Big itself is a confusing word. It can indicate something huge or something important, or even something complex. Now imagine everything together. Yes, that is exactly what big data stands for. It is a combination of every type of data that is mined and managed. The data is important when running critical algorithms of artificial intelligence and machine learning.
Data is produced everywhere in this digital era and it is used to make technology more relevant and capable of serving multiple causes. According to a recent study, data production is over 2.5 quintillion bytes every day now.
From every click, swipe, share, search and stream, more data is added to the data environment. Gradually, sorting and using this large amount of data is a complicated task. Moreover, these raw data are found in different unconventional forms. Not only structured data but there is unstructured and semi-structured data present as well.
Before understanding each of these forms keenly, let’s learn the relevance of big data and understand why everyone is talking so much about it.
- The big data analysis market would grow 12.3% from 2019 to 2027 as it contributes to almost every sector, including healthcare, IT, manufacturing, environment, and many more.
- Unstructured and structured data in big data help to process important information from different aspects. All kinds of organized data are useful from a wider observation perspective.
- Big data for businesses comes from customer feedback and complaints. They can use it to determine areas of improvement, provide better service, and create customized marketing solutions.
- The global spending on big data analytics was more than $180 Billion in 2019. However, in 2020, almost 90% of businesses considered this data analytics approach crucial for their core business improvement.
- Critical disease detection, risk analysis in financial experiments, and getting valuable insights into research are becoming more feasible with big data. Even the government uses big data analytics during emergencies.
Big Data Does Not Include Structured Data
Structured data definition states it is a predefined format in which data is stored and analyzed. It usually is a tabular, series, or pattern format of data. However, big data needs a bigger scope to include exclusive data to make the machine learning algorithms more efficient. So, there is more in the big data environment than bounded, structured data.
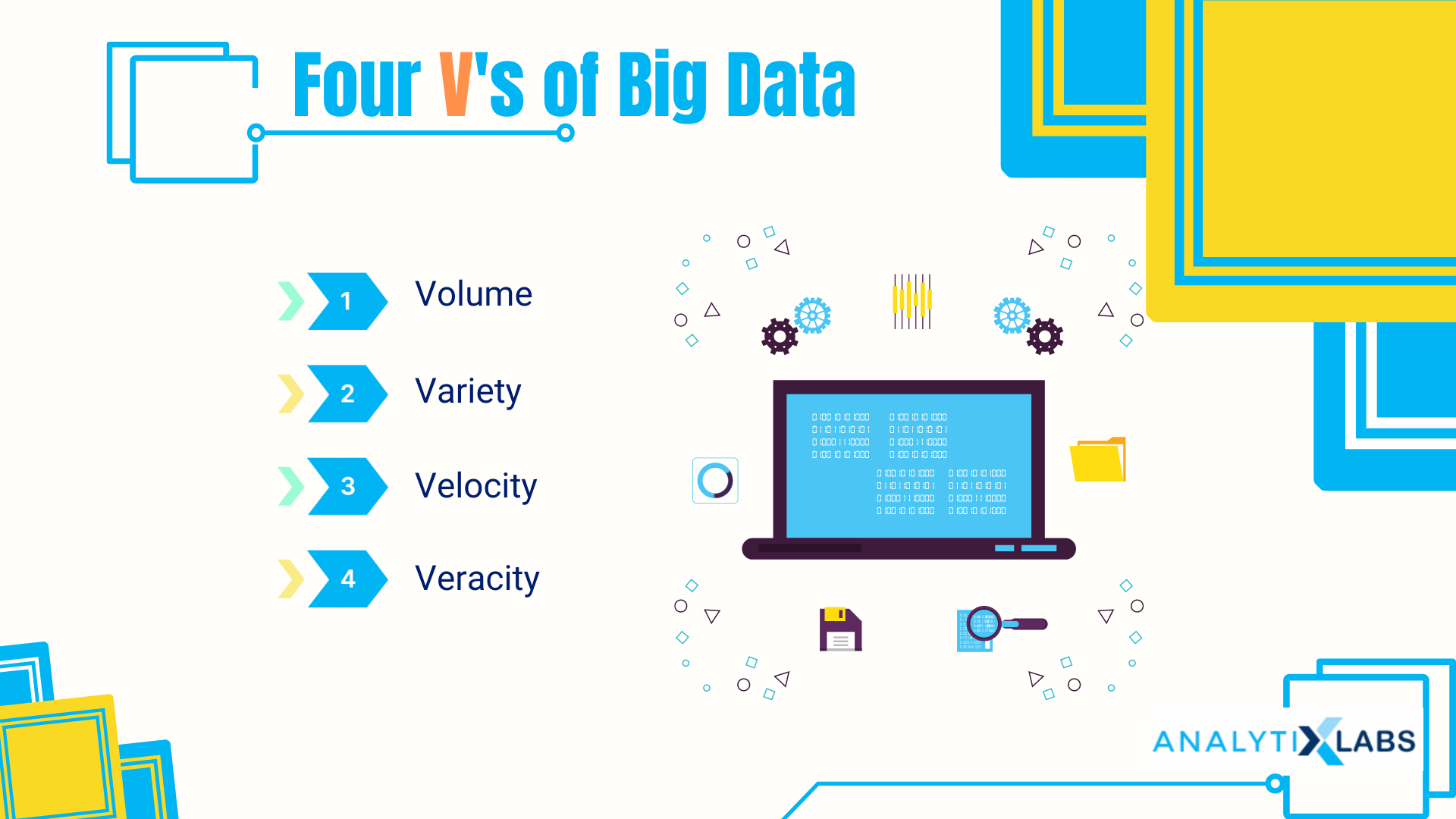
The intent of big data can be described using the following four V’s-
- Volume
- Variety
- Velocity
- Veracity
-
Volume
The very first feature of big data is its huge volume. As everything around us is relevant to something or the other, the amount of data generated is great in volume.
To store the data, we have a data lake that works as a cloud storage system with elastic properties.
However, with such a volume, there is a problem with accessibility as well. It can be addressed by different user policies to truncate the data that are not being used. So, it is not only about the amount of data the data lake can hold, but also how much of it is used to make the predictions more accurate .
-
Variety
Variety is another feature of big data, as different types of data from multiple platforms are processed simultaneously. Cross-platform and cross-channel integration facilitate the collection of data from numerous sources. The variety of data is an important component of big data because it affects the significance of the inferences made from the data .
-
Velocity
Speed is a prime factor of big data. With the latest tools and technologies, data processing becomes quicker and can be automated in many places. Likewise, gathering huge amounts of data will not make sense if they are not being used at a fast pace.
To consider the application of big data, the data must be analyzed fast for businesses to get market insight, customers to get the right information, etc. There are a lot of scopes to improve tools that can handle large data in real time and generate insightful information.
-
Veracity
The veracity of big data stands for adding value. As big data comes into play, the primary goal is to make technology more automated and human-friendly. This process requires serious data recognition to understand how much credibility data may hold.
Likewise, it is possible to merge big data with critical augmented analytics to measure correlations, identify outliers, and predict outcomes with data. Adding value to the complex problem to make the outcome user-friendly is the main goal of big data.
For example, a sales team can use a modern platform to connect all the data collected from multiple platforms such as social media, eCommerce, sales, etc. Then, it will be processed to get a complete line of the customer journey.
Also Read: Understanding Veracity in Big Data
All the four V’s together are the definition of big data and the primary indication of its working method.
Data Structures
Data and structure themselves indicate the notion of data structure. Considering a big data environment, data is received in different forms. What are they called, how do process them in a particular form, and how are they connected to each other are all the parts of the data structure?
Based on the type of data structure, distinct approaches are adapted to achieve the information required from the different data structures.
Also Read: Understanding Data Structures: Types and Applications
Let’s dig into these three types of data structures and how they are important in big data.

Structured Data
Structured data is a predefined data structure that generally comes in tabular (in the form of rows and columns) form. As it adheres to the conventional model, it can directly be used in formulas and algorithms.
Generally, SQL (structured query language) is used to manage and update the structured database. There is a concept that big data contains only structured data which is not right. It is the most traditional data structure but has some limits.
Also Read: Why You Should Learn SQL in the age of Python and R?
Data that does not fit into the tabular form cannot be processed with structured data formulas. So, structured data in big data is an integral part, but there are some other valuable concepts too.
Unstructured Data
Unstructured data has a wider variety and extent in terms of content. All the types of data that you can think of are examples of unstructured data. Unlike structured data, there is no predefined format or rules to fit unstructured data.
This is an example of a modern data structure that works on adaptability than the conventional application of a formula. NoSQL database is used to store this type of data. From text messages to audio, call records, and social media posts- everything is a part of unstructured data in a data environment.
For complex algorithms, structured data in big data is not enough and you need more data that are more flexible with the human experience. Such use cases highlight the importance of unstructured data.
Semi-structured Data
Some unstructured data contain metadata (data about data) which helps to categorize and analyze the huge data conveniently. This type of data is beyond structured data in big data but is less complex than unstructured data. There is a hierarchy present in this form to connect the data internally with metadata that takes less time to get processed than unstructured data. However, the scope of semi-structured data is more than that of traditional structured data.
What is Unstructured Data?
Unstructured refers to a non-conventional model where pre-defined rules cannot be applied. Similarly, in a data environment, the volume of unstructured data is up to 90% of the data collected from different enterprises.
Think of the very common things you use every day on your phone. Texts, audios, videos, images- all of these are unstructured data. Unlike structured data in big data, these have no fixed parameters, hence another name for unstructured data is qualitative data.
From different images or videos, you can retrieve information to know its quality and feedback around it. NoSQL databases are used to process unstructured data as there is no hard and fast model for it.
Now, this has both sides of a coin. With various important advantages, unstructured data have some drawbacks that need to be considered beforehand for feasible data processing.
Pros and Cons of Unstructured Data
Pros of Unstructured Data
- Adaptive format: As unstructured data don’t need to fit in some conventional model, it is pretty easy to choose a format as required from the data lake. This increase the use cases of the data to find some accurate information.
- More database options: There are different NoSQL databases like MongoDB, HBase, Redis, Riak, and Neo4J that help to process the unstructured data. Also, it can be stored in different file formats.
- Fast processing: Unstructured data takes less time to process as there’s no preprocessing requirement. Likewise, it is used in natural language processing and text mining.
- Massive storage: This type of data is mainly stored in cloud data lakes, allowing elastic storage as per the requirement. Similarly, the cost is decided as per the storage and no extra space is wasted.
Cons of Unstructured Data
- Complex processing: There is no predefined structure to fit unstructured data like structured data in big data. Gradually, it can only be done by some data science experts as they know which databases to use, which data need to be grouped together, etc.
- Difficulty in scaling: Due to large data storage, it becomes difficult to scale them. This may lead to data inconsistency as well.
- Special tools: To maintain and manipulate unstructured data, we need some special tools along with the expertise to use them. It can make the cost higher and the whole process more critical.
Examples of Human-Generated Unstructured Data
There are different types of qualitative data that are used to get processed information to reach a certain conclusion. Here are some of them.
- Medical records: Helps to understand the disease trend, use of different drugs, etc.
- Social media: Helps to get insights on current affairs, trends, what people are thinking about recent incidents, etc.
- Images, video, and audio media content: Helps to get information about particular places and personalities. Different enterprises use these data to know market requirements and public feedback as well.
- Survey responses: Helps to get information about different public issues based on place, time, age, and many other parameters.
- Webpages: Businesses may require the data revealed on a webpage to know about their business response from a closer perspective.
Unstructured Data is Not Organized
Unstructured data refers to those bits of information that are not readily available to plot in a graph and get insights. Data mining is required to process the data as per the requirement to get some information. However, the data is still as valuable as structured data in big data but more difficult to harness.
On the other hand, disorganized data has a structure, but they are presented in a messy condition. With thoughtful data mining, gap-filling, deduplication, and benchmarking, these data can also be made useful.
What is Structured Data?
Structured data in big data can be defined as formatted, well-defined data that follow conventional rules. Unlike unstructured data, this comes in a schema manner that can be represented in tabular form.
As you might have seen, different graphs like bar graphs, pie charts, etc. are made from structured data only. It is also known as quantitative data as values in structured data are presented in quantity.
To manage the structured data in a Big Data environment, SQL is used. To perform database management, SQL queries like MS SQL, Oracle SQL are much more efficient.
Pros and Cons of Structured Data
Pros of Structured Data
- Easy navigation: It is easier to find and manage structured data and also feasible for storing them. To access these data, indexing can be applied too.
- Compatible with tools: More tools are being used with structured data in big data. So the option of tools is wider and it would help to make the process faster.
- Used by beginners: People who are not data experts can manage and use structured data for business purposes. It has pre-defined models and methods that can be understood by people with basic knowledge of data handling.
- Security: As the structured data definition indicates, it is organized and scalable. Likewise, securing the database becomes easy as the formats are unchanged.
Cons of Structured Data
- Limited use cases: Due to predefined schema, the scope of structured data is less. As there can be multiple types of data available in a data environment, these conventional models cannot perform with restricted adaptation.
- Small storage: Structured data are stored in a data warehouse that has a limited capacity. So, it would take more time and money for every update. Also, these data warehouses are of fixed size, which might result in both space wastage and hoarding.
Examples of Human-Generated Structured Data
The concept that big data contains only structured data is a myth. It is always about organized data that can be formatted from structured or unstructured data as both add value to get the required information. As the structured data definition says, it is the collection of data in a predefined model. These types of data can be generated by humans as well as machines. Let’s find what human-generated data looks like.
-
All input data: From pop-up forms for opening an online account to inputs for any service application, all types of digital inputs are a huge part of big data.
-
Click-stream: Trends from clicking on an advertisement are helpful to track and trace the buying behavior of a customer. The gathered information results in structured data in big data. Purchasing action influences digital marketing with the help of AI to a huge extent now.
-
Gaming data: Playing games and in-app purchases add a lot of structured data to the gaming data environment.
Crucial Role of Structured Data in Big Data
According to the structured data definition, it is nothing but organized data that is stored in databases, datasets, and spreadsheets. It was invented by an IBM scientist, Edgar Codd, and used by companies like IBM, Microsoft, Oracle, and more. Structured data plays a vital role in the evolution of the big data environment. Therefore, it is used worldwide on an everyday basis.
It essentially has the following characteristics:
- Easy to use: The biggest benefit of structured data in big data is that it makes the data usable even by an average business user. There is no need of having in-depth information about the various types of data and their relationships. All that it takes is a good understanding of topics related to the specific data.
- Structural representation: The data is stored in both columns and rows. The first table stores the product information, whereas the second table stores demographic information. With the help of structured data, you can easily ensure data safety. It also has a defined structure that helps in easy storage and access to data. Besides, tasks like Business Intelligence Operations and Data Mining can be undertaken with minimal effort.
- Each one of the tables has a specific attribute: The table can be customized, which includes updating, reading, and deleting or adding new data. It also results in hassle-free operations. This process is often accomplished in a relational model by a structured query language (SQL).
Structured data avail more tools that have been tried and tested in analyzing and using structured data. Therefore, it is highly used among various data managers.
Another feature of relational or structured model SQL is that the tables can be queried using a common key. The common key in the tables is the CustomerID.
Structured vs. Unstructured Data
| AREA OF DIFFERENCES | STRUCTURED DATA | UNSTRUCTURED DATA |
|---|---|---|
| STRUCTURE | The structured data in big data relies on RDBMS and follows a column-row structure. Since this data is well organized it can be used by machines as well as humans. | It is not organized in a defined way. Therefore, it does not work with any set of data models. This is usually text-heavy but might also include other information like dates, numbers, and more. |
| SOURCES | These are sourced from GPS sensors, audio, video files, and text files. | These are sourced from PDF files, Email messages, word-processing documents, and similar files. |
| FORMS | It is consist of numbers and values | It consists of sensors, video files, text files, and audio files. |
| MODELS | Structured data in big data has a defined data model that is formatted to store data structures before it is moved to data storage. Example – Schema-on-read | It is stored in its original format and not processed until it is executed. Example – Schema-on-read |
| STORAGE | The data is stored in tabular format and requires less storage space. Examples – excel, sheets, or SQL database. It can also be used in data warehouses, which makes it highly scalable. | This data is either stored as media files or NoSQL databases, which requires more storage space. It can also be stored in data lakes. Therefore, it is difficult to scale. |
| USERS | It is usually used in machine learning and regulates algorithms. | It is used in text mining and natural language processing (NLP). |
| FORMAT | It works with a rigid schema that provides both consistency and efficiency. | It has no constant structure and is inconsistent. |
| EASE OF ANALYSIS | The structured data contains mature analytics tools for mining and other similar tasks. | In unstructured data, the analytics tools for mining are still under development. |
The Future of Data- Metadata
Recently, in big data environments, data growth has been increasing rapidly; which in return has fueled a new interest in the potential business values that can be derived from metadata. A variety of data structures exist that offer both opportunities and challenges.
Regardless if data is structured or unstructured, having the most accurate data sources handy can bring companies numerous advantages over their competitors.
Adapting the right data management will allow companies to:
- Reduce the cost of functioning
- Easily track current metrics and create new ones
- A better understanding of the customer’s intent
- Exposure to more targeted marketing campaigns
- Locate new product opportunities and offerings
Companies are now implementing metadata management to discard older data and develop a taxonomy. This helps to categorize data based on its business value. A component of metadata is a central database that serves as a metadata dictionary, also known as a data repository.
Brands like Aristotle Metadata are providing metadata solutions for businesses to help make more sense of the data.
Metadata management offers an arranged framework for systematizing the discrete data sets stored across multiple systems. It also provides organizational consent to illustrate information, often used in business, technical, and operational data.
In addition to categorizing the data, metadata management strategies are used for developing a data governance policy, improvement of data analytics, and establishing an audit trail for regulatory compliance.