
In today’s world, it is easy to get lost in semantics, and especially for those who are new to the field of Data Analysis, it feels like you are bombarded with a never-ending tale of jargon. Among these jargon, the most commonly used and often confused are Data Science, Machine Learning, and AI Deep Learning.
As per the Experts
Isaac Newton said, “If I have seen further, it is by standing on the shoulders of Giants.” Before elaborating on the obvious and nuanced differences between these three fields in the later section, allow me to provide some excerpts and quote authors who have written books, papers, and research in these fields.

Data Science
According to Tom Fawcett, in his book ‘Data Science for Business, he mentions that “Data Science involves principles, process, and techniques for understanding phenomena via the (automated) analysis of data.”
He also adds that “Data Engineering and processing are critical” and “to understand data science and data-driven business, and it is important to understand the differences.”
He then elaborates on how data engineering technologies help and assist the field of Data Science but are not to be confused with “Data Science technologies.”
He takes the example of Big Data technologies such as Hadoop and MongoDB. He clarifies that these are mere data processing technologies for huge quantities of data and are not to be confused with Data Science.
Chikio Hayashi mentions the overlap between Data Science and ML in ‘What is Data Science? Fundamental Concepts and a Heuristic Example‘ where he mentioned Data Science as a “concept to unify statistics, data analysis, machine learning, and their related methods.”
Related read: What is Data Science? With Examples
Machine Learning
Now with some idea of what Data Science is, let us understand what ML means to the experts.
ML, in straightforward words, as stated by Aurélien Géron in ‘Hands-On Machine Learning with Scikit-Learn and TensorFlow, ’ is “the science (and art) of programming computers; so they can learn from data.”
You may like to read in detail: What is Machine Learning?
In ‘Introduction to Machine Learning with Python’, Andreas C. Müller says that “It [Data Science] is a research field at the intersection of statistics, artificial intelligence, and computer science and is also known as predictive analytics or statistical learning.”
A more engineering designed explanation is provided by Tom Mitchell in his book ‘Machine Learning’ where it is mentioned that “A computer program is said to learn from experience E concerning some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.”
Artificial Intelligence (AI Deep Learning)
With this, we are left with AI Deep Learning. According to François Chollet in ‘Deep Learning with Python,’ Artificial Intelligence is said to be a “general field that encompasses machine learning and deep learning.”
Deep Learning, in particular, is stated as a “specific subfield of machine learning.” The above excerpts gave us an idea of what ML is but still what is different between ML and Deep Learning is clarified by him when he explains the meaning of ‘Deep’ in Deep Learning and explains that the term ‘Deep’ in Deep Learning is not a “deeper understanding achieved by the approach” but rather refers to the “successive layers of representations.”
He suggests synonyms for Deep Learning such as “layered representations learning and hierarchical representations learning.” Thus ML is the same as Deep Learning without the depth aspect, and most of the approaches to ML only have one or two layers of representations and hence are sometimes called “shallow learning.”
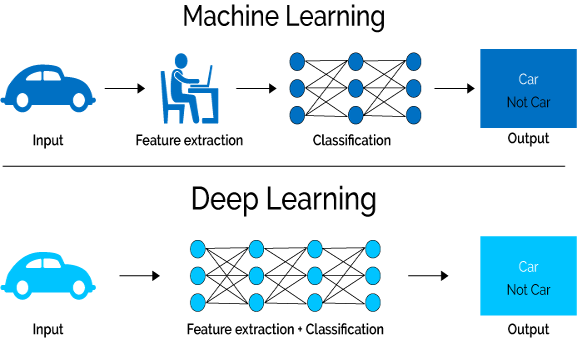
In his book ‘Deep Learning,’ Goodfellow explains the need for AI Deep Learning in feature representation. Let us first understand what they mean by feature. They take an example of a Logistic Regression model that recommends whether the patient should opt for cesarean delivery or not.
As the patients are not examined directly by the model, the model is fed with important information (example can be of blood pressure if suffering from fever, etc.), and “each piece of information included in the representation of the patient is known as a feature.” However, Goodfellow then identifies the limitations of such an ML model, pointing out that even though such a model can correlate the various inputs (features) with their corresponding outcomes, it fails to define these features properly.
He takes the example of an MRI scan. He points out that for a simple ML model such as Logistic Regression, a feature such as MRI Scan will be of no use as “Individual pixels in an MRI scan have a negligible correlation with any complications that might occur during delivery.”
Thus many inputs may be translated into features that an ML model can understand. Still, there are times when inputs cannot be successfully translated and extracted, and this is where Deep Learning comes in as it “solves this central problem in representation learning by introducing representations that are expressed in terms of other, simpler representations.”
You may also like to read: 101 of Artificial Intelligence – What to know as a beginner?
A Day in Data Scientist’s life
Let’s consider you work for SuperAnalytica (an imaginary Data Science company). You are assigned to analyze the workings of a client’s customer service centers spread across the globe on one project.
Now allow me to take you through three days of your work on this project where on the first day, you assume a role of an ML expert, on the second of an AI deep learning expert, and on the third day, you fill in the shoes of a data scientist. Check this out if you want to read more about the Data Scientist Job Description and the Role of Data Scientist.
Day One: Machine Learning Expert
You start by acquiring data. Data Acquisition in Data Science is a starting point but an extremely crucial step. Once the data is ready, you use your mathematical and statistical knowledge to explore the data and develop useful insights.
Various Statistical and Mathematical models can provide you with knowledge such as if the age of the agents in the service centers depends on the time taken by them to resolve the problem or not etc.
You also hardcode a lot of programming using ‘if’ and ‘else’ conditions and use some loops and think of as many possibilities as you can to give you insights. However, still, there are limitations to what all you can imagine and program.
For example, you find that the center received negative reviews when the average age of the agents was more than 30 minutes taken to solve the problem of a complainant was more than 10 minutes and the average waiting time for the complainant was more than 15 minutes.
Now you may hard code a program with these rules, but the influx of data is perpetual, and these conditions can change in the light of newly updated data.
Also, there can be an almost infinite amount of parameters that you need to look at before creating these rules, thus making the analysis complicated, coupled with the fact that the data is huge. This is where you take the help of ML.
Now, programming languages such as Python and R come into play, and concepts of ML such as Supervised and Unsupervised Learning become the environment for your work.

The methodology of your work will go through a paradigm shift as now instead of expecting answers by applying a set of rules (program) on your data, you will input the answers along with the data in an ML algorithm which will then output the set of rules which will then be used to find answers. This is a typical case when working with algorithms that work under a Supervised Learning setup.
You, on your project, will require well-labeled historical data (commonly known as Training Dataset), which will have all the parameters (variables/features) that you currently have.
The labels will be the satisfaction score provided by the complainants. Thus, we provide the supervised learning algorithms with the available input and correct output for all data points. The ML algorithm creates a function mapping and correlating the inputs with the outputs. This function is then used on the data provided to you for this project.
This way, the system is made to ‘learn’ rather than programmed, and the task is automated. When new well-labeled data comes in, the algorithm is made to rerun to update and learn a new function by determining the new statistical structure of the training dataset.
Another common environment where ML algorithms work is in an Unsupervised Learning setup with no training data available.
Here, you can perform tasks such as identifying the different groups of member service centers, each with different characteristics. A similar exercise can be performed for the various agents working in these centers.
Day Two: AI Deep Learning Expert
The biggest problem of a typical ML algorithm is its lack of feature representation.
You are provided with some extra data for your project. However, the data is not in the typical format of rows and columns but are transcripts based on the audio files containing the conversation between the complainant and the agent.
You are also provided with audio files without any transcripts. It is up to you to determine whether the audio files contain a positive or a negative conversation and on which topic.
Based on these conversations, you have to find if the complainant was satisfied with the agent’s response or not, what are the common problems faced by the agents that they require solving, etc.
This is where you dive one step deeper into artificial intelligence and enter the realm of Deep Learning.
You use deep learning to perform Natural Language Processing and particularly for Sentiment Analysis and Topic Segmentation.
For the audio files, you are required to create a Speech to Text algorithm. To perform all such tasks, you learn all these features using models known as Neural Networks. Here you use Artificial Neural Networks and use Training Dataset to learn a function. Technically, the setup you work in is Reinforcement learning, where the algorithm is ‘rewarded’ and ‘punished’ continuously to reduce the errors. Read this blog to learn more about Fundamentals Of Neural Networks & Deep Learning.
It is important to remember that in these two days, you perform multiple other tasks such as Feature Reduction through extraction and selection, Feature Construction through binning and encoding, Data Mining and Cleaning through missing value and outlier treatment, etc. (All this falls under the overall domain of Data Science!).
You may also like to read: How to Become an AI Engineer – Skills, Jobs & Salary
Day Three: Data Scientist
Finally, the culmination of all the Data Mining, Feature Engineering, Results of Statistical, Mathematical, Machine Learning, and Deep Learning models provide you with the necessary ingredients to move ahead and work as a Data Scientist.
It is essential to note that for convenience sake, I have not created distinctions between the role of a Data Scientist and a Data Analyst as it is a whole other debate with a lot of their tasks overlapping each other and have included the tasks performed by a data analyst under data scientist only.
Still, to give you some idea, a data analyst is responsible for collecting, processing, organizing, and mining the data, answering the question raised by the company by getting some insights using statistical and ML tools, and finally presenting them in the form of reports and other visual mediums.
On the other hand, Data Scientist handles highly voluminous data and is much more well-versed with the algorithms and tweaks them as required. They solve the asked questions, come up with unthought-of insights, and have business consideration as part of their work.
I like to think of the difference as the one between a policeman and a detective- both part of the law enforcement with some differences in their objectives and implementation of tools.
Now coming back to the project, the results of various models provide you with the answers such as the centers responsible for the positive and negative reviews, the factors most responsible for it, factors that affect each other, the number of clusters (groups) found among the service centers, agents, etc.
As said earlier, these are mere ingredients, and you use them to proceed deeper into the field of Data Science.
You now truly begin to analyze your results and give insights by solving questions such as what is happening in the service centers and its reason. You go a step further and provide information on what will happen if things move the way they are at present.
Thus, you perform predictive analysis such as Churn analysis, etc. You not only find the reasons for the problems but also suggest solutions for them. For example, you provide insights into what kind of agents should be hired, i.e., age groups, academic qualifications, etc.
Thus, Data Science not only requires coming up with mere numbers and results using AI systems but also analyzing these numbers to come up with a meaningful picture as for the company –average working hours, the average age of agents, the number of bad reviews for each service center won’t be of much use.
Having Domain knowledge is also required here as you will at times be stepping into the land of Business Analysis as, for example, when you find different clusters of member service centers, you may be required to advise the possible solutions for it where a center having low complaints and the average time taken to solve a complaint should be advised to be rewarded. The things done right there should be implemented to the group of centers where complaints and time duration to solve a complaint is high.
Also, the company’s needs, goals, and requirements are to be kept in mind, as maybe the company wants an effective strategy for performing a layoff and needs to let go specifically of those agents that are detrimental to the centers’ performance. In addition to these, it may require guidelines for their HR team as to what basis the agents should be hired. These aspects are more related to Data Science as a whole than particularly to Machine or Deep Learning.
In Data Science, one is also expected to have good report generation skills and, therefore, command over visualization, summary. Report creation is required, and tools such as Tableau, use of Python/R using Plotly/ggplot, MS Excel, Powerpoint, and a good command over a language are required.
Thus, Data Science requires to come up with the information about past (what and why some things were happening), present (what and why something is happening today), and future (what will happen if things are not changed and how things can be made better by changing what).
It also necessitates analyzing the data to come to with meaningful questions, insights, answers, and suggestions, and all the tasks performed to achieve these objectives in its totality makes it a part of Data Science where to come up with a solution requires a combination of Traditional Research knowledge, Math and Statistics Knowledge coupled with software knowledge such as Machine and Deep Learning, etc.
You may also like read: How to Become A Data Scientist? – Step By Step Guide
Summary
If in few words, the difference between Data Science, Machine and AI Deep Learning is to be explained, then ML is where we don’t program as such but provide the system with the input and the solution, which in turn gives us a function (program) which then can be used to come up with new solutions. It is generally used when the problems are complex and enough sets of conditions (rules) cannot be created manually. When the data is too large and statistical models can’t be used, ML also comes in handy as it can handle a large amount of data without much problem. Also, when the data/scenario is dynamic, and we are required to update our programming (conditions/rules), the ML is also helpful as it automates most of the tasks.
Deep Learning gets one step closer to the core of Artificial Intelligence and is even less statistical and mathematical when compared to ML and is used when there is a lack of feature representation or the problem is too complex ever for Machine Learning algorithms. Here there are multiple layers in the algorithm, with often each layer eventually specializing in solving a particular kind of task. It is often a high-level technique, and tasks mentioned earlier, such as Speech to Text, are mostly undertaken by a group of well-trained and experienced Deep Learning experts.
Data Science is where we come up with meaningful insights using the data. Now, as a Data Scientist, you may be required to use various tools to reach the destination, and Machine and Deep Learning is one of them. The focus now becomes on finding problems and attaining solutions. A Data Scientist may even ask an ML expert and a Deep Learning expert to provide certain results. Still, it will be the task of the Data Scientist to use those results in a meaningful way, though a Data Scientist is expected to know how to use Machine and Deep Learning algorithms to a good extent.
PG in Data Science course, Machine Learning, and Deep Learning AI are undoubtedly hot topics of today. Still, it is important to understand the key difference between them as knowing the difference will allow you to choose a suitable Data Science certification course path and goals ahead.
The above-mentioned difference barely scratches the surface; still, they are enough to give you a sense of differentiation between Machine Learning vs Deep learning and some clarity.
Hope this blog will help you to effectively move ahead with more clarity if you wish to learn Applied AI & ML.
You may also like to read:
2. Data Science Tutorial for Beginners – Definition, Components, and More
3. What Is the Future of Data Science and Artificial Intelligence?






1 Comment
Deep Learning is a subset of machine learning that creates artificial neural network algorithms to learn from large amounts of data to make intelligent decisions.