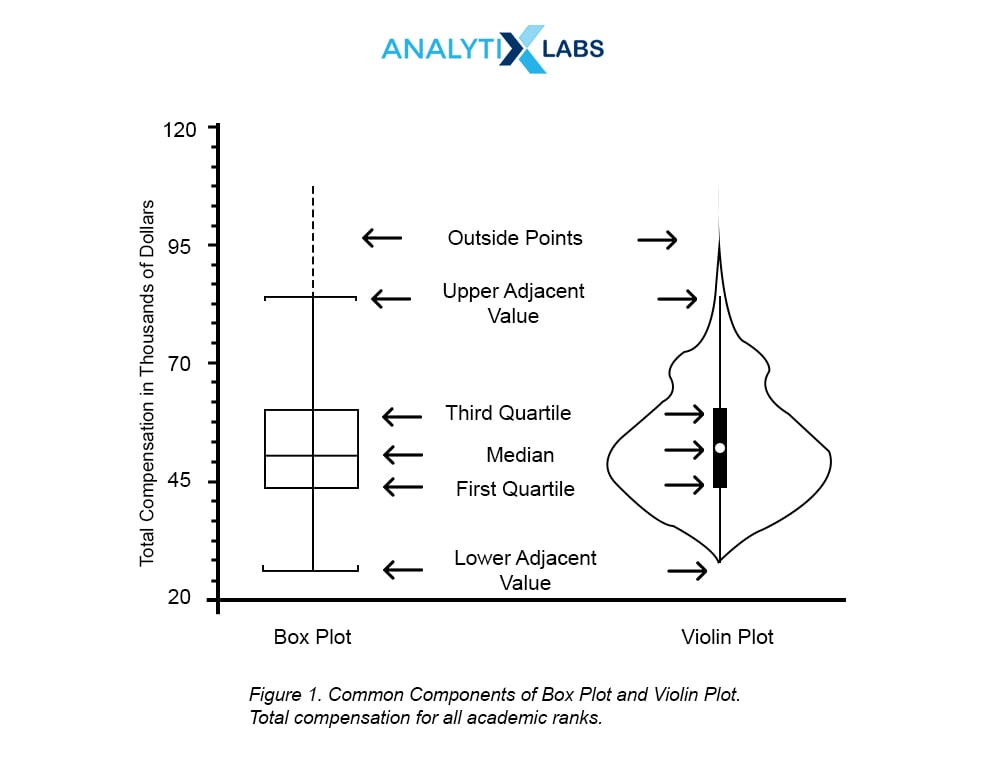
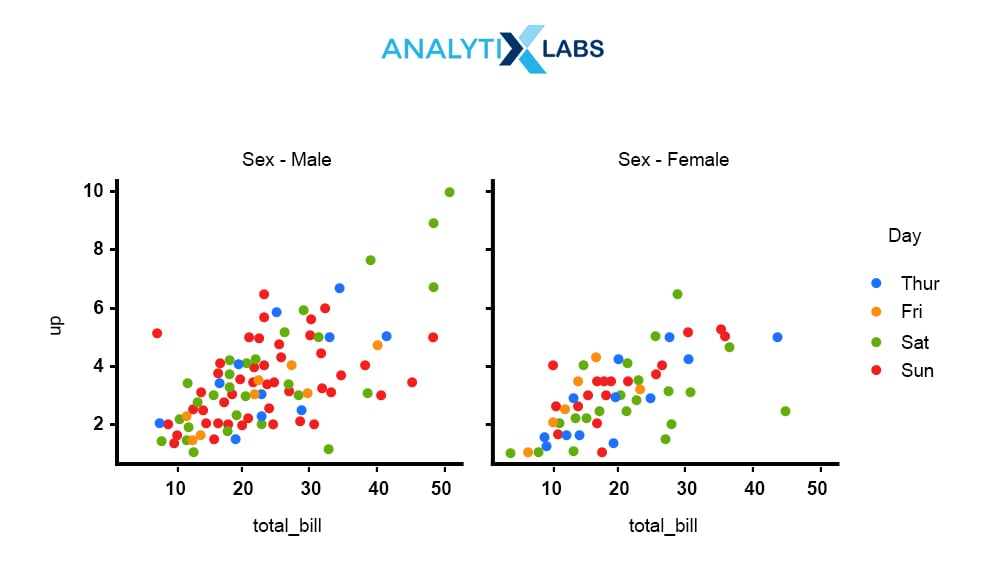
Q3.19. What is FacetGrid?
It is a multi-plot grid for plotting conditional relationships. It helps in visualizing the distribution of one variable and the relationship between multiple variables separately within subsets of your dataset using multiple panels. It maps the dataset into multiple axes arrayed in a grid of rows and columns that correspond to levels of variables in the dataset.
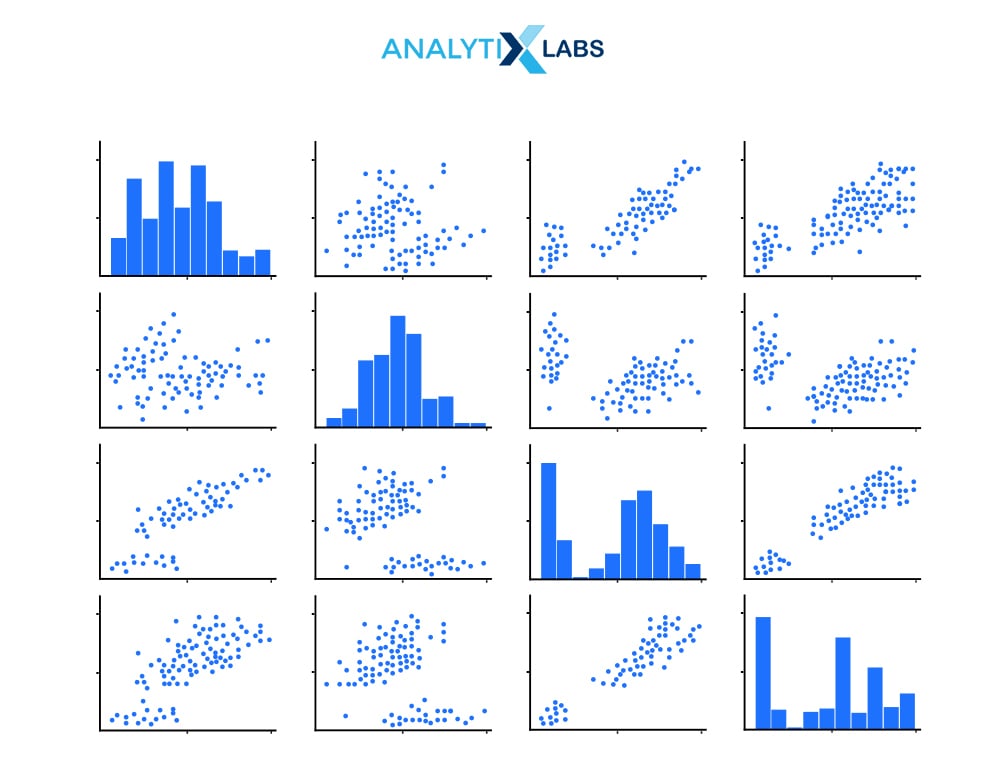
Q3.20. What is a Pairplot?
A Pair plot shows the relationships for a pair of columns of the data. It creates a matrix of axes where the diagonals show the distribution of each variable with itself.
FAQs – Frequently Asked Questions
Q1. How do I prepare for a Python interview?
There is no one way to prepare for the Python interview. Knowing the basics can never be discounted. It is necessary to know at least the following topics for python interview questions for data science:
- You must have command over the basic control flow that is for loops, while loops, if-else-elif statements. You must know how to write all these by hand.
- A solid foundation of the various data types and data structures that Python offers. How, where, when and why to use each of the strings, lists, tuples, dictionaries, sets. It is must to know how to iterate over each of these.
- You must know how to use a list comprehension, dictionary comprehension, and how to write a function. Use of lambda functions especially with map, reduce and filter.
- If needed you must be able to discuss how you have used Python, where all have you used to solve common problems such as Fibonacci series, generate Armstrong numbers.
- Be thorough with Pandas, its various functions. Also, be well versed with various libraries for visualization, scientific & computational purposes, and Machine Learning.
In addition to the above, the best way to practice writing code for interviews is by knowing how to write a code on a whiteboard or a piece of paper. In the current times of online interviews, one could be asked to write the codes in the chatbox depending on the medium used for the interview. It is best to know how to structure your thought process for coding round interviews in such cases.
Q2. Is Python allowed in coding interviews?
Yes, and yet it depends upon the process of each company. Python can be allowed in coding rounds, and some companies conduct the python interview questions via platforms such as HackerRank and alike.
We hope this repository of python interview questions for data science and Data Science interview questions have been useful to you. For brighter job prospects, you may also consider a Global Certification Course in Python for Data Science.
You can also enroll in our certificate course in data science and our exclusive certificate course in data science course to jump-start your Data Science career!
If you have any questions or want to share your feedback, reach out to us in the comments section below. Happy Learning!
You may also like to read:
1. Top 40 Data Analyst Interview Questions & Answers
2. Top 60 Artificial Intelligence Interview Questions & Answers