Almost all of us daily are leveraging the benefits of the meticulous Deep Learning models, which are wrapped under the covers of our smartphones. It starts from a simple auto-correction to asking Alexa for the daily news or score to a chatbot assisting us with our support queries and whether Facebook suggests us to tag our friends based on identifying the images.
These all are simple applications of Deep Learning models, and there are many more advanced applications of Deep Learning. Not to forget driverless and autonomous cars! All of these operate using the fundamentals of neural networks. Neural Networks are not a new age thing; they have been there for over 70 years now. In 1943, Warren McCullough and Walter Pitts proposed the first neural network, which had built “computational models for neural networks based on algorithms called threshold logic.”
This is great! But, then what is a Neural Network? And, how can we create it? Read on to find out more! In this article, we shall cover the fundamentals of neural networks, fundamentals of artificial neural networks, fundamentals of deep learning, how artificial neural networks relate to the biological neural networks, the components of the neural network, its architecture.
AnalytixLabs is India’s top-ranked AI & Data Science Institute and is in its tenth year. Led by a team of IIM, IIT, ISB, and McKinsey alumni, the institute offers a range of data analytics courses with detailed project work that helps an individual fit for the professional roles in AI, Data Science, and Data Engineering. With its decade of experience in providing meticulous, practical, and tailored learning. AnalytixLabs has proficiency in making aspirants “industry-ready” professionals.
Definition of Neural Networks
A Neural Network or Neural Net is a system of interconnected processing units called neurons.
Artificial Neural Networks (ANN) or Neural Networks is an integral part of Artificial Intelligence and the foundation of Deep Learning. ANN is the computational architecture consisting of neurons that mathematically represent how a biological neural network operates to identify and recognize relationships within the data.
Essentially Neural networks are non-linear machine learning models, which can be used for both supervised or unsupervised learning. Neural networks are also seen as a set of algorithms, which are modeled loosely based on the human brain and are built to identify patterns.
Ace AI with AnalytixLabs! 👨🏻💻
Explore our Agentic AI Course, Generative AI and AI for Managers and prepare yourself for the industry.
Explore our signature data science courses in collaboration with Electronics & ICT Academy, IIT Guwahati, and join us for experiential learning to transform your career.
Broaden your learning scope with our elaborate machine learning and deep learning courses. Explore our ongoing courses here.
Learn the right skills to fully leverage AI’s power and unleash AI’s potential in your data findings and visualization. Have a question? Connect with us here. Follow us on social media for regular data updates and course help.
The Basic Concept of Artificial Neural Networks
An artificial neural network (ANN) is a computing system designed to simulate how the human brain analyzes and processes information. It is the foundation of artificial intelligence (AI) and solves problems that would prove impossible or difficult by human or statistical standards.
Artificial Neural Networks are primarily designed to mimic and simulate the functioning of the human brain. Using the mathematical structure, it is ANN constructed to replicate the biological neurons.
A human brain has a decision-making process: it sees or gets exposed to information through the five sense organs; this information gets stored, correlates the registered piece of information with any previous learnings, and makes certain decisions accordingly.
The concept of ANN follows the same process as that of a natural neural net. The objective of ANN is to make the machines or systems understand and ape how a human brain makes a decision and then ultimately takes action. Inspired by the human brain, the fundamentals of neural networks are connected through neurons or nodes and is depicted as below:
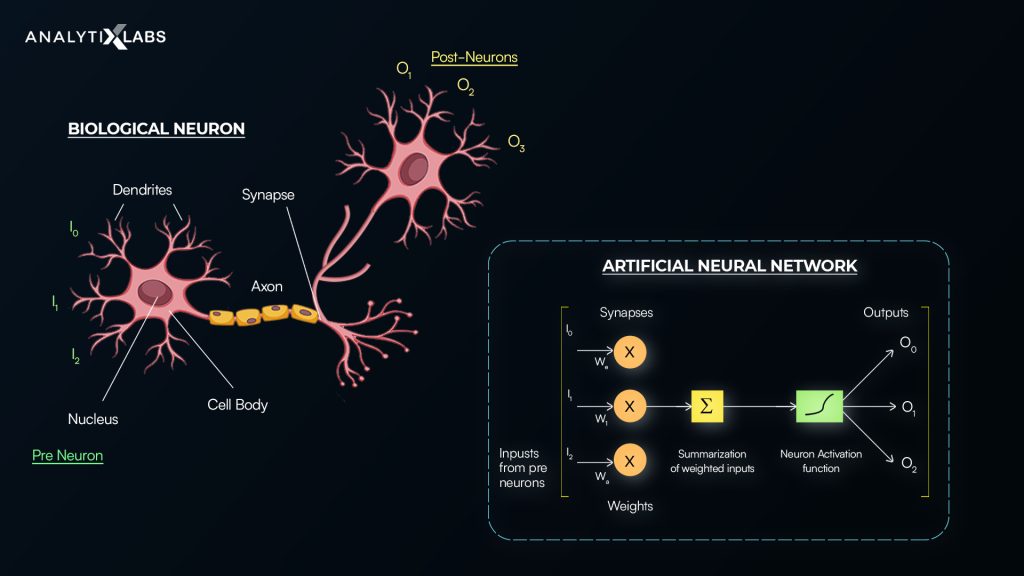 Source: encrypted-tbn0.gstatic.com
Source: encrypted-tbn0.gstatic.com
The similarities among the terminologies between the biological and the Artificial Neural Networks based on their functionalities:
| Biological Neural Network (BNN) | Artificial Neural Network (ANN) |
|---|---|
| Five Senses: via which receives the input | Sources of Data: the input is collected |
| Dendrites: is used to pass through the input | Wires or Connections: to pass the received inputs |
| Neurons/Nodes/Soma/Nucleus/Processing Unit: carries electrical impulses and transmits the information to other nerve cells | **Neurons/Nodes:**the unit that consolidates all the information and takes the decision |
| **Synapses:**means how the neurons talk to each other | Weights or the interconnections: it transforms the input data within the hidden layers of the network |
| **Axon:**carries nerve impulses away from the cell body. In short, it is a vehicle to channelize the output | **Output:**Output of the Neural Network |
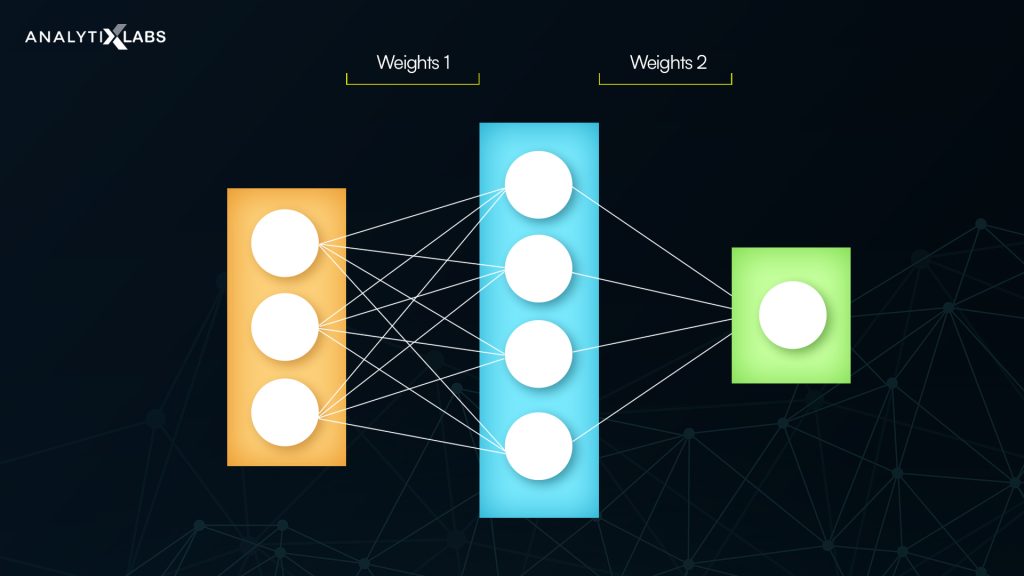
Components of Neural Network
The structure of the neural network depends on the problem’s specification, and it is configured according to the application. Though, in general, a neural network has the following structure, and the components of artificial neural networks which make the fundamentals of neural networks are:
- Layers: Input, Hidden, and Output layers
- Neurons
- Activation Function
- Weights and Bias
 Source: res.cloudinary.com
Source: res.cloudinary.com
Let’s see each of the fundamentals of artificial neural networks in detail below:
Layers
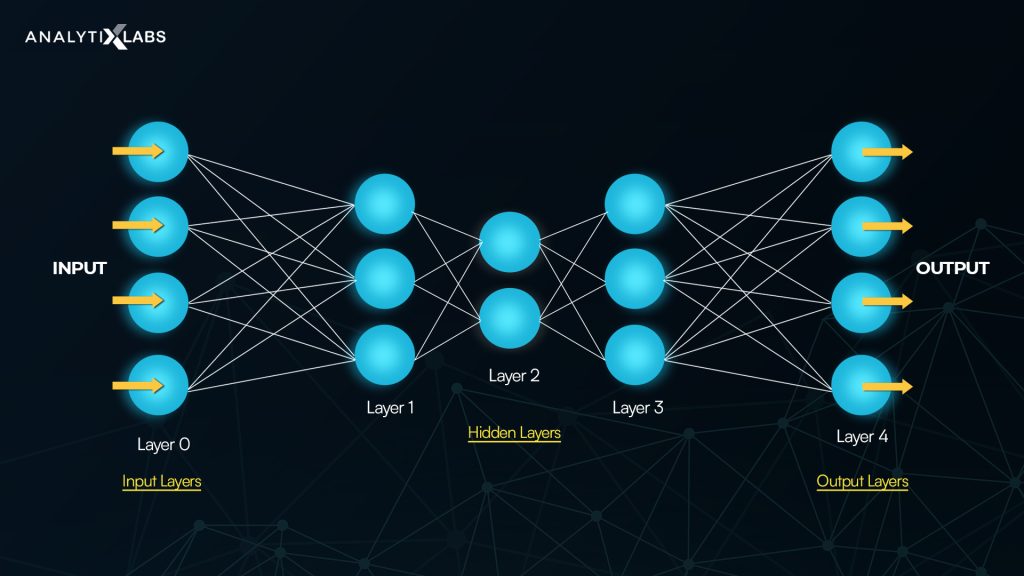
In a neural network, there are three layers: Input Layer, Hidden Layers, and Output layer.
The input layer consists of the inputs or the independent X variable known as the predictors. These inputs are collected from external sources such as text data, images, audio, or video files. In a natural network, these Xs are the information perceived from the sense organs.
The output layer results from the neural network; it could be a numerical value in a regression problem or a binary or multi-layer class for a classification problem. The output can also be the recognition of handwriting or audio voice or classified image or text in categories.
Apart from the Input and the Output layer, there is another layer in the Neural Networks, called the Hidden Layer, which derives the features for the model. There is one hidden layer in the above image, and the below image has three hidden layers.
- Single Layer Perceptron: The neural net with one single hidden layer is called the Single Layer Perceptron.
- Multilayer Perceptron: The neural net with more than one hidden layer and where each of the layers is connected is called the Multilayer Perceptron.
 Source: cs.stanford.edu
Source: cs.stanford.edu
The beauty of the Deep Learning models is that these neural nets implicitly create features that the model gets trained. Hence, feature engineering and extraction are automatic, which essentially differentiates Deep Learning vs. Machine Learning and suitable applications on computer vision and are scalable with large data.
Moving on to the next building block…
Neurons
As seen above, neurons are the primary and basic processing unit in the neural network. It receives information or data, performs simple calculations, and then passes it further. The neurons are in the hidden and the output layers. The input layer doesn’t have any neurons; the circles in the input layer represent the independent variables or the Xs.
The number of nodes in the output layer depends on the kind of the business problem:
- Regression: In case to predict the stock prices or in other words when the nature of the output is continuous, then there will be one node in the output layer like the above image.
- Classification: In the case of a classification problem, the nodes in the output layer are equal to the number of the classes or the categories. For binary classification, we can either have one or two nodes in the output layer.
The number of neurons in the hidden layers is subject to the user. The architecture of the neural net is configured based on the problem at hand and is determined by the user. The input layer is always predefined, and the output is the goal of the network that is also prefixed.
It is the number of hidden layers and the number of neurons that form the part of the hyperparameters. It is so because these exact parameters create the features, and a small tweak in these can significantly impact the output.
Weights and Bias
The inputs from the input layer are connected to each neuron of the first hidden layer. Similarly, the neurons of this hidden layer are connected with the subsequent layers’ neurons. In a nutshell, the output of one layer becomes the input of another layer. Any given neuron can have many to many relationships with multiple inputs and output connections. Weights and bias are applied to each of the connections during the nodes’ transmission between the layers.
In the biological neural network, the synapses indicate the strength of the neurons. In the same manner here in the neural networks artificial intelligence, the weights control the strength of the connections between the neurons.
These weights represent the relative importance of the neural net, and meaning indicates how much precedence the input X or the subsequently derived neurons will have on the output. This will naturally lead to the neurons with the higher weight will have more influence in the next layer, and ultimately, the neurons with not significant weights will get dropped out. Therefore, the weights or the connections direct the neural net.
Bias is an additional input to each layer starting from the input layer. The bias is not dependent nor impacted by the preceding layer. In simple words, bias is the intercept term and is constant. It implies that even if there are no inputs or independent variables, the model will be activated with a default value of the bias.
The weights and biases are the learnable parameters of the model. In the first iteration or the initialization process, the weights are randomly set up or assigned and optimized to minimize loss or error.
Activation Function
In the above section, we saw that the weights control the transmission of the neurons, and adding the bias makes the nodes a linear combination of weights and bias and can be depicted as:
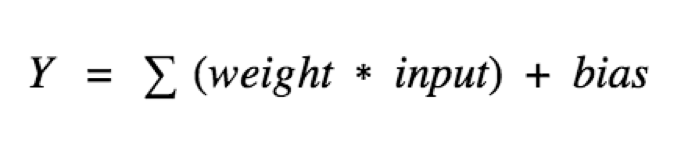
Currently, the equation for the neural network is of a linear regression model where every neuron will only perform a linear transformation for the combinations of the weights and the bias. Now, this will be an overly simplified neural network. However, it will not perform any complex computations or detect any patterns. To prepare the model for such complexity, we need transformation, where activation functions enter the story.
Activation Functions are an integral part of Neural Networks. The purpose of the activation function is to bring non-linearity to the net by applying the transformation. Activation functions are also known as the ‘Squashing function.’
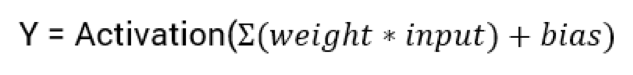
Internally, the neural networks artificial intelligence with all its components applied looks like below:
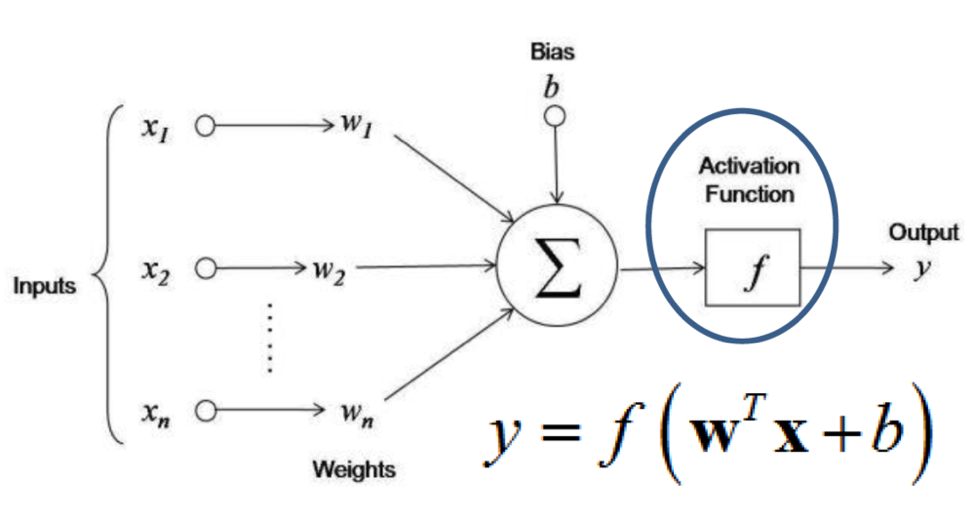 Source: images.squarespace-cdn.com
Source: images.squarespace-cdn.com
There are different activation functions available depending upon their functionality and the layer to be applied upon. To know more about these functions and their applicability can refer to these blogs here and here.
You may also like to read: Components Of Artificial Intelligence – How It Works?
How Are Neural Networks Used in Deep Learning?
Before seeing why the Neural Network is important and used in Deep learning, let’s understand what Deep Learning is and the fundamentals of deep learning.
Based on the artificial neural networks, deep learning is a segment of Machine Learning, and Machine Learning is a subset of Artificial Intelligence. A deep learning algorithm is a complex concept representing through a hierarchy of simpler concepts. Deep Learning has neural networks which perform unsupervised learning from unstructured data. The learning can be either unsupervised, supervised, or semi-supervised.
The learning in this field is using the complex structure of artificial neural networks, which comprise multiple layers, including input, output, and the hidden layers making the learning ‘deep.’ Each of the layers consists of the nodes converting data from one layer to another and activating the network for solving specific problems.
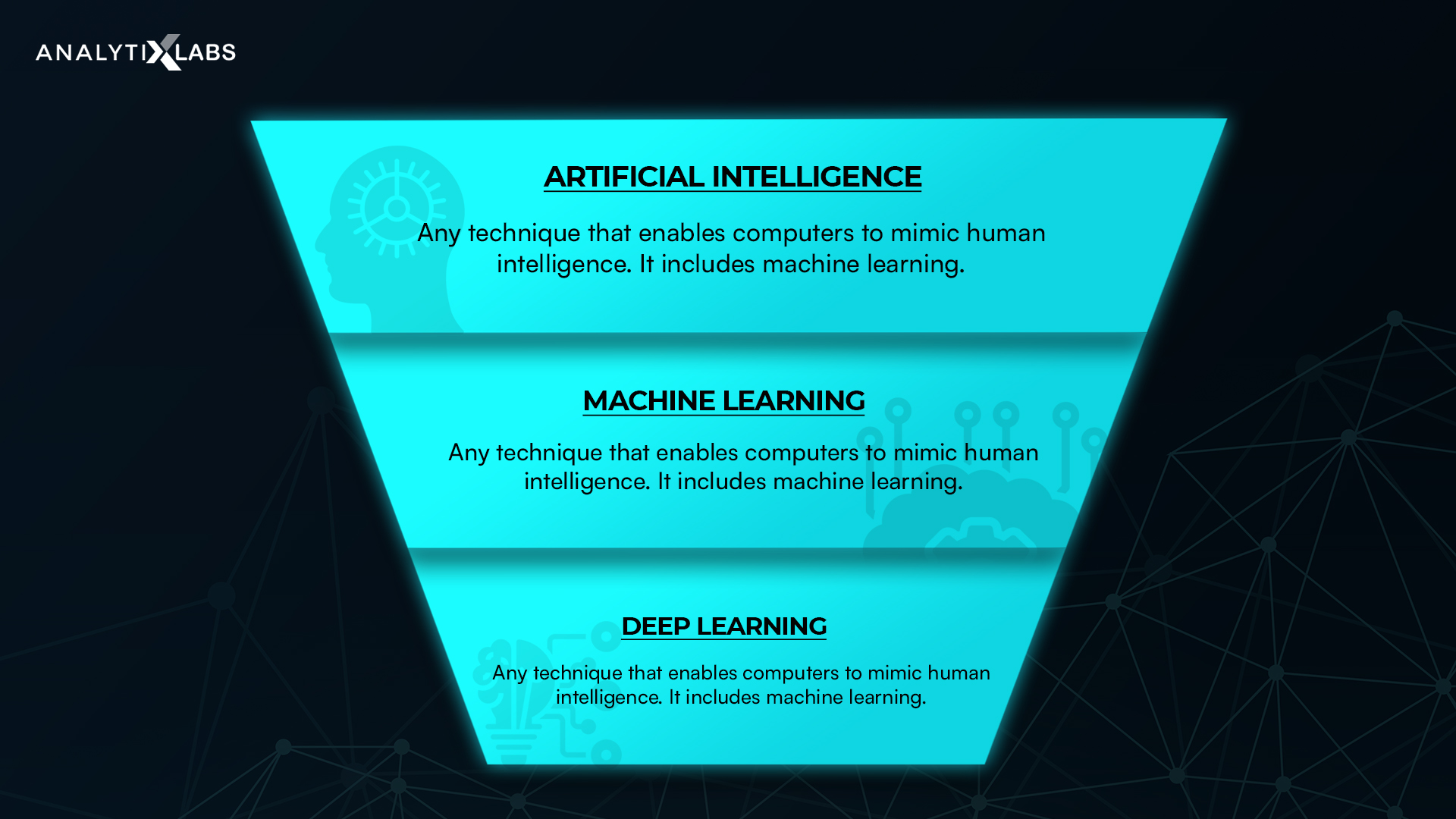 Source: docs.microsoft.com
Source: docs.microsoft.com
Why is Deep Learning so important, and how does it empower the AI models?
- The deep learning models work on their and automatically uncover patterns as are based on the artificial neural networks, which are designed to replicate and learn from the human brains. Unlike the machine learning models where need to manually extract features, the machines using the deep learning models are trained themselves to perform the task, learn via their own data processing and implicitly drive features from the training data.
 Source: i.pinimg.com
Source: i.pinimg.com
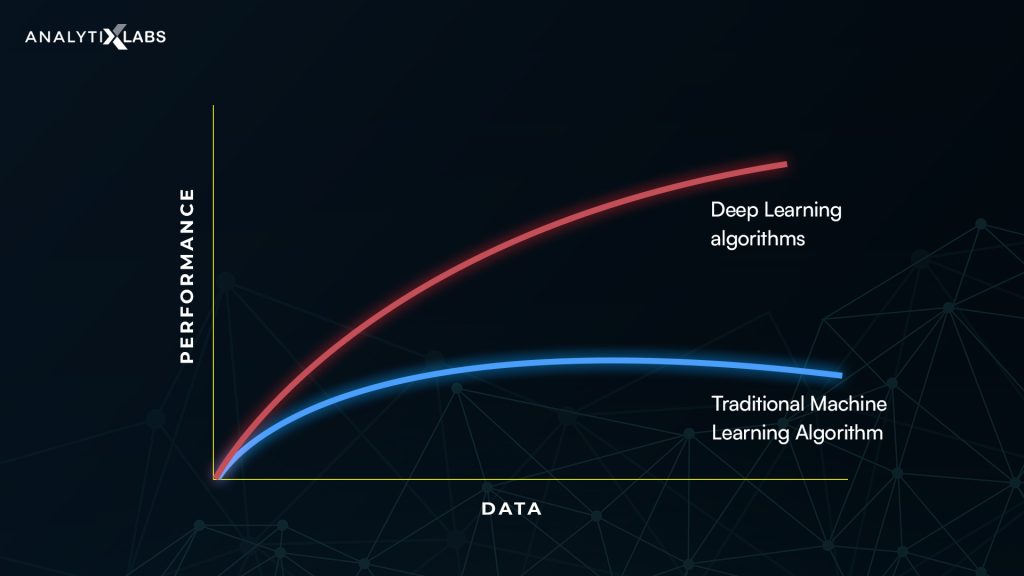
- To learn better and extract features from the data the deep learning models require large amounts of data. The image below shows the deep learning models perform better i.e are more accurate as compared to the machine learning models, which plateau with more data.
- These multi-layered neural nets have very high computing power and require GPU to run upon as they are trained on large datasets.
 Source: bluehexagon.ai
Source: bluehexagon.ai
There are numerous neural networks available in Deep Learning architecture. Some of the most commonly used models and their key applications are:
- Feedforward Neural Network (FNN)
The simplest type of ANN is Feedforward Neural Network (FNN). In FNN, the information travels only in one direction from the input to the output layer. Each of the layers is fully connected with all the nodes in the layer before and after. In this network, there may or may not be hidden layers. The network here does not form a loop. FNN is used for classification, face recognition, speech recognition, computer vision.
- Convolutional Neural Network (CNN)
A feedforward artificial neural network, Convolutional Neural Network (CNN), is a variation of the multilayer perceptrons to use minimal amounts of preprocessing. It takes the inputs in batches like a filter, assigns relative importance to the weights and biases to various aspects or objects in the image, and differentiates one from the other. The network can remember the images in parts and compute the operations.
CNN has a unique architecture focussing on extracting complex features from the data at each layer to determine the output. The output of CNN is a single vector with probability scores, and the class with the highest probability is the prediction of the neural net.
CNN is commonly used to extract information from unstructured data such as image and video data. It is used for video, signal, image recognition, visual imagery analysis, and recommender systems.
- Recurrent Neural Network (RNN)
A recurrent neural network stores the output of a layer and feeds it back to the input layer to predict the layer’s outcome. This network uses the internal state (or memory) to process the variable-length sequences of inputs and hence can handle the arbitrary input or output lengths. The neurons of this multi-layered neural network have loops in their connections.
RNN is applied to perform complex tasks, including providing image captions, time series forecasting, learning handwriting, language recognition, chatbots, fraud detection, detection of anomalies, and are most suitable to process sequences of inputs.
- Generative adversarial network (GAN)
Generative adversarial networks (GANs) are algorithmic architectures that use two neural networks: generator and discriminator, to generate content. Both of these networks are trained simultaneously, and each network is competing against each other, aiming to create new, synthetic instances of data that can be taken as real data. GANs are widely used in image generation, video, and voice generation and solve image-to-image translation and age progression problems.
- Autoencoders
Autoencoders learn the data codings in an unsupervised manner. The objective of an autoencoder is to learn a representation or encoding for a set of data. These are mostly applicable for dimensionality reduction by training the network to ignore signal “noise” and learning generative data models. It is applicable in image reconstruction and image colorization.
For more in-depth and practical knowledge of Neural Networks, do chekout Deep Learning with Python Course
FAQs – Frequently Asked Questions
Ques 1. What are 3 major categories of neural networks?
Ans. The 3 major types of neural networks are:
- Artificial Neural Networks (ANN)
- Convolution Neural Networks (CNN)
- Recurrent Neural Networks (RNN)
Ques 2. What are the different types of neural networks?
Ans. The types of Neural Networks are:
- Single Layer Perceptron
- Feed Forward Neural Network
- Multilayer Perceptron
- Recurrent Neural Network (RNN)
- Convolutional Neural Network (CNN)
- Long Short-Term Memory (LSTM)
- Autoencoder
- Radial Basis Function (RBF)
- Gated Recurrent Unit (GRU)
- Sequence to Sequence models
- Modular Neural Network
- Hopfield Network
- Boltzmann Machine
- Deep Belief Network
Planning to learn Artificial Intelligence? Here is a Complete Guide on the Artificial Intelligence Course Syllabus
Ques 3. What are the 3 components of the neural network?
Ans. The 3 components of the Neural Network are:
- Input Layer
- Hidden Layers
- Output Layer
Ques 4. How is the structure of a Neural Network determined?
Ans. The structure of a neural network is based upon:
- Layers: Input, Hidden, and Output
- Number of the neurons and the number of the hidden layers
- Weights and biases
- Activation Function
Ques 5. What is a Neural Network example?
Neural networks are vast applications, including path detection for self-driving cars, web classification, spam classification, image classification, facial, speech, pattern recognition, handwriting recognition, machine translations, chatbots, medical diagnosis, fraud detection, risk assessment, prediction of prices. An example of the neural network built for classifying the images of animals can recognize the image of a dog from a cat.
You may also like to read:
1. Top 40 Deep Learning Interview Questions and Answers
2. Top 50 Data Science Interview Questions And Answers
3. Top 60 Artificial Intelligence Interview Questions & Answers