Data Science is a field that uses multiple tools and technologies to solve business problems. This is because Data Science is an amalgamation of multiple fields such as Data Extraction, Storage, Manipulation, Analysis, Prediction, Reporting, etc. Over the period of time, different tools have been identified to be used in the various aspects of Data Science. Among these tools is SQL. With the advent of Big Data and the common requirement for data scientists to perform ETL (Extract, Transform, and Load), the need to know SQL has become of paramount importance. This article aims to provide the reader with a decent level of understanding of all the underlying phenomena and processes of using SQL. The article will cover broader topics such as what role SQL plays, its common application areas, its basics, etc.
A Brief on Learning SQL

If the question is regarding the need to know SQL, especially in Data Science, then a big YES answer. Data Science is the topmost emerging field with thousands of job opportunities. SQL knowledge is a must to excel in the data science field. While nowadays, Machine Learning & AI dominate the fields of Data Science, one of the most important skills still remains to be SQL which is almost 50 years old.
Thus, learning SQL for Data science is crucial. Now when starting on the journey of SQL, several questions come to mind – How to learn SQL, Why do you need SQL? Is SQL important? Etc. However, before we answer those, you first need to have a brief idea of SQL and its related concepts.
SQL and related concepts – an overview
First, you need to know from where exactly does SQL comes into the picture of Data Science? As mentioned earlier, Data Science involves collecting, analyzing, retrieving, and storing data. Handling large amounts of data is also one of the main concerns for data scientists. This is especially true in today’s world, where huge amounts of data are in every field. For example- Netflix suggests what you should watch next based on previous selections. Similarly, if you search for something on Google, showing you similar items or products again. This is made possible because of data storage and its smart use of it.
Now the problem arises- where do we store the data and how to access it easily. Excel has capabilities but is limited to small volumes of data. Therefore, we require a mechanism for the data to be stored and structured somewhere that is easy to access, edit, manage and maintain.
This is where Databases come into the picture. Databases make data storage secure, efficient, and fast. They provide a framework for how the data should be stored and retrieved. These databases are mainly of two types-

(1) Relational Databases
In relational databases, the data is stored and organized into tables that can be linked to each other and use some relation. This gives us the ability to have connected tables, which helps us better understand the relations between different elements of tables.
- The way to communicate and interact with relational databases is by using SQL, which is essential to know about.
- Common relational databases include MySQL Database, Oracle, MS SQL Server, and Sybase, and they all use the language SQL.
(2) NoSQL Databases
With the advent of big data and data often being in a non-structured format, a new database was innovated- NoSQL databases. This database is considered more agile, flexible, efficient, and more suited for modern Data Science driven fields. Common NoSQL databases are MongoDB, Cassandra, etc.
Still, as very often the data can and is stored in a structured format, SQL has not lost its prominence. Now let’s understand some basics about the SQL language.
SQL is a structured query language used in relational database management systems to store, read, update, and retrieve data from the database. SQL was initially developed at IBM by Donald D.Chamberlin and Raymond F.Boyce after learning about the relational model from Edgar F. Codd in the year 1970. SQL was standardized when the American National Standards Institute (ANSI) adopted an official SQL standard in 1986 and then by the International Organisation for Standardisation, known as ISO, in 1987.
There are various open-source relational database management systems built around SQL that are available for use by Organizations in the market, which, as mentioned above, include:
- Microsoft SQL Server
- Oracle Database
- IBM DB2
- MySQL (owned by Oracle)
- PostgreSQL
- SAP
To provide some idea, this is how typically a MySQL Workbench looks like-

Understanding the importance of SQL
While we do have some idea regarding why SQL might be of high importance, let’s understand the fine points for the reasons behind its importance.
- Manage Huge Data
Traditional spreadsheets(excel) can be used only to manage small to medium-sized datasets, so we need an alternate solution to manage such huge records. This is where SQL comes in handy.
- High in Demand
Companies are currently searching for those individuals who are skilled in SQL. Employers know the worth of someone who is skilled in SQL and can lead Data-driven departments. Also, if you want to change a job, learning SQL makes you a favorable candidate.
- High Salary
Having the knowledge of SQL can put you in a position to have a high salary.
- SQL is easy to learn and open Source
SQL is an open-source language, and it has a large community of developers. It is comparatively easy to learn, and SQL syntax relies on common English words. Therefore, even if you have no background in programming, you can easily understand how to use it.
- Helps in quick Exploratory Data Analysis
You can use SQL commands to obtain a detailed understanding of your dataset, which is crucial in order to retrieve any useful information from it.
- Combine Data from Multiple Sources
It often happens when we need to combine data from multiple sources, and it can become a very difficult and time-consuming task. However, SQL makes it easy to combine data from multiple sources using JOINS and UNION operations.

For example, if we have three different tables- Table 1, Table 2, and Table 3 and if we want to combine them, SQL operations can easily achieve this task. In contrast, earlier, other tools or technologies would have made this task extremely time-consuming and difficult.
Important topics in SQL for Data Science
We have discussed the general importance of SQL. Now let’s discuss why SQL is of particular importance in the field of Data Science (because of which the knowledge of SQL has become a ‘must’ along with other languages such as R and Python).
Some important aspects and operations where SQL come in handy in the field of Data Science are the following-

- Data Types in SQL
Data Type is a guideline for SQL workbench that dictates what type of data is to be expected in a particular column. Each column in a table is required to have a proper name and a data type, where the user has to decide what data type is to be given to a particular column. There are some data types in MySQL, for example:
-
String
-
CHAR
-
VARCHAR
-
BINARY
-
VARBINARY
-
TEXT
-
Numeric
-
INT
-
FLOAT
-
DOUBLE
-
Date and Time
-
DATE
-
DATETIME
-
TIMESTAMP
-
YEAR
This data standardization makes it extremely handy when performing data science as we often need to have the data and its columns to have proper data types. This helps in the easy implementation of functions and performing other operations.
- Selecting and Retrieving Data with SQL
In Data Science, we often require a specific dataset for analysis or creating a model. Therefore, to select and retrieve the dataset from the database, commands such as SELECT of SQL come in handy. For example, if we have a table in our current database with the name – Employee.
| Employee ID | Employee F. Name | Employee L.Name | Salary |
|---|---|---|---|
| 1 | Aron | Mathew | 20000 |
| 2 | Deb | Woods | 40000 |
| 3 | John | Adams | 60000 |
And if we want to retrieve the whole data, then we use the SELECT command:
SELECT * from employee;
Here * is used to retrieve the whole data, so we get the output as a full table.
- Filtering, Sorting, and Calculating
Often Instead of simply retrieving the whole data, we need to retrieve the data based on some conditions. Here commands such as the WHERE clause help for filtering out data from a table.
Suppose we want to retrieve the data based on conditions, e.g., want the employee id whose salary is more than 60000, then we write the query like:
Select employee id from employee
Where salary >60000;
| Employee ID | Salary |
|---|---|
| 3 | 60000 |
This is the output we get by running the above query. If you want to sort the data, then the ORDER BY clause is used for sorting any column.
- Aggregation Functions
The next advantage of SQL is that it can quickly provide us with descriptive statistics to summarize the data. An Aggregate function performs the calculation on a set of values and returns a single value, and it ignores the null values (except count(*)). Some of the common aggregation functions in SQL include:
- Min
- Max
- Avg
- Count
- Sum
Let’s look at some queries related to the above aggregate functions:

- String Functions and Operations
A string function is a function that takes a string value as an input regardless of the data type of the returned value. In data science, where Natural Language Processing is often a common theme, and the user needs to perform operations on text-based data, these string functions help the user clean the data. Common string functions in SQL are:
1. ASCII -American Standard Code for Information Interchange. This ASCII query returns the output as:

2. CONCAT – concat is a scalar using SQL string function that takes multiple strings as input and returns a string after concatenating all inputs. This function takes a maximum 254 of inputs.

Other important functions include-
-
SOUNDEX
-
DIFFERENCE
-
LEFT
-
RIGHT
-
LOWER
-
UPPER
-
JOINS
One of the most important aspects of SQL is how it allows the user to combine datasets from multiple sources. This is of particular importance in Data Science. To create a model, we need to create datasets such as Customer360, where data regarding certain subjects must be gained from multiple places (datasets). Here various SQL statements are used to combine data from two or more tables based on a common field between them. This concept in SQL is referred to as Joins. Common types of Joins in SQL are:
3. INNER JOIN – Select all rows from both tables as long as the condition satisfies.

4. LEFT JOIN – This join returns all the rows from a table on the left side of the join and matches rows for the table on the right side of the join.

5. RIGHT JOIN – This join returns all the rows from a table on the right side of the join and matches rows for the table on the left side of the join.
6. FULL JOIN – This join creates the results-set by combining the result of both LEFT JOIN and RIGHT JOIN.

- Date and Time Operations
Dates are a little complicated for new users while working with databases. In Data Science, Time Series Forecasting based problems require the dates to be preserved and handled properly. There are various functions for dealing with dates in SQL, such as:
-
NOW() – Returns current date and time
-
CURDATE() – Returns Current date
-
CURTIME() – Returns Current time
-
Extract() – returns a single part of date/time
-
Output Control Statements
SQL control statements are the statements used when you want your output as per requirements. Example – ORDER BY clause and limit function to get limited rows.
- SUB QUERIES
A subquery is used to return data when with the main query as a condition to restrict the data further.
- Views and Indexing
Indexes are special lookup tables that the database search engine can use to speed up data retrieval. In simple words, an index in a database is similar to the index of a book, and this eases the quick retrieval of desired datasets.
- Query Optimizations
When we are dealing with larger datasets, it is important to use the most efficient method for a SQL statement to access the requested data. This brings us to the advanced stages of SQL. Broadly these query optimizations are divided into Cost-based and Heuristic Optimization techniques. As in Data Science, we often deal with large amounts of data, and Query Optimization is a great feature to have.
7 Steps to Learn SQL for Data Science
The primary step is to know where to learn from. If you are looking for online or classroom learning, we have it sorted for you.
AnalytixLabs is the premier Data Analytics Institute specializing in training individuals and corporates to gain industry-relevant knowledge of Data Science and its related aspects. It is led by a faculty of McKinsey, IIT, IIM, and FMS alumni who have a great level of practical expertise. Being in the education sector for a long enough time and having a wide client base, AnalytixLabs helps young aspirants greatly to have a career in Data Science.
Your starting point is here: Master SQL now.
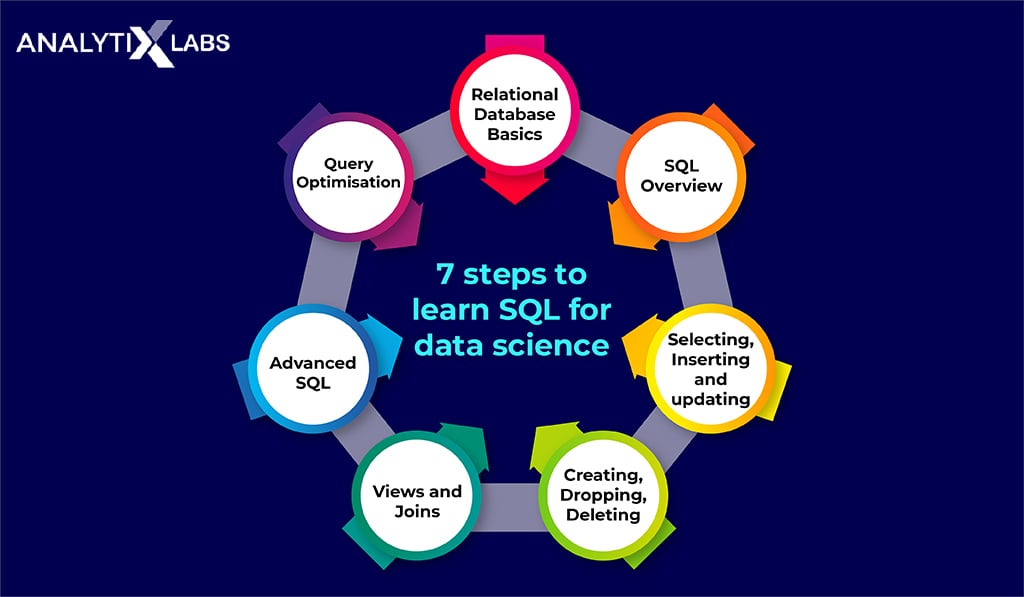
You can assess what you need to know about SQL from the above discussions and layout seven steps to learn SQL for Data Science.
- First, you need to understand the concepts related to Databases and the types of Databases. To learn SQL, you will need to get some insights into Relational Databases.
- Your next step is to get an overview of SQL i.e. What is SQL?, How SQL is important for being a Data Analyst, and what are the important topics to learn SQL.
- After knowing the important topics, now you need to focus on the topics such as Selecting, Inserting, and Updating columns in the dataset.
- After that, you need to learn about creating your own dataset along with how to delete them.
- The next step is to learn about Joins and views.
- Once you know about joins, you move to Advanced SQL. Advance SQL includes Hierarchical queries, Triggers, etc.
- Finally, you need to explore Query Optimization. This includes the use of Explain Plains, Profiling, etc.
The journey of mastering SQL can be quick if you follow the above steps to learn SQL for Data Science.
FAQs: Frequently Asked Questions
Q1. How long does it take to learn SQL from scratch?
To learn SQL from scratch, it would take 10-15 days to learn the basics of SQL and 1.5-2 months to master SQL. But it totally depends on you how much time you devote to learning, your background, your dedication, your grasping power, and last but not least- a good source to learn SQL. However, when it comes to which SQL you should go for then, there are different SQL Vendors available – MySQL, PostgreSQL, Oracle, and Microsoft SQL Server. While they all are good in their own ways, among these, the most preferable one is MySQL, which anyone should learn first.
Q2. Is it hard to learn SQL?
It is not really hard to learn SQL. It is just like English, so anyone who (theoretically) knows basic level English can learn to write SQL queries easily. Also, as it is a widely used old open-source language, it has a huge community to help you with your problems and queries, making the learning process easier.
Conclusion
In Conclusion, as SQL is a free and open-source programming language and is involved in making the data available to the user, it forms the foundation of Data Science. It is recommended for every aspiring Data Analyst and Scientist to learn SQL. In this article, we answered the questions such as what is SQL and How to learn SQL, particularly how to learn SQL from scratch, and it is recommended to consider this as a base for your understanding and build upon it going forward.