How many times has it happened that you have data at hand, but you end up not taking action on it because you thought it could wait? Let’s say you run an eCommerce website and you have noticed your users are abandoning their carts right after reaching the payment page. Now, as an eCommerce portal, this is crucial data that can almost make or break your business. Your analytics tool has given you the data, but you are not yet aware of this data. This can happen when we set up an analytics tool and review reports every week or twice a week. When you finally see the data in the report, hours or probably days have passed. By the time you investigate the report and reach the real reason for the friction, you have lost hundreds of sales and a chunk of your loyal customers.
This is what happens when data insights come too late. We are living in an always-digital world where delayed insights mean lost opportunities. This is where real-time analytics come in. It enables businesses to capture, process, and act on data the moment it is generated.
In this article, we will discuss what is real-time data analytics, types of data analytics, techniques, and real-time data examples.
What is Real-time Analytics?
Real-time analytics eliminates the lag between data collection and decision-making. Instead of reviewing reports hours or days later, organizations can monitor live dashboards, detect anomalies instantly, and respond in the moment – whether that means resolving a checkout glitch, rerouting a delivery, or optimizing the ad spend mid-campaign. It’s the difference between reacting to the past and responding to the present.
To understand real-time data analytics, you must know what is real-time data.
What is real-time data?
Real-time data is the information that is captured and processed continuously as events occur. It flows from multiple sources like website clicks, social media activity, sensors, transactions, or IoT devices, and updates instantly as new information arrives.
For instance, a ride-hailing app tracking driver locations, a stock trading platform updating prices by the second, or a logistics company monitoring live shipment status – all rely on real-time data.
The defining feature is low latency. There is minimal delay between when the data is created and when it is available for analysis. The faster the system processes this data, the more immediate and accurate the insights become.
At the heart of real-time analytics lies the in-memory database (IMDB).
What is an In-Memory Database (IMDB)?
In-memory Database (IMDB) is a technology designed for speed and efficiency. Unlike traditional databases that store data on physical disks, in-memory databases keep it directly in a system’s main memory (RAM). This allows data to be retrieved and analyzed almost instantly, without the read/write delays of disk access.
Modern IMDBs such as SAP HANA, Redis, and SingleStore (MemSQL) are built to handle high-velocity data streams and perform complex computations in milliseconds. Organizations can process millions of transactions per second, making these ideal for applications like fraud detection, personalization engines, and IoT monitoring.
For instance, popular OTT platform Netflix thrives on real-time personalization.
Every time you log in, the platform instantly tailors what you see – from recommended shows to the order of thumbnails – based on your viewing history, preferences, and behavior.
Behind this seamless experience lies a complex data infrastructure powered by in-memory databases and real-time analytics pipelines. Netflix uses technologies like Redis and Apache Ignite to store and retrieve user data at lightning speed. Because this data lives in memory rather than on disk, the recommendation engine can instantly process millions of interactions like clicks, views, and pauses as they happen.
This helps Netflix to deliver hyper-personalized content suggestions in real time, keeping users engaged and improving watch time. Without in-memory computing, such rapid, individualized experiences would suffer from delays, breaking the illusion of a responsive, intuitive platform.
For instance, I, for one, love Korean dramas and binge-watch them whenever I find a good one. Netflix knows that! Which means, my Netflix home screen looks like a Korean drama festival – dramas belonging to the specific genres that I watch. And most of the time, the recommendation carousels help me decide on my next binge-watch material.
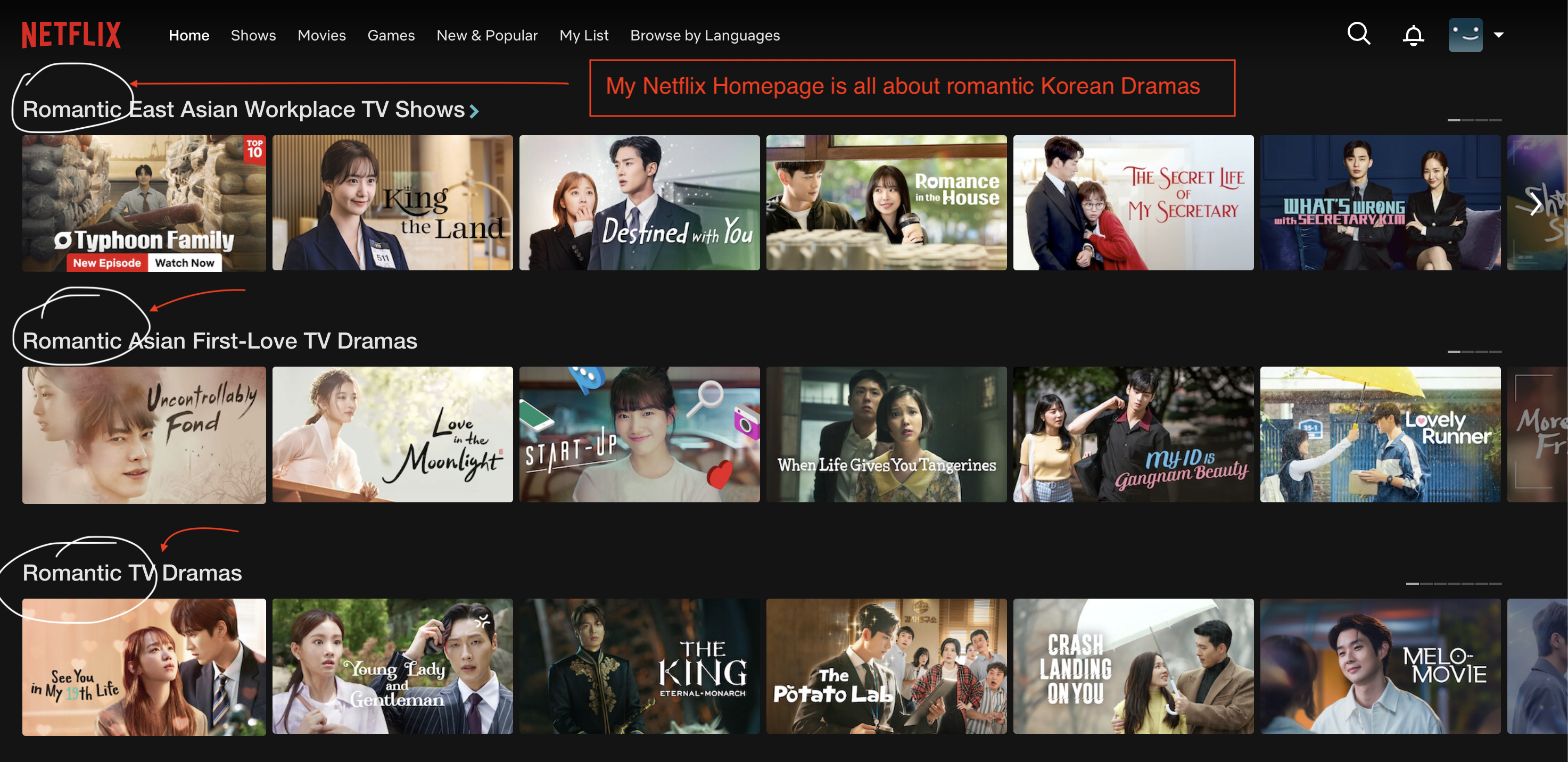
In simple terms, in-memory databases power the speed behind real-time analytics, ensuring businesses can not only see what’s happening now but also act on it before opportunities disappear.
Technologies that make real-time analytics possible
Real-time analytics allows you to run ad hoc queries on large data sets and monitor business changes as they happen. This means you can make decisions based on the most up-to-date information available. Having access to live insights is crucial for creating strategies that are agile and fail-safe. Let’s take a look at the technologies that make real-time analytics possible.

1. Processing in memory (PIM):
Processing in Memory (PIM) occurs when a processor is integrated with RAM – typically SRAM or DRAM – on a single chip. Unlike traditional business intelligence systems, where data is stored on disks as multi-dimensional cubes or tables before queries are run, PIM takes a different approach. It loads the data directly into memory, eliminating the need for extensive data modeling, table design, and cube building. This drastically reduces query and processing time, making data analysis significantly faster.
2. In-data analytics:
As the name implies, in-data analytics embeds the analytics logic directly within the database itself. This approach removes the need to extract, transform, and move data into a separate analytics system. The result is faster processing and high-speed analysis since the computation happens right where the data resides.
3. In-memory analytics:
In-memory analytics works by querying data that’s stored directly in RAM, instead of relying on slower disk-based storage. Because the data lives in memory, query response times are dramatically reduced. When combined with Processing in Memory (PIM), in-memory analytics allows data to be both stored and analyzed in the same place, bypassing multiple transactional steps and saving valuable time.
4. Massive parallel programming:
Massive Parallel Processing (MPP) uses multiple processors that work simultaneously on different parts of the same program. These processors communicate with each other through a messaging interface to coordinate their work. While setting up MPP can be complex since it involves dividing a single database across multiple processors, the payoff is substantial. It’s especially effective for large-scale applications like data warehouses and decision support systems that require heavy computational power.
How to Build a Real-Time Data Analytics Workflow
To understand how real-time data analytics works, it helps to see the process behind it. A real-time analytics workflow converts fast-moving data into insights you can act on immediately. It’s the foundation of modern big data and real-time analytics systems used by global enterprises today.
There are four steps in building a real-time data analytics workflow:

- Data ingestion: The first step is data ingestion, where continuous streams of real-time data are collected from multiple sources. These can include websites, IoT sensors, mobile apps, and transaction systems
- Stream processing: Next comes stream processing, where incoming data is filtered, enriched, and analyzed as it flows in. This is the step that transforms raw inputs into actionable signals.
- Real-time storage: Processed data is then stored in an in-memory database or a low-latency data store for fast access. These systems, such as Redis, SAP HANA, or Cassandra, allow rapid querying and updates.
- Visualization and action layer: The final stage is the visualization and action layer, where insights turn into business outcomes. Dashboards built using Tableau, Power BI, or Grafana show live performance indicators in one place.
We will now understand these four steps using Uber’s example of capturing GPS and trip data from millions of rides every second.
Let’s start.
The starting point is to generate data before the above four steps commence. Every Uber driver and rider uses a GPS-enabled smartphone app. The moment a driver goes online, the app begins transmitting telemetry data that includes latitude, longitude, speed, bearing, and timestamp to Uber’s backend systems.
- These updates occur roughly every few seconds, meaning that with millions of active users, Uber receives millions of GPS pings per second.
- Each data packet also contains metadata like driver ID, trip status (waiting, en route, completed), and app version.
- Additional data, such as network latency, battery levels, and location accuracy, help the system adjust how frequently updates are sent, conserving bandwidth while maintaining precision.
This stage transforms each mobile phone into a real-time data sensor, constantly feeding the platform with fresh geospatial information.
1. Data ingestion and Stream processing
Once the GPS and trip data are generated, they enter Uber’s data ingestion pipeline, built primarily on Apache Kafka. Kafka acts as the backbone for all event streaming, like capturing, queuing, and distributing millions of messages per second from rider and driver devices.
The next layer, Apache Flink or Apache Samza, performs stream processing that includes applying logic to data as it flows in. This step filters noise (like duplicate or outdated signals), enriches the data (for example, by mapping coordinates to street names), and aggregates information for fast decision-making.
For example:
- When a rider requests a trip, Flink helps calculate the nearest available drivers in real time.
- The system then pushes this processed data to Uber’s matching service, which determines the most optimal driver based on proximity, estimated time, and demand.
Because this happens in milliseconds, the rider experiences an almost instant “driver found” response: a perfect example of what real-time data is in action.
2. In-memory and Distributed data storage
Processed streams are stored in a combination of in-memory databases and distributed data systems that balance speed with durability.
- Redis is used for maintaining rapidly changing “state data,” such as which drivers are active in a given city, their current coordinates, and estimated arrival times. Since Redis stores data in memory rather than on disk, it allows sub-millisecond read and write speeds, ideal for time-sensitive operations.
- Cassandra, a distributed NoSQL database, stores larger volumes of semi-structured data, such as trip histories, fare data, and regional traffic patterns. Its horizontal scalability allows Uber to handle thousands of concurrent requests globally without lag.
This architecture ensures Uber can simultaneously handle real-time reporting for current operations and long-term analytics for optimization. For example, when a driver completes a trip, data instantly flows to Redis for immediate updates to availability, while Cassandra archives the trip details for later analysis and billing.
3. Real-time analytics and decision engine
At this stage, Uber’s real-time analytics engine uses the live data to power dynamic decision-making. It combines machine learning models and rules-based systems that continuously analyze driver behavior, demand patterns, and road conditions.
Key functions include:
- Dynamic Pricing (Surge Pricing): When local demand exceeds supply, Uber’s pricing algorithm automatically adjusts fares. It does this using live trip and location data processed through in-memory analytics models.
- ETA Prediction: The system uses big data and real-time analytics to calculate estimated arrival times, factoring in current traffic, speed patterns, and driver availability.
- Driver Matching: Algorithms analyze current driver positions and trip status to assign the nearest, most efficient driver to each request.
These capabilities rely on constant low-latency computation, where even a few seconds of delay could result in poor matches, longer wait times, and reduced satisfaction.
4. Visualization and monitoring
Uber’s operations teams use real-time dashboards and monitoring tools to track performance metrics worldwide. These dashboards display live information such as:
- Active trips per region
- Average driver response time
- Surge-pricing areas
- System anomalies or connectivity issues
Tools like Grafana and custom-built internal analytics solutions visualize data flowing in from the ingestion and processing layers. Operations teams can instantly detect spikes in demand or outages in specific regions and take corrective action.
For instance, during a citywide event or festival, Uber can deploy more drivers dynamically or adjust pricing models within minutes — all based on real-time reporting.
Uber’s data infrastructure is a textbook example of how to integrate real-time data ingestion, in-memory databases, and massive parallel processing to create a self-correcting and responsive system. This architecture highlights the power of real-time analytics platforms. It shows how real-time data can transform complex, global operations into smooth, intelligent experiences.
Now that we know the steps to build a workflow, let us look into the real-time analytics techniques.
Real-time Analytics Techniques
Real-time analytics techniques help in handling high-volume datasets fast and make split-second decisions. Each technique or method plays a specific role – from processing data streams and storing them efficiently, to identifying patterns, reacting to events, and learning from them continuously.

Let us now understand the core techniques using the global eCommerce platform, Amazon, as our example.
1. Stream processing
Stream processing is the backbone of real-time analytics. It facilitates continuous ingestion, filtering, and analysis of data while it is being generated instead of after it is stored.
It analyses live data streams like transactions, clicks, or sensor readings, the moment they occur, instead of batch processing.
How it works?
Stream processors like Apache Kafka, Apache Flink, or Amazon Kinesis receive data from multiple sources like apps, sensors, or APIs, and apply transformations or logic in motion. They filter out noise, aggregate values, and trigger alerts or actions based on predefined conditions.
For instance, Amazon uses stream processing extensively through its AWS Kinesis Data Streams. When millions of shoppers browse or purchase items, data about clicks, searches, and orders is streamed instantly. Amazon analyzes this live data to adjust recommendations, update product rankings, and even modify pricing dynamically in real-time.
Stream processing can help businesses in detecting fraud, optimizing logistics, or tracking customer behaviour as it happens.
2. In-memory computing
In-memory computing stores data in RAM instead of traditional disk-based storage, allowing ultra-fast access and processing. This eliminates latency caused by slow read/write operations.
How it works?
When data is loaded into an in-memory database like SAP HANA, Redis, or Amazon ElastiCache, queries and computations can be performed thousands of times faster than from disk. This makes it ideal for scenarios where speed and responsiveness are critical.
For instance, Amazon leverages in-memory databases (like Redis and DynamoDB Accelerator) to deliver lightning-fast recommendations and personalized product listings. When a customer views an item, related product suggestions are fetched from memory instantly, based on their behavior and purchase history. This seamless experience keeps users engaged and increases conversion rates.
In-memory computing enables businesses to analyze streaming data, run predictive models, and deliver results immediately without waiting for batch updates.
3. Complex Event Processing (CEP)
Complex Event Processing (CEP) identifies patterns, correlations, or anomalies across multiple data streams in real-time. It not only looks at a single data point but also combines multiple events to understand broader situations and trigger intelligent actions.
How it works?
CEP systems like Esper, IBM Streams, or AWS IoT Events define rules that detect when specific event patterns occur. For example, if a user adds a product to the cart, doesn’t purchase within 10 minutes, and returns later, it will trigger a discount offer.
For instance, Amazon uses CEP within Amazon Personalize and AWS IoT Events to detect patterns in user interactions. If a customer frequently browses certain items without buying, the system recognizes this pattern and sends personalized discounts or reminders.
In logistics, CEP monitors delivery sensor data, such as if a temperature-controlled shipment rises above a threshold, an alert is triggered instantly.
CEP is essential in industries that need proactive responses, such as financial trading (detecting suspicious transactions), telecom (network fault prediction), or retail (cart abandonment recovery).
4. Edge computing
Edge computing processes data closer to its source, i.e., at the ‘edge’ of the network, rather than sending everything to a central cloud or data center. This minimizes latency and bandwidth usage, enhancing faster local decisions.
How it works?
Edge devices like routers, sensors, or IoT gateways collect and pre-process data locally. Only essential insights are transmitted to the cloud. This approach is especially useful for time-sensitive operations like autonomous vehicles, factory automation, or smart retail systems.
For instance, Amazon Go stores rely on edge computing to power their “Just Walk Out” experience. Cameras and sensors inside the store track customer movements, product picks, and shelf interactions. Data is processed locally on edge servers to identify which items are taken, and the system automatically bills the customer as they leave without any checkout process.
Edge computing allows businesses to act on real-time data even in environments with limited connectivity. It improves reliability and reduces dependency on centralized servers.
5. Machine learning models
Machine learning (ML) models use algorithms to analyze real-time data and make predictions or decisions automatically. When combined with streaming data, ML enables systems to learn continuously and adapt instantly to new information.
How it works?
Trained ML models are deployed on real-time analytics platforms or edge devices to evaluate live data streams. For example, a recommendation model can instantly update suggestions based on recent clicks or purchases.
In the case of Amazon, it integrates ML models across nearly every business layer, from real-time recommendation engines to predictive logistics.
- Amazon.com uses ML to suggest products based on your browsing and buying behavior in real time.
- AWS CloudWatch uses ML to detect anomalies in infrastructure performance instantly.
- Amazon Robotics uses ML on streaming sensor data to optimize warehouse movement and reduce delays.
By analyzing live data streams, Amazon continually fine-tunes its systems and improves accuracy, efficiency, and customer satisfaction.
Real-time analytics focus on speed and responsiveness, but it is just one dimension of a broader data analytics landscape. To fully understand the impact of real-time analytics, you must understand the different types of data analytics. Each type serves a unique purpose in the decision-making journey. Together, they help businesses evolve from reactive insights to proactive intelligence.
Let us look at the different types of analytics and understand how they work in harmony with real-time systems.
Types of Data Analytics and How They Work with Real-time Systems
Each data analytics type creates a different layer that allows data teams to design systems that not only react to live data streams but also uncover trends, diagnose causes, and optimize outcomes using historical and predictive intelligence. There are four types of data analytics:
- Descriptive Analytics
- Diagnostic Analytics
- Predictive Analytics
- Prescriptive Analytics
Descriptive analytics
Descriptive analytics answers the question, “What happened?” It focuses on summarizing and visualizing historical and current data to understand trends, patterns, and performance. This type of analytics is often the first step in any data strategy, providing the foundation for deeper exploration.
Descriptive analytics relies on data aggregation, dashboards, and visualization tools like Tableau, Power BI, or Looker. It pulls together data from multiple sources (sales, website traffic, campaigns, etc.) and displays it in an understandable format, such as charts, KPIs, or summaries.
When combined with real-time data, descriptive analytics evolves into real-time reporting. Instead of viewing yesterday’s metrics, businesses can see what’s happening right now – active users, conversion spikes, or system alerts. For example, large ecommerce brands like Amazon use real-time descriptive dashboards to monitor live order volumes and delivery status across regions. This allows managers to make immediate decisions, such as reallocating delivery resources when certain hubs experience unexpected demand.
Also read: Data Analytics in eCommerce: How Analytics Help in eCommerce Growth Strategy
Diagnostic analytics
Diagnostic analytics answers, “Why did it happen?” It digs into the data to identify causes, correlations, and anomalies behind observed trends. This type of analytics uses techniques like drill-down analysis, data mining, and correlation analysis to uncover relationships between variables. For example, if customer engagement drops, diagnostic analytics investigates whether the cause lies in pricing, website experience, or product availability.
When supported by real-time data streams, diagnostic analytics can identify issues as they emerge. For instance, if there is a sudden global surge in search queries to check if Instagram is down, diagnostic tools can immediately correlate this behavior with specific server errors or API failures. Instead of waiting for post-event analysis, businesses can detect and correct problems instantly.
For instance, Amazon’s AWS monitoring systems use real-time diagnostic analytics to detect performance bottlenecks in infrastructure. The system identifies which server or region is affected and automatically reroutes traffic to maintain uptime, preventing small glitches from becoming major outages.
Predictive analytics
Predictive analytics answers the question, “What is likely to happen next?” It uses statistical models, machine learning algorithms, and historical data to forecast future trends or behaviors. They analyze patterns in past and present data to estimate probable outcomes, such as customer churn, demand spikes, or fraud likelihood. These models are trained using large datasets and continuously refined with new data inputs.
Real-time data enhances predictive accuracy by feeding models with the latest information. This allows forecasts to adapt dynamically as conditions change. For example, Amazon’s recommendation engine combines predictive analytics with real-time behavioral data. As customers browse, the system instantly predicts which products they’re most likely to buy next, updating suggestions in real time. This fusion of big data and real-time analytics turns static predictions into live, evolving recommendations.
Prescriptive analytics
Prescriptive analytics goes one step further to answer, “What should we do next?” It uses optimization algorithms, machine learning, and simulation techniques to recommend the best possible action among several options. It evaluates potential decisions based on goals, constraints, and predicted outcomes. They can even automate responses, such as adjusting pricing, rerouting deliveries, or changing ad placements, depending on the scenario.
When powered by real-time data analytics, prescriptive models can make immediate, context-aware decisions. For example, Amazon’s logistics network uses prescriptive analytics to optimize delivery routes. As live traffic, weather, and order data stream in, the system automatically recalculates the most efficient routes for drivers, ensuring faster deliveries and reduced costs. This combination of live data with intelligent decision-making transforms analytics from reactive to self-adjusting intelligence.
| Analytics Type | Key Question | Focus | Works Best With | Example at Amazon |
|---|---|---|---|---|
| Descriptive | What happened? | Summarization | Real-time dashboards | Monitoring live sales and orders |
| Diagnostic | Why did it happen? | Root cause analysis | Streaming anomaly detection | Detecting infrastructure issues |
| Predictive | What will happen? | Forecasting | Real-time behavioral data | Predicting customer purchases |
| Prescriptive | What should we do? | Action recommendation | In-memory analytics & automation | Optimizing delivery and pricing |
Is Real-Time Analytics the Fifth Type of Analytics?
No, real-time analytics is not considered the fifth type of analytics. There are four types of data analytics that we have already discussed above. Real-time analytics enhances the traditional four types of analytics. It answers when and how fast insights are produced and acted upon. It is about timing and responsiveness, and is devoid of any analytical purpose, unlike the four traditional analytics.
To make it more simplified, whether you opt for batch analytics or real-time analytics, you will have the scope to perform any of the four traditional analytics. So, instead of replacing the traditional analytics framework, real-time analytics run across all four types, facilitating faster and more adaptive decision-making.
How Real-Time Analytics Works in Big Data Environments
Organizations generate huge volumes of information every second that includes app interactions, sensor readings, financial transactions, and clickstreams. Managing this scale and velocity requires more than traditional data analytics. This is where we need real-time analytics.
Real-time analytics has the power to capture, process, and analyze data while it is being created. When integrated with big data systems, real-time analytics becomes a powerful engine that turns continuous data flows into instant, actionable insights. Here’s how it works in big data environments:
Step 1: Data generation and collection
Every big data environment starts with data generation that includes structured and unstructured information from multiple sources (web, IoT sensors, social media, machine logs, and connected devices).
Step 2: Data ingestion
Once the data is generated, the next step is to move the data from various sources into a centralized pipeline. In a big data ecosystem, this typically happens using streaming platforms such as Apache Kafka, Apache Pulsar, and similar. These systems act as high-speed conveyors for real-time data streams, making sure that millions of small messages can be transmitted and queued with minimal latency. At this point, the system ensures that no data is lost, duplicated, or delayed, which is crucial for reliable insights.
Step 3: Stream processing
In this step, the data flows into the stream processing layer, where it is filtered, transformed, and analyzed in motion. This is where raw data becomes meaningful insights. Tools like Apache Flink, Google Dataflow, and Apache Spark Streaming enable real-time filtering, data enrichment, data aggregation, and event correlation. In big data environments, this layer handles massive parallel processing, running thousands of computations at once.
Step 4: Storage in real-time databases
Once processed, data needs to be stored efficiently for fast access. This is handled by in-memory databases and low-latency stores like Redis, Cassandra, HBase, and SAP HANA. These systems allow real-time read and write operations, enabling dashboards, applications, and automation tools to retrieve insights instantly. In contrast to traditional databases, which rely on disks, in-memory systems store data in RAM, making it possible to query millions of rows in milliseconds.
Step 5: Machine learning and advanced analytics
With continuous data now flowing through the system, machine learning models come into play. These models analyze data in real time to predict future outcomes or trigger automated responses. By integrating ML models into real-time pipelines, big data platforms turn continuous streams into intelligent feedback loops. Each new data point improves the model, making predictions sharper and more adaptive.
Step 6: Visualization and action
The final step is making insights usable through real-time dashboards or automated systems. Visualization tools like Grafana, Tableau, or Power BI show live data streams in easily digestible formats. Meanwhile, automation layers trigger actions like adjusting pricing, flagging anomalies, or sending alerts, based on the latest data.
Types of Real-Time Analytics Platforms with Examples
Real-time analytics platforms vary widely in architecture, capabilities, and use cases. While some focus on stream ingestion and processing, others provide full-stack data management with built-in visualization and AI capabilities. Below are the major categories and the most recognized tools in each.
| Platform Type | What It Does | Key Features | Popular Examples |
|---|---|---|---|
| Stream Processing Platforms | Process data continuously as it’s generated for instant decision-making. | Handles data “in motion,” supports event-driven processing and low latency. | Apache Kafka, Apache Flink, Apache Storm, Confluent Cloud |
| Cloud-Managed Real-Time Analytics Platforms | Simplify real-time analytics with fully managed cloud infrastructure. | Auto-scalable, integrates data ingestion, processing, and visualization. | Google Cloud Dataflow, AWS Kinesis, Azure Stream Analytics, Databricks Structured Streaming |
| Hybrid Batch-Stream Processing Platforms | Combine real-time and historical data processing for unified insights. | Supports Lambda/Kappa architectures, balances speed with accuracy. | Apache Spark, Apache Beam, Snowflake Dynamic Tables, Google BigQuery Streaming |
| Specialized Real-Time Analytics Platforms | Deliver use case–specific insights (e.g., security, user behavior). | Prebuilt dashboards, domain-specific intelligence, rapid setup. | Elastic Stack (ELK), Splunk, Mixpanel, Amplitude, Looker |
| Enterprise Data Platforms | Provide an end-to-end ecosystem for large-scale real-time analytics. | Unified data management, governance, compliance, and integration. | Cloudera Data Platform, IBM Cloud Pak for Data, Oracle Stream Analytics, SAP HANA |
Benefits of Real-time Data Analytics
Real-time data analytics empowers organizations to make faster, smarter, and more accurate decisions by analyzing data the moment it’s generated. Unlike traditional analytics that rely on historical datasets, real-time systems provide immediate insights that drive agility across operations, marketing, and customer engagement. This instant intelligence benefits both businesses and customers, creating a data-driven ecosystem that thrives on responsiveness and precision.
Here are the top benefits of real-time data analytics.
-
Faster decision-making:
Real-time analytics allows organizations to act on data as events occur, enabling quick, informed decisions. It reduces the time lag between data generation and insight delivery. This immediacy helps businesses respond faster to opportunities, customer needs, or potential issues, gaining a competitive edge.
-
Personalized customer experience:
By analyzing live customer interactions, real-time analytics helps businesses tailor offers, recommendations, and communication to each user. It improves engagement by anticipating needs and delivering relevant content or products instantly. Personalized experiences enhance customer satisfaction, loyalty, and retention.
-
Improved operational efficiency:
Real-time visibility into processes helps organizations identify bottlenecks, resource wastage, or workflow inefficiencies as they happen. Teams can optimize operations immediately instead of waiting for scheduled reports. This leads to smoother processes, faster service delivery, and better use of time and resources.
-
Anomaly detection and risk mitigation:
With real-time monitoring, businesses can quickly detect unusual patterns such as fraudulent activity, network intrusions, or system failures. Early detection allows teams to take corrective action before issues escalate. This reduces financial losses, security risks, and operational downtime.
-
Growth revenue:
Real-time insights help businesses capitalize on sales opportunities the moment they arise. By understanding customer intent, optimizing pricing, and improving conversion strategies in real time, companies can drive higher sales. The ability to act quickly often translates into measurable revenue growth and market advantage.
-
Better forecast with enhanced predictive power:
Real-time data feeds enhance the accuracy of predictive models by continuously updating them with the latest information. This enables more reliable forecasts of customer demand, inventory needs, or market trends. Businesses can make proactive decisions that minimize risks and maximize efficiency.
-
Continuous efficiency in business:
Continuous monitoring and instant insights allow organizations to detect inefficiencies and reduce waste. Automation of decision-making processes further saves time and operational costs. Over time, this leads to better resource allocation and improved return on investment.
-
Improved
marketing campaign performance:
Real-time analytics enables marketers to monitor campaign performance as it unfolds, adjusting targeting, messaging, or budget allocation instantly. This agility helps maximize engagement and conversion rates. By learning what works in real time, marketing teams can drive stronger outcomes and reduce spend inefficiencies.
-
Improved product quality:
By analyzing live data from production lines, user feedback, or IoT sensors, businesses can identify defects or performance issues immediately. This helps maintain product consistency and quality standards. Continuous monitoring ensures faster quality control responses and higher customer satisfaction.
Now that we know how real-time analytics can amplify business success, there are a handful of challenges with real-time data analytics.
Challenges with Real-time Data Analytics
- High Infrastructure Costs: Real-time systems require powerful servers, storage, and networking capabilities, which can be expensive to deploy and maintain.
- Data Volume and Velocity: Continuous streams of data from multiple sources can overwhelm systems if not managed with scalable architectures.
- Data Quality Issues: Since data is processed instantly, there’s limited time for validation or error correction, leading to possible inaccuracies.
- Integration with Legacy Systems: Older, batch-based systems often struggle to sync with modern real-time analytics platforms due to format and speed mismatches.
- Scalability and Performance: Maintaining low latency and consistent performance becomes difficult as data loads and user demands grow.
- Security and Privacy Concerns: Streaming sensitive data in real time increases exposure risks and makes regulatory compliance more complex.
- Skill and Talent Shortage: Implementing and managing real-time analytics requires specialized knowledge in data engineering and stream processing, which is often scarce.
You now know everything about real-time analytics, how to implement it, and how it can enhance your business. Before we wrap this article, here is a brief on how real-time data can be used across all industries.
Real-time Analytics: Industry Use Cases
| Industry | Real-Time Analytics Application | Business Impact |
|---|---|---|
| Finance | Fraud detection, risk assessment, and algorithmic trading. | Reduces financial losses, enhances compliance, and enables faster, smarter investment decisions. |
| Retail & E-commerce | Personalized recommendations, dynamic pricing, and inventory management. | Boosts customer engagement, improves sales conversion, and minimizes stockouts or overstocking. |
| Manufacturing | Equipment performance monitoring, predictive maintenance, and production optimization. | Reduces downtime, lowers maintenance costs, and improves overall production efficiency. |
| Transportation & Logistics | Route optimization, fleet tracking, and delivery time prediction. | Cuts fuel costs, enhances delivery accuracy, and improves customer satisfaction. |
| Healthcare | Real-time patient monitoring, emergency alerts, and hospital operations management. | Improves patient outcomes, speeds up response times, and enhances hospital efficiency. |
| Telecommunications | Network performance monitoring, outage prediction, and bandwidth optimization. | Increases uptime, reduces service disruptions, and improves customer experience. |
| Public Sector | Disaster response coordination, traffic management, and cybersecurity threat detection. | Enables faster emergency response, improves public safety, and strengthens digital infrastructure resilience. |
| Gaming | In-game analytics, player behavior tracking, and engagement optimization. | Enhances user experience, boosts retention, and maximizes in-game monetization. |
And that’s a wrap. Real-time analytics is no longer a competitive advantage but a business necessity. By turning live data into instant insights, organizations can act faster, serve customers better, and stay ahead of change. As technology evolves, those who harness real-time intelligence will define the next generation of agile, data-driven enterprises.
Real-time Analytics: FAQs
1. Which database is best for real-time applications?
Databases optimized for real-time performance include Apache Cassandra, Redis, MongoDB, and Google Bigtable. These systems handle high-velocity data ingestion and quick query responses, making them ideal for applications that demand instant insights and low latency.
2. What is an example of real-time data analytics?
A common example is fraud detection in banking, where transactions are analyzed as they occur to flag suspicious behavior instantly. Other examples include live traffic monitoring, personalized e-commerce recommendations, and predictive maintenance in manufacturing.
3. Which industry uses data analytics?
Nearly every industry uses data analytics today, including finance, retail, healthcare, manufacturing, telecommunications, and transportation. Each sector leverages analytics to improve efficiency, reduce costs, and enhance decision-making.
4. How big is the real-time analytics market?
According to recent reports, the global real-time analytics market is projected to exceed $70 billion by 2030, growing rapidly as businesses prioritize instant insights and automation. The rise of IoT, AI, and edge computing continues to fuel this expansion.
5. Which platform is commonly used for real-time?
Popular platforms include Apache Kafka, Apache Flink, AWS Kinesis, Google Cloud Dataflow, and Azure Stream Analytics. These tools are designed to process continuous data streams and deliver near-instant analytics at scale.
6. What are the four types of analytics?
The four main types are Descriptive, Diagnostic, Predictive, and Prescriptive Analytics. Descriptive tells what happened, Diagnostic explains why it happened, Predictive forecasts what might happen, and Prescriptive suggests the best course of action.
7. Where do Real-Time Analytics Fall in Types of Analytics?
Real-time analytics is not a separate type but rather a capability that enhances all four types. It enables descriptive, diagnostic, predictive, and prescriptive insights to occur instantly, based on live data rather than historical datasets.
8. How is real-time analytics different from traditional data analytics?
Traditional analytics relies on static or historical data processed in batches, often with a delay. Real-time analytics, in contrast, continuously processes live data, delivering immediate insights that support rapid decisions and adaptive actions.
9. Difference between Batch Analytics and Real-Time Analytics
Batch analytics processes large volumes of data at scheduled intervals, suitable for trend analysis and reporting. Real-time analytics processes data continuously as it arrives, ideal for time-sensitive insights such as fraud detection or system monitoring.