Large language models (LLMs) have been all the rage for a while. Initially, they delivered strong results through prompting alone. Small prompt changes often improved output quality and control. This made prompt engineering a key technique in early AI applications. Teams used it to guide model behavior without retraining.
However, the approach revealed a fundamental constraint.
LLMs generate responses using learned patterns, not real understanding or live knowledge. They handle general concepts well but often miss factual accuracy in detail-heavy tasks. As real-world use cases expanded, relying only on prompting became limiting.
This gap exposed the limits of standalone LLMs. It also set the stage for retrieval-driven approaches like RAG, which is the focus of this article. Let's start by analyzing the issues with standalone LLMs.
Limitations of Standalone LLMs
Standalone LLMs generate fluent, coherent text. However, they fall short in many real-world applications. This is because their design focuses on language prediction instead of problem-solving.
hese limitations become clear when systems require accuracy, freshness, and real-world interaction. For example, there are several well-known limitations of standalone LLMs, with the key ones being:
Hallucinations: Models produce confident but incorrect answers. This is risky in domains like healthcare or finance.
Stale knowledge: Their knowledge is fixed at training time. They cannot access recent events or updates.
No access to proprietary data: They train mostly on public data. Internal documents, SOPs, and enterprise data remain inaccessible.
No action or tool usage: They cannot execute tasks. They can describe rescheduling a meeting, for example, but cannot perform the action.
Limited context window: They process only a fixed amount of text at once. Fitting large knowledge bases into a single prompt becomes extremely difficult.
With such constraints, prompting alone cannot solve real-world AI needs. A new approach is needed. The market needs an approach that allows models to access external, relevant data at runtime. This is exactly where Retrieval-Augmented Generation (RAG) enters the scene.
Also read: What is LangChain? Understanding Fundamentals, Key Components and Use in AI Development
What Is Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) improves LLM outputs by connecting them to external knowledge sources. Instead of relying only on training data, the model retrieves relevant information before generating a response.
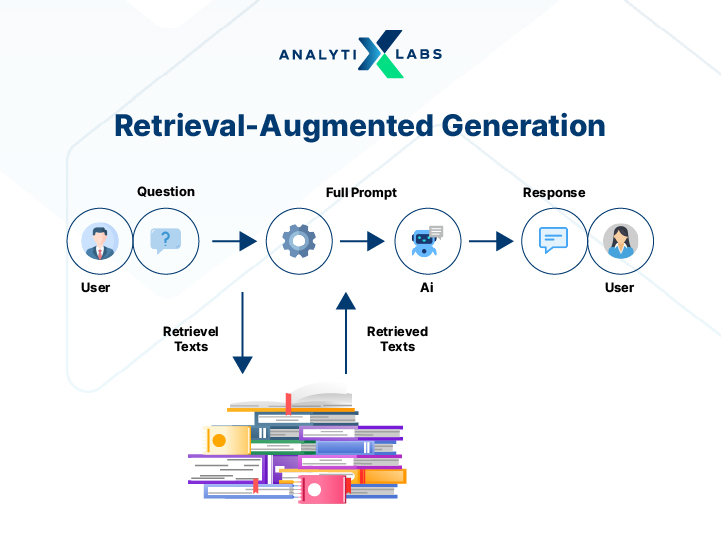
In one sentence, RAG follows a simple principle: lookup before generating. The system first fetches relevant data and only then produces an answer grounded in that context.
Why RAG Is Different from Prompting
Prompting only modifies the instructions you give the model. RAG goes further. It changes the data available to the model at runtime. It adds an external retrieval step instead of relying only on internal knowledge.
The Shift from Model Intelligence to Data Access
RAG has changed how you build AI systems. Instead of making models larger or retraining them, the focus shifts to providing the right data at the right time. This reduces cost and improves adaptability across domains.
What RAG Solves in Real Applications
RAG addresses several key limitations of standalone LLMs. Specifically, it:
Provides up-to-date information through live data connections.
Enables access to proprietary data like internal documents.
Reduces hallucinations by grounding responses in retrieved facts.
Supports source attribution, improving trust and transparency.
By combining retrieval with generation, RAG transforms LLMs into systems that operate on real, dynamic knowledge. This is a major shift away from static training data. Given this potential, it makes sense to deep dive into RAG. Let's start with its core components.
Core Components of a RAG System
A RAG system works as a modular pipeline. Each component handles a specific task, from retrieving data to generating grounded responses. Let's look at the role each critical component plays.
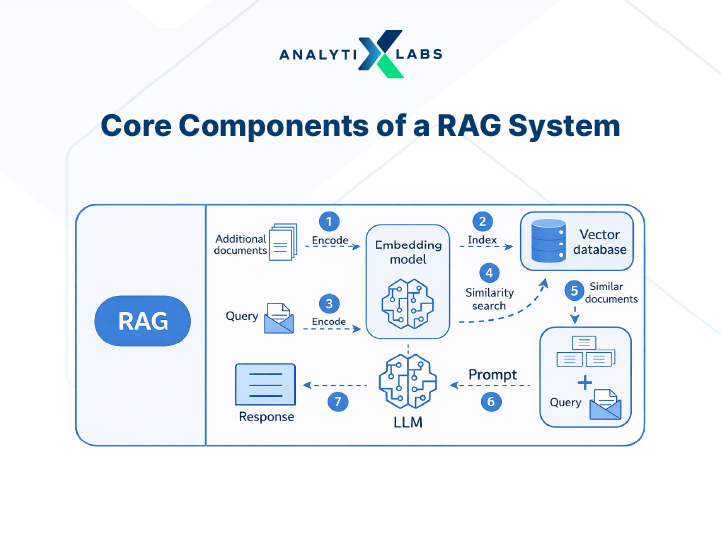
1) Knowledge Source Layer
This layer contains all external data the RAG system can access at runtime. It forms the foundation for retrieval. It is comprised of:
Documents: PDFs, reports, manuals, emails, and internal knowledge bases.
Databases: Structured data from systems like SQL or NoSQL enables precise lookups.
APIs: Real-time data such as user activity, market feeds, or system metrics.
These sources are critical. They allow RAG to use live, domain-specific information instead of static training data.
2) Embedding Model
The embedding model converts text into numerical vectors that capture semantic meaning. This applies to both stored documents and user queries. The component is critical because it positions semantically similar content closer in vector space, enabling accurate matching.
3) Vector Database / Retrieval Engine
The vector database stores embeddings and enables fast similarity search. Tools like FAISS, Pinecone, and Chroma are commonly used.
Here is how it works. When a query arrives, the system converts it into a vector. It then matches this vector against stored embeddings using similarity metrics. The system retrieves only the most relevant chunks, ensuring it passes forward focused data instead of entire datasets.
4) Prompt Augmentation Layer
This layer combines the user query with the retrieved context to create an enriched prompt. The system injects relevant information into the prompt. This guides the model to generate grounded responses.
5) Large Language Model (Generation Layer)
The LLM is the final component. It generates the output using the augmented prompt. It draws on both retrieved knowledge and its training data.
The result is an accurate, context-aware response instead of one that relies only on internal memory. This modular architecture lets you optimize each component independently. That makes RAG systems scalable and reliable in production.
Now, let's see how these components work together step by step.
How RAG Works: Step-by-Step Flow
The RAG pipeline operates as a sequence of steps. Each component plays a specific role. Together, they transform raw data into accurate, grounded, relevant responses.
1) Data Ingestion and Chunking
The process begins with collecting data from external sources such as documents, databases, and APIs. The system then breaks this data into smaller chunks.
Instead of processing entire documents, the system works with focused segments. This "chunking" improves retrieval accuracy and reduces noise. For example, you can split a 100-page manual into smaller sections for precise matching. This step directly uses the knowledge source layer.
2) Creating Embeddings
Next, the embedding model converts each chunk into a numerical vector. These vectors capture semantic meaning, not just keywords. This allows the system to understand intent and context.
The result is that similar concepts cluster closer in vector space. This enables meaningful search rather than literal keyword matching.
3) Storing Vectors
The vector database now stores the generated embeddings. It acts like an indexed library optimized for fast similarity search across large datasets. This setup lets the system retrieve relevant information efficiently instead of scanning raw text.
4) Query Embedding
When a user submits a query, the system processes and converts it into an embedding. The system may refine the query first by removing unnecessary words or simplifying the structure. This ensures the query aligns with stored vectors for accurate matching. The embedding model handles this step.
5) Retrieving Relevant Context
The query embedding is then compared with stored vectors using similarity metrics like cosine similarity. The system retrieves and ranks the most relevant chunks. Typically, it selects only the top results.
This filtering is crucial. It excludes irrelevant or noisy data before generation begins. The retrieval engine component handles this step.
6) Injecting Context into Prompt
The system combines the retrieved chunks with the original query to form an augmented prompt. This step enriches the input with relevant facts and context. It also ensures the model receives the right information before generating a response. This step maps to the prompt augmentation layer.
7) Generating Grounded Response
You now reach the end of the pipeline. The LLM generates the response using the augmented prompt. The output is grounded in retrieved data rather than internal knowledge alone.
This reduces the chances of hallucinations and improves factual accuracy. It is especially critical for real-time or domain-specific queries. The large language model (generation layer) executes this final step.
The bottom line is simple. Instead of operating as isolated modules, RAG works as a coordinated pipeline. It retrieves, enriches, and generates responses with higher accuracy and reliability.
Now, let's explore another crucial concept related to RAG: fine-tuning.
RAG vs Fine-Tuning
RAG and fine-tuning are two primary approaches to adapt LLMs for real-world applications. Both aim to improve accuracy, but they differ significantly in how they handle knowledge, updates, and specialization. Let's understand this in more detail.
How Fine-Tuning Works
Fine-tuning retrains a pre-trained model on a smaller, domain-specific dataset. The model learns from labeled examples and updates its internal parameters to better align with the target task.
This process is important for specialized use cases. Examples include legal document analysis, sentiment detection, and customer support automation. It effectively "teaches" the model domain-specific patterns and terminology.
Why Fine-Tuning Struggles With Knowledge Updates
Despite its sophistication, fine-tuning has clear drawbacks. Fine-tuned models operate on static knowledge. They only know what was included in their training dataset.
When new information becomes available, you must retrain the model to incorporate it. This process is expensive, time-consuming, and demands significant computational resources. Even large providers retrain models only periodically, which means knowledge becomes outdated quickly after deployment.
This limitation makes fine-tuning less suitable for dynamic environments where data changes frequently.
Key Differences Between RAG and Fine-Tuning
The critical differences between RAG and fine-tuning are:
Knowledge source: RAG retrieves external, real-time data. Fine-tuning depends entirely on training data.
Adaptability: RAG supports dynamic updates without retraining. Fine-tuning requires retraining for every update.
Cost and complexity: RAG focuses on data pipelines. Fine-tuning requires GPUs, labeled datasets, and expertise.
Model behavior: RAG keeps the base model unchanged. Fine-tuning modifies its internal weights.
Generalization: RAG preserves broad capabilities. Fine-tuning can reduce general abilities due to specialization.
In short, RAG enhances outputs by augmenting prompts with retrieved knowledge. Fine-tuning embeds knowledge directly into the model.
When to Use Each Approach
Despite its limitations, fine-tuning has its own place in the LLM landscape. Here is when to use each approach.
Use RAG when:
Data is dynamic or frequently updated.
You need access to proprietary or real-time data.
Flexibility and scalability are priorities.
You must preserve general conversational ability.
Use fine-tuning when:
Tasks are repetitive and domain-specific.
Knowledge remains relatively static.
High precision is needed for structured tasks like classification or extraction.
In practice, many systems combine both approaches. Fine-tuning shapes model behavior while RAG provides up-to-date knowledge. This hybrid approach delivers the best of both worlds: specialization plus adaptability.
There is another reason RAG is so widely adopted: reliability. Let's look at this aspect of RAG more closely.
How RAG Improves LLM Reliability?
RAG improves LLM reliability by grounding responses in real data. It does not rely only on probabilistic text generation. This shift makes outputs more accurate, verifiable, and adaptable.

1) Reducing Hallucinations
LLMs often generate confident but incorrect answers because they predict text, not facts. RAG reduces this risk by retrieving relevant information before generation. The model now relies on actual data instead of guessing.
This grounding significantly lowers hallucinations. In one study, hallucination rates dropped from 21% to 4.5% when RAG was applied.
2) Keeping Knowledge Up to Date
Traditional LLMs have fixed knowledge based on training data. RAG solves this by connecting models to external data sources you can update continuously.
When new scientific discoveries occur, for example, you only update the data store. The model itself stays untouched. This makes RAG suitable for fast-changing domains like finance, law, and healthcare.
3) Source Attribution and Explainability
Standard LLM outputs often act like black boxes with no clear source. RAG introduces transparency by retrieving and referencing source documents before generating responses. This lets users verify answers and increases trust, especially in high-stakes applications.
4) Domain Adaptation Without Retraining
General-purpose LLMs struggle with domain-specific tasks. RAG enables instant adaptation by connecting the model to specialized knowledge bases. These can include internal documents or industry data.
This capability removes the need for expensive retraining while still delivering domain-relevant responses. By combining retrieval with generation, RAG transforms LLMs from probabilistic generators into reliable, data-driven systems.
RAG's impact extends beyond LLMs alone. It has even reshaped ML pipelines. Let's look at that next.
How RAG Changed ML Pipelines?
So far, you might think RAG only improves LLM outputs. That is not the full picture. RAG has fundamentally changed how teams design and operate ML pipelines. The focus has shifted from training models to managing data and retrieval systems.
Also read: Top Programming Language for Machine Learning
Below are the key ways RAG has impacted ML pipelines.
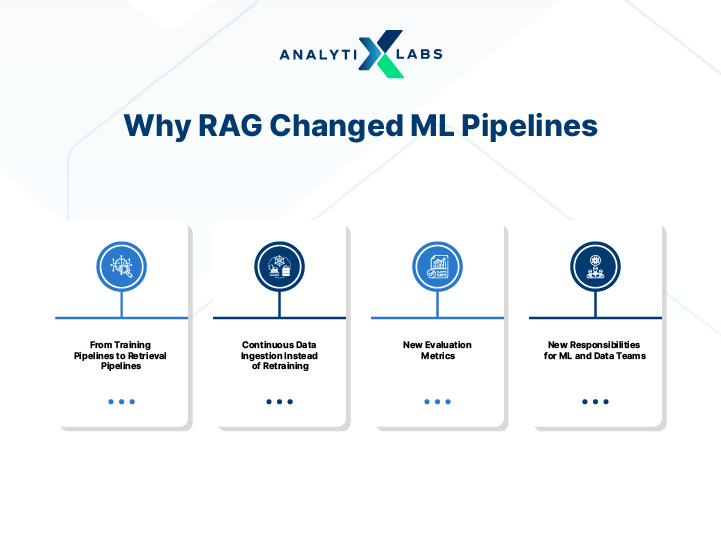
From Training Pipelines to Retrieval Pipelines
Traditional ML pipelines focused on training and optimizing model weights. With RAG, the focus has shifted to retrieval pipelines. Performance now depends on how well the system fetches relevant context at runtime.
Today's systems rely on embeddings, vector databases, and semantic search rather than repeated retraining. Model performance is no longer just model-dependent. It is also retrieval-dependent.
Continuous Data Ingestion Instead of Retraining
Earlier, updating knowledge required retraining models on new datasets. RAG replaces this with continuous data ingestion pipelines.
Teams can now update knowledge bases, re-index documents, and refresh embeddings instead of retraining models. This enables faster updates. It also reduces operational cost compared to repeated fine-tuning cycles.
New Evaluation Metrics
RAG has also introduced a new evaluation layer that goes beyond model accuracy. Data scientists now also measure:
Relevance: Are retrieved documents useful?
Grounding: Is the answer based on retrieved data?
Faithfulness: Is the output factually consistent with sources?
Note: These metrics require evaluating the retrieval and generation stages together.
New Responsibilities for ML and Data Teams
RAG turns ML systems into data-centric pipelines. As a data scientist or ML engineer, you now manage:
Data ingestion and indexing pipelines.
Chunking and embedding strategies.
Retrieval quality and latency.
Hallucination rates and grounding coverage.
This adds operational complexity. It also requires new skills in data engineering and MLOps. Note also that RAG introduces challenges such as latency, higher query costs, and debugging complexity when retrieval is weak. Its benefits come with their own set of trade-offs.
In short, RAG has transformed ML pipelines from model-centric systems into data and retrieval-centric systems. It has redefined how modern AI applications get built and maintained. It has also revolutionized the modern AI stack. Let's see how.
RAG Architecture in the Modern AI Stack
Modern RAG systems are built as layered architectures within the AI stack. Each layer plays a specific role in ensuring accuracy, scalability, and real-world usability. Let's look at these layers.
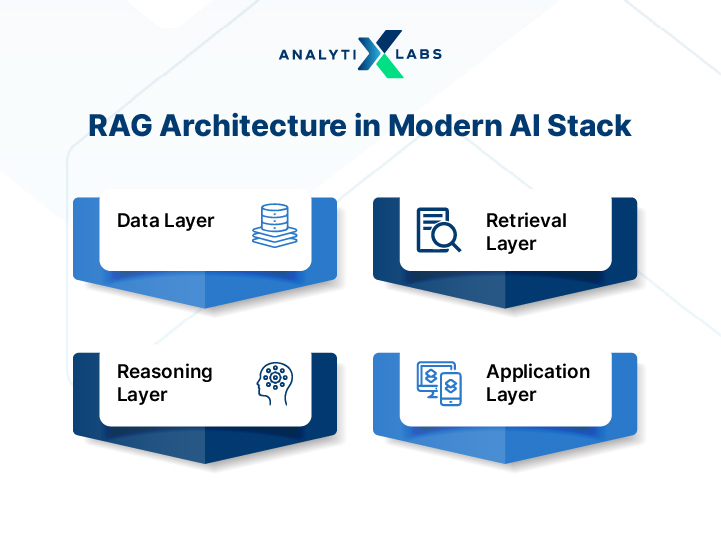
Data Layer
The data layer provides the knowledge foundation for the system. It includes:
Internal documents, databases, and external sources.
Data processing pipelines (cleaning, chunking, formatting).
Vector databases storing embeddings for semantic search.
This layer bridges the gap between static model knowledge and real-world information. Without it, LLMs cannot access current or domain-specific data.
Retrieval Layer
The retrieval layer finds relevant context at query time. Its key functions include:
Converting queries into embeddings.
Performing semantic or hybrid search.
Retrieving top-K relevant document chunks.
Modern systems optimize retrieval using techniques like query rewriting, reranking, and hybrid search. The quality of this layer matters enormously. It directly determines answer accuracy.
Reasoning Layer
The reasoning layer combines retrieved data with model intelligence. It includes prompt construction (query plus context), LLM generation, and multi-step reasoning or orchestration.
Advanced architectures like Agentic RAG or Corrective RAG add validation and planning. These features improve reliability and reduce hallucinations.
Application Layer
The application layer is the user-facing interface. It handles:
Chat interfaces, APIs, and dashboards.
Integrations with tools like CRM, Slack, or internal systems.
Features like citations, feedback, and iteration.
A strong application layer matters greatly. It ensures the system stays usable, transparent, and aligned with real workflows.
RAG architecture has clearly moved beyond just being about models. It is now a multi-layered system where data, retrieval, reasoning, and application layers work together. Thanks to such layered designs, LLMs become production-ready systems that are reliable, explainable, and adaptable.
The advancements do not stop here. Newer, more sophisticated RAG techniques have emerged in recent times.
Advanced RAG Techniques
Advanced RAG techniques go beyond basic retrieval. They aim to improve accuracy, reasoning, and reliability. These methods optimize how the system processes queries, retrieves data, and generates responses.
Below are some key modern RAG techniques.
1) Hybrid Search (Keyword + Vector)
Hybrid search combines keyword-based methods like BM25 with semantic vector search. Keyword search ensures exact term matching. Vector search captures meaning and context.
Together, they balance precision and recall. This approach is especially useful in domains with strict terminology. Examples include healthcare abbreviations and legal terms.
2) Re-ranking Models
Re-ranking improves result quality after initial retrieval. You first retrieve a large set of documents (e.g., top 100). You then apply a secondary model to reorder them by relevance.
The system then passes only the most relevant results to the LLM. Cross-encoder models are commonly used here. They evaluate query-document pairs jointly, which improves precision.
3) Query Rewriting
Query rewriting transforms the user query into a more retrieval-friendly format. The approach starts by breaking complex queries into sub-questions.
It then removes ambiguity and improves clarity. Finally, it adapts queries using past interactions. For example, a comparison query can split into multiple simpler queries processed in parallel.
4) Multi-hop Retrieval
Multi-hop retrieval handles complex queries that need multiple reasoning steps. Here, you:
Decompose a query into smaller parts.
Retrieve information iteratively.
Combine results into a final answer.
This method enables connections across multiple documents. It improves performance in research and legal use cases.
5) Structured + Unstructured Retrieval
Modern RAG systems often combine vector databases with structured sources like knowledge graphs. The two source types differ:
Unstructured data: text, PDFs, documents.
Structured data: entities, relationships, metadata.
The hybrid retrieval approach improves reasoning and context. Graph-based retrieval captures relationships that semantic search alone may miss.
6) Citation-Aware Generation
Citation-aware generation is critical for transparency and trust. The technique has these key features:
The model grounds responses in retrieved documents.
Outputs include references or source-backed reasoning.
Conflicting sources can be presented side by side.
All of this reduces hallucinations and makes outputs verifiable.
Advanced Retrieval Augmented Generation techniques transform basic pipelines into high-precision systems. They improve retrieval accuracy, enable multi-step reasoning, and keep outputs grounded in real data.
To get these benefits, however, you must prepare for several engineering challenges.
Engineering Challenges in Production RAG
Deploying RAG in production is not straightforward. It introduces several engineering challenges that go far beyond prototyping. These issues affect accuracy, performance, cost, and system reliability.
Let's look at the key challenges.
1) Chunking Strategy
Chunking directly affects retrieval quality. Poor chunking can split important context across segments. The result is incomplete or irrelevant retrieval. Common pitfalls include:
Fixed-size chunks may break semantic meaning.
Overlapping chunks increase token usage.
Missing structure (tables, sections) reduces accuracy.
A hybrid approach often works best. You combine semantic boundaries with overlap. The downside is added complexity.
2) Embedding Drift
Embedding drift occurs when embeddings become outdated. This happens due to changes in data, updates in embedding models, or shifts in domain context. The result is degraded retrieval quality over time.
This is why production systems often require embedding versioning, re-indexing strategies, and model governance. These practices help maintain consistency.
3) Latency vs Accuracy Trade-offs
RAG introduces latency through retrieval, reranking, and context assembly. This creates a trade-off. More retrieval steps mean higher accuracy but slower responses. Simpler pipelines are faster but risk missing relevant data.
Techniques like caching, approximate nearest neighbor (ANN) search, and parallel retrieval help. They balance this delicate trade-off.
4) Cost Optimization
Production RAG systems are resource-intensive. Costs come from multiple sources, including:
Embedding large document corpora.
Vector database storage and queries.
LLM inference with large contexts.
Optimization techniques include batching embeddings, caching frequent queries, and limiting retrieved context size. Without these, costs scale rapidly with usage.
5) Security and Access Control
RAG systems can expose sensitive data if not properly governed. Retrieved documents may contain PII or confidential data. Without access control, you risk leaking restricted information.
Common safeguards include access control lists (ACLs), data filtering, and governed data pipelines. These ensure only authorized content gets retrieved.
In short, production RAG is not just a modeling problem. It is a data engineering and systems design challenge. Success depends on balancing retrieval quality, system performance, cost, and security while maintaining reliability at scale. Despite these challenges, Retrieval Augmented Generation has been adopted at scale, and many real-world use cases have emerged.
Real-World Use Cases
Retrieval Augmented Generation is widely adopted across industries because it grounds AI responses in real, up-to-date data. This makes systems more reliable and useful in production environments. Several use cases have emerged.
Enterprise Knowledge Assistants
Organizations use RAG to build internal knowledge assistants that surface company-specific information instantly. For example:
Telecom company Bell enabled employees to access updated policies through a RAG-powered knowledge system.
The Royal Bank of Canada built a system that retrieves policies across fragmented internal platforms.
These systems improve decision-making and reduce the time spent searching for documents.
Customer Support Automation
RAG significantly improves support chatbots. It does this by retrieving accurate answers from internal documentation. For example:
DoorDash uses a RAG-based chatbot that retrieves past cases and knowledge articles before responding.
LinkedIn reduced issue resolution time by 28.6% using RAG with knowledge graphs.
This ensures responses align with company policies and reduces hallucinations.
Internal Copilots
Retrieval Augmented Generation also powers internal copilots that assist employees in daily workflows. For example:
Pinterest uses RAG to help users select the correct data tables for SQL queries.
Grab, an Asian super-app, built an internal assistant that automates report generation. It saves 3 to 4 hours per report.
These copilots enable teams to self-serve insights without deep technical expertise.
Research and Document Analysis
RAG enhances the analysis of large, complex datasets by retrieving relevant context before generation. For example:
Vimeo enables conversational video summaries with source-linked moments.
Financial and healthcare systems use RAG to analyze documents and generate insights.
In each case, RAG improves accuracy and reduces manual effort.
Across use cases, RAG has shifted AI from generic text generation to context-aware, reliable decision support systems. As RAG systems mature, they are increasingly moving beyond simple question-answering. Modern applications now demand decision-making, planning, and action. This shift naturally leads to the next evolution: AI agents built on top of RAG.
Retrieval Augmented Generation vs Agents
Agents have become complementary to RAG. They have made RAG even more capable. Let's understand this in more detail.

What Agents Add Beyond RAG?
RAG focuses on retrieving relevant information and generating grounded responses. AI agents go a step further. They reason, plan, and act.
Agents use tools like APIs, databases, and RAG systems together. They perform multi-step reasoning instead of single-step retrieval. They can also execute actions such as scheduling, querying systems, or automating workflows.
For example, instead of just retrieving weather data, an agent can analyze your preferences and recommend actions like what to pack.
RAG as the Memory Layer for Agents
RAG often acts as the knowledge and memory backbone of AI agents. It provides access to dynamic, external knowledge sources. It also supports both short-term and long-term contextual memory. This enables agents to ground decisions in real, updated data.
In agentic systems, RAG is no longer standalone. It has become a tool that agents call to fetch relevant context during reasoning. As RAG integrates into more sophisticated techniques, its future holds immense promise.
Future of Retrieval Augmented Generation Systems
The key future developments you can expect involving RAG include the following.
Continuous Knowledge Systems
Future systems will rely on constantly updated data pipelines. Agents will query real-time sources instead of static datasets. The result will be improved accuracy and adaptability.
Personal Knowledge Graphs
RAG is set to evolve into personalized knowledge layers. These systems will store user preferences, history, and relationships. They will use this data to deliver highly contextual responses.
Retrieval-Aware Reasoning Models
Next-generation models will not just retrieve data. They will reason about what to retrieve and how to use it. Agentic RAG systems are already refining queries dynamically and validating outputs iteratively.
The trend is clear. RAG will continue transforming LLMs into reliable information systems. AI agents will continue transforming them into autonomous problem solvers. Together, they will form the foundation of the next generation of intelligent, adaptive AI systems.
Conclusion
The main takeaway is simple. RAG is becoming, and in many ways has already become, the new default architecture for production AI.
RAG has shifted AI from static models to dynamic systems. It enables LLMs to access real-time, domain-specific knowledge without retraining. This significantly improves accuracy, reduces hallucinations, and makes outputs verifiable.
More importantly, RAG changes how you build AI systems. Pipelines now focus on data quality, retrieval, and grounding instead of just model training. This makes systems easier to update, scale, and adapt to new information.
As enterprises adopt AI at scale, RAG is no longer optional. It has become the default architecture for building reliable, production-ready AI applications.
FAQs
Does RAG replace fine-tuning?
No. RAG and fine-tuning solve different problems. RAG improves access to up-to-date data. Fine-tuning improves task-specific behavior. Many systems combine both in a hybrid approach.
Do all AI apps need RAG?
No. Simple tasks like general Q&A or content generation do not really need it. RAG shines when accuracy, freshness, or proprietary data matters.
Is a vector database required?
It is not always required, but it is the standard. Vector databases enable semantic search. This makes retrieval faster and more relevant in most RAG systems.