
One of the biggest revolutions that happened in the past 20 odd years can be the massive and unprecedented growth of the processing capabilities of computers due to the advancement in hardware. The eventual result of this was the humongous amount of data that began to generate daily. As the size of the data increased, so did the methods of handling them. Right now, the data and its related problems are business/domain-specific. The most common methods of solving data-driven problems include deploying the knowledge of Machine and Artificial Learning to gain meaningful insights, patterns, and predictions.
However, as there is a range of business problems, there is also a range of algorithms that can be used, making it important to understand the relationship between the algorithms and the various kinds of business problems which helps in choosing the right algorithm leading to better results.
The question – ‘Which algorithm should be used?’ can be answered by first answering a few preliminary questions such as:
a) What is the business problem?
b) If the business objective is Operational or Strategic?
c) How will the model be implemented to solve the business problem?
d) Does the algorithm’s capability match with requirements to solve the business problem?
Once these questions are answered, it becomes easy to narrow down on that algorithm best suited to solve a particular business problem.
The Bag of Algorithms
In today’s age, there are numerous machine algorithms that each have their own approach of solving the various kinds of problems ranging from optimization to classification to segmentation. To answer the question that will help determine the algorithm of choice, the prerequisite is to know the most commonly used algorithms and the category they fall into.
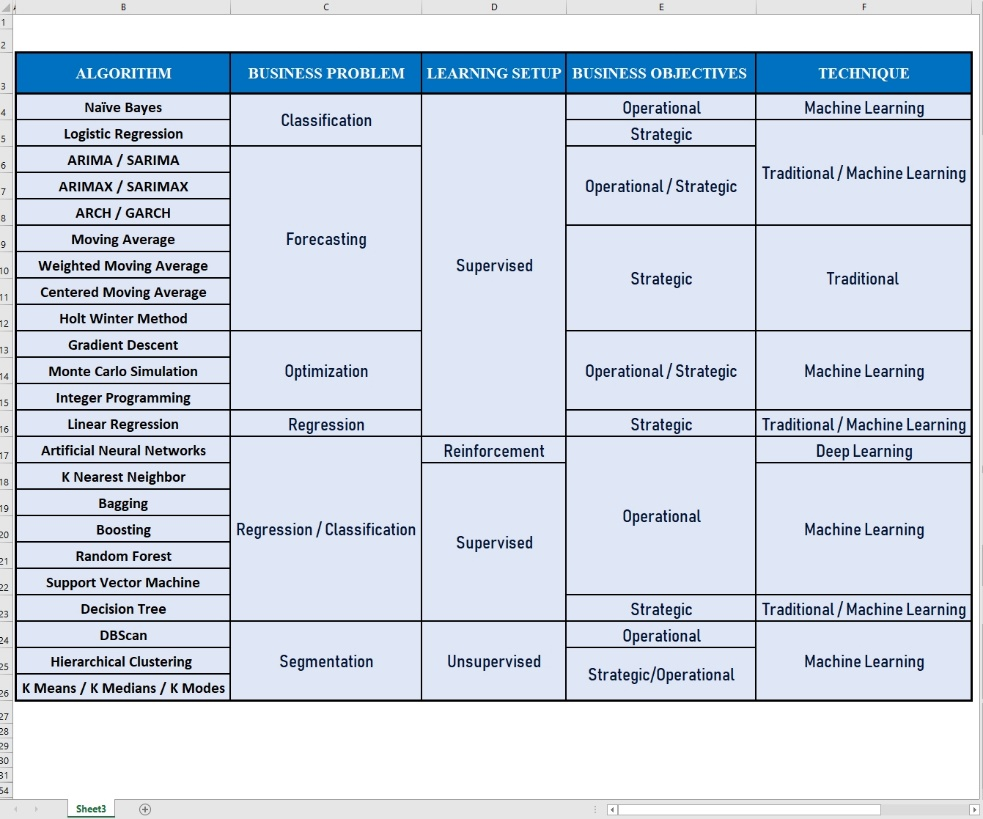
First, the categories can be understood, and then algorithms can be assigned to them. The algorithms that we deal with daily can be divided in terms of Business problems, Learning Setup, Business Objectives, and Implementation Techniques.
When it comes to Business problems, the problem can either be –
a) Regression (continuous numeric values are required to be predicted)
b) Classification (predicting certain predetermined classes/categories)
c) Segmentation (Classifying Data in undefined groups)
d) Forecasting (Predicting values over time)
e) Optimization (Optimizing values based on some constraint)
The algorithm work in various kind of setups such as –
a) Supervised Learning Setup (The Y aka target variable is available)
b) Unsupervised Learning Setup (The Y aka target variable is unavailable)
c) Semi-Unsupervised Learning Setup (combination of supervised and unsupervised)
d) Reinforcement Learning Setup (close to supervised learning but with the concept of reward and punishment)
The business objectives can be mainly of two types:
a) Strategic (Long to Mid Term objectives)
b) Operational (Short term objectives)
The various kind of algorithms is deployed using a range technique such as.
a) Traditional aka Classic Statistical Techniques (Algorithms that work purely on the fundamental concepts of statistics)
b) Machine Learning Techniques (Algorithms work using the concept of self-learning)
c) Deep Learning (Algorithms that use the neural network architecture to function)
A multitude of algorithms can be easily categorized using the above groups. Once the categories become clear, it becomes easy to answer the question that helps us choose the right algorithm for the problem at hand.
You may also like to read: Different Types of Machine Learning Algorithms With Examples
Characteristics of Algorithms
The inherent method of approaching a problem is different in different algorithms, which is exhibited through their characteristics. The characteristics of an algorithm can broadly be understood by focusing on key areas such as –
a) Accuracy: There is a general level of accuracy with the sophisticated machine and deep learning algorithms generally having a high level of accuracy. On the other hand, the traditional techniques do have a threshold and provide a decent accuracy and don’t outrightly fail, which sometimes other algorithms do.
b) Interpretability: How we can get the accuracy we are getting is sometimes important, and this is where algorithms that provide high accuracy are so complex that their internal working is like a ‘black box’ and are less complex interpretable. It becomes difficult to understand what the model is doing as the calculations are lengthy and complex and cannot be understood easily.
c) Type: Models can either be parametric or non-parametric. Parametric models are those where generally we have a mathematical equation involved which works under specific circumstances to function properly. In other words, there is a set of strict assumptions that should be fulfilled, which allow the algorithm that the data belongs to a particular family of distributions and tries to create the line of best fit and make predictions.
However, other models can be categorized as non-parametric, which have fewer requirements of assumptions to be fulfilled and create no mathematical equation to function. These algorithms can be rule-based, distance-based, probabilistic, etc.
d) Data Size Handling Capabilities: Some algorithms can handle that which is in very high dimensions, i.e., there are many rows. Similarly, a certain algorithm is best for dealing with big data.
e) Resistance to Multicollinearity: Some algorithms, especially tree-based algorithms, are much more resistant to Multicollinearity than, say, traditional models.
f) Susceptibility to Outliers: Parametric algorithms are generally more vulnerable to outliers while others are not.
g) Assumptions: For some algorithms, there is a set of predetermined assumptions that should be satisfied for them to function properly, while other, generally non-parametric algorithms, have no or less rigid assumption requirements.
h) Training and Testing Phase: The time taken during the training and testing phase differs as a certain algorithm that depends on a lot of small isolated calculations taking a lot of time during the testing phase while algorithms, where mathematical equations are involved, take more time in the training phase.
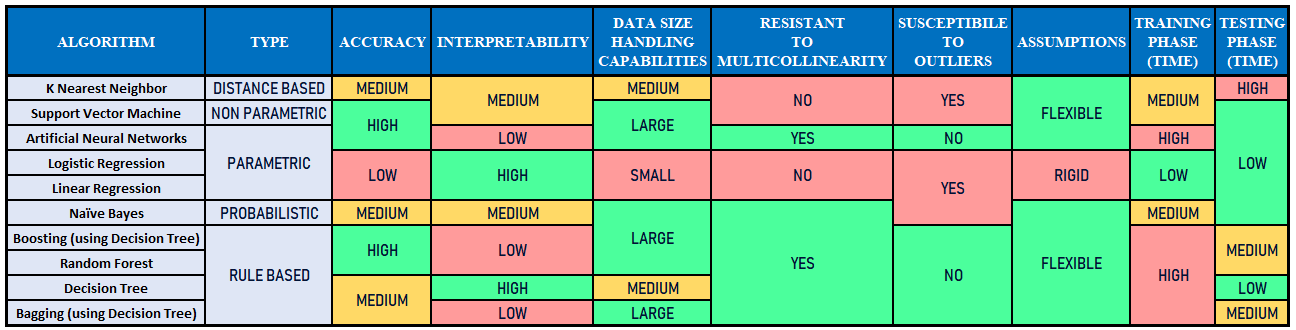
Pros and Cons of Algorithms
The bulk of algorithms lie in the predictive model’s domain; therefore, once the characteristics of such models are understood based on these characteristics, the pros and cons of each of these algorithms can be assessed.
a) Linear / Logistic Regression
Both, Linear and Logistic Regression are parametric methods. They are statistically sound techniques. Compared to other methods (predominantly Machine Learning methods), they are not as accurate but still provide decent accuracy every time. The most important advantage of these methods is the interpretability as they come up with coefficients for each feature, eventually helping in understanding the key drivers. Also, they are efficient as they take less training and testing time. The problems with these methods include peculiar assumption requirements as for these algorithms to work properly, a particular set of assumptions must be fulfilled, such as the dependent variable being normally distributed (for Linear Regression), data have no multicollinearity and heteroscedasticity. Also, as these methods fit a line of best fit, they are susceptible to outliers and missing values. If the independent variables are not linearly related to the dependent variable, then the usage of these algorithms is limited. With Logistic Regression, the limitation includes the lack of capability to capture the complex relationship between dependent and independent variables.
You may also like to read:
1. What is Linear Regression In ML? With Example Codes
2. Logistic Regression in R (With Examples)
b) Support Vector Machines
It is one of the most important and powerful algorithms for performing classification and can also solve regression problems. Support Vector Machine was such a powerful algorithm that it stunted the growth of artificial neural networks for a while as it was more powerful than it. Because of its ability to perform kernel transformations, SVM can deal with data that are in high dimensions quite effectively. This makes it useful to classify those data where the number of features is very high. SVM also comes with its own set of disadvantages, such as that it is not a very good algorithm for solving regression problems and multi-class classification problems, and its real power lies with binary classification. It can deal with data in high dimensions, but it takes a lot of time and therefore is not a very efficient algorithm. Also, just like some other machine learning algorithms, its performance is very much dependent upon the selection of certain hyperparameters along with the kernel function (if it is being used). And like Linear Regression, it also fits a decision line, and consequently, it is also sensitive to outliers and can lead to overfitting easily. Learn more about Support Vector Machine: Introduction To SVM – Support Vector Machine Algorithm in Machine Learning
c) K Nearest Neighbor
One of the simplest algorithms to understand and implement, KNN is widely used for its simplicity. Being a non-parametric method, it has no issue with assumption, and the data is not required to be in a particular statistical format for KNN to work properly. During the training phase, the time is not very high as not major calculation takes place in this phase. Unlike Naive Bayes and Support Vector Machines that are majorly used for solving classification problems, KNN can solve both Regression and Classification problems with the same level of expected accuracy. Also, as it looks for similar events for coming up with predictions, it is widely used as a missing value treatment method. With the various advantages KNN has, certain aspects of it are both a curse and a boon, such as the fact that we don’t have to deal with multiple hyper-parameters to tune even when it’s a machine-learning algorithm. The only major hyper-parameter to deal with is the value of K (number of the nearest neighbor being considered); however, this also caused the major problem – its performance is highly dependent upon the value of K. Other hyperparameters include the distance metric, but again there is a huge range of distance metric to choose from with the performance of the algorithm being directly related to the choice of the distance metric. KNN also cannot deal with high dimensional data as it is prolonged in the testing phase. As it will calculate the distance from the unknown point to all testing points, the time taken to come up with predictions is very high, and this problem becomes more evident when dealing with data with too many features. The disadvantages also include the inability to perform proper classification in the event of a class imbalance problem, the requirement to scale all features (as is the case with all the distance-based algorithms), and the fact that it is vulnerable to multicollinearity, outliers, and missing values.
d) Naïve Bayes
Naive Bayes is a probabilistic method and can perform many probabilistic-based calculations in a concise period of time to come up with predictions. This is why it is very efficient as it takes less time in the training and testing phase and can deal with data that are in very high dimensions. Because of such features, it is among the most widely accepted algorithms for performing text-related operations such as Text Classification. It can perform multi-class classification without many problems. Not to be taken lightly, the ease of understanding this algorithm is also one of its biggest advantages as this makes it easy to understand and solve the problem in the case of poor predictions. Among the prominent disadvantages of Naive Bayes is that it only functions for solving classification problems and not regression problems. The assumption that all features are independent is one assumption that is highly difficult to fulfill in real-world data, and it performs nonetheless still. The assumption is there that can cause the algorithm to break at times.
e) Decision Trees
Among the most widely used algorithm, Decision Trees can be used for both Regression and Classification. Decision Tree as an algorithm has a long list of advantages. Still, among the various advantages, the most important ones are that as it is a rule-based algorithm, it has no requirement to fulfill any assumptions. It has a decent accuracy level, with a high level of interpretability being the most important aspect of its advantages. The Decision Tree algorithm is so highly interpretable that its predictions can be visualized (in the form of a tree-based diagram) that helps especially in situations where there is a need to convey the process through which the algorithm is coming up with a particular prediction. The advantages don’t end here because of its inner-functioning, it takes less time during the testing phase, is not vulnerable to an outlier or missing values, and has no issues with data that have multicollinearity in it. With all these advantages, there persist a good number of disadvantages with this algorithm, such as the time taken during the training phase, which is a bit high. Also, as the size of the data increases, the computational time increases exponentially. However, the major problem with the decision trees is its habit of overfitting the data, which is why methods such as Random Forest, etc., were developed to counter this problem.
f) Random Forest
Random Forest is a special case of Bagging where several samples are created using Bootstrapping and Random Subspaces on which decision trees algorithm is fit and multiple accuracies are calculated, thereby simplifying the otherwise complex decision boundary consequently addressing the problem multicollinearity. As it used Decision Trees as the algorithms, it has almost the same set of advantages (including the lack of assumptions, data preparation, and a decent level of accuracy). Still, it doesn’t have the same set of disadvantages as it tries to solve overfitting. The problems of Random Forest are different from Decision Trees, such as it can become extremely complex, becoming highly computationally expensive, and time-consuming. Also, the increase in accuracy diminishes with more bags (samples); thus, tuning hyper-parameters becomes extremely crucial, such as the depth of trees and the number of bags. The biggest loss of Random Forest is the lack of interpretability, as it works as a black box, and this is one advantage of Decision Tree, which is not present with Random Forest as it is one of an ensemble learning method which in general is very less interpretable.
g) Bagging / Boosting
Bagging and Boosting both are ensemble methods. Both these methods aim to address the problem of overfitting. Bagging is a parallel process while Boosting in a sequential method. Both these methods can deploy any algorithm, but the most common algorithm is decision trees. As a result, they can solve classification and regression problems. One of the advantages of such methods is that they don’t require much data to come up with good predictions and can perform decently even with limited data. Having high accuracy and the advantage of not being vulnerable to outliers, missing value, lack of assumption requirement, and multicollinearity makes them an excellent algorithm to deal with.
Again, the problem with these methods is the large number of hyper-parameters to tune, time taken during the training phase, and, most importantly, extremely low interpretability.
h) Artificial Neural Networks
ANN is a sophisticated deep learning algorithm that works under a reinforcement learning setup. It can provide a high level of accuracy and can solve both, Regression as well as Classification problems. They don’t require any assumptions to work properly and can handle data in large quantities. One of the issues with ANN is that it takes a lot of time during the training phase as it has to converge to the best values of weights and bias. However, once the network is trained, the time taken for predictions (testing phase) is very low, making it an attractive algorithm to work with. Being a deep learning algorithm, ANN can be deployed for solving problems that involve various kinds of data such including data having multimedia (audio, images, etc.). It is also not adversely affected by outliers, missing values, and multicollinearity. However, there are disadvantages, such as that ANN is a very complex algorithm to understand and implement that works well when there are many data points. It is also computationally expensive compared to other algorithms that provide a similar level of accuracy (e.g., SVM). As they deal with large amounts of data, there is a possibility of overfitting. Still, the most crucial is that is its extremely low interpretability as it works like a black box making it very difficult to answer questions such as finding the most important drivers (important features deriving the dependent variable).
Answering the 4 Question

With the understanding of the various algorithms, the question can be asked now that will help in determining the best algorithm for the problem at hand.
Q1. What is the business problem?
The most basic question is to identify the business problem at hand and the subsequent conversion of the business problem into a statistical problem to attain a solution. Various kinds of business problems can be converted into statistical problems such as a business problem that requires to predict values to a pin-point accuracy can be categorized as a Regression problem, and the algorithms such as Linear Regression, Decision Tree Regressor, Random Forest, Bagging, and Boosting can be deployed. If the quantity of data is large and a high level of accuracy is required, then ANN is also an option. A lot of problems require classifying a scenario into pre-conceived classes. In such cases, all the algorithms discussed earlier above (except linear regression) can be deployed. In a scenario where the classes are unknown, segmentation algorithms such as K-Means, DBSCAN, etc., can be used.
Q2. If the business objective is Operational or Strategic?
It is important to understand if the business solution is required immediately or understand the business trend to take some strategic steps. When it comes to the business objectives being operational, the solution is required in a very short spend of time, sometimes even within seconds. Here the requirement of the algorithm being interpretable is low, and having good accuracy is very high. Here the solution provided by the algorithms is the final solution. For example, If there is a requirement to identify if a bank transaction is a fraud or not, then this is a business problem. It is a binary classification problem (Fraud(Yes|No)). However, the business objective is operational. Here Machine and Deep Learning algorithms such as Random Forest, Bagging, Boosting, ANN, etc., can be handy. There can be business problems whose objective can be Operational such as identifying the causes of low profit. Here the requirement is to deploy such an algorithm that will have a high level of interpretability which will help understand the drivers causing low profit. Here the algorithm will not provide the final solution but will act as a step and catalyst for the management to solve the actual business problem. Algorithms such as Linear Regression or Decision Trees are best suited in such scenarios.
Q3. How will the model be implemented to solve the business problem?
The method in which the algorithm will be implemented also influences the selection of the algorithm. If the implementation is such that detailed reports will be created out of the results of the data will be updated after a delayed period of time. The traditional algorithms are the right choice. However, if there is a requirement for frequently update the model with data being changed continuously and the business problem requires some real-time scoring, then the machine learning algorithms are the right choice where the decision boundary can be altered continuously. Algorithms, especially ANN, that can be updated easily and frequently that build upon the previous knowledge is the best algorithm to go for.
Q4. Does the algorithm’s capability match with requirements to solve the business problem?
Every business problem has its own set of unique constraints. In the business problems where text is involved, the data generally is in very high dimensions. Here, algorithms such as Naive Bayes can be used if the business problem has multimedia. Deep learning algorithms such as ANN can be used. If the problem is of binary classification, then the best algorithm is SVM. At the same time, for multi-class classification problems, Ensemble learning methods along with ANN and Naive Bayes can be deployed. If the requirement is to eventually show the solution to a non-data science / non-statistical crowd, then algorithms with high interpretation are the right one. All such factors influence if the algorithm is good enough to solve a business problem despite its isolated qualities or its lack.
The Way Forward

Understanding various algorithms is very important as it helps in choosing the right algorithm and optimizing the accuracy that can be attained from that algorithm. However, it is also important to understand the future of the application of such algorithms. For example, the module ‘Hunga Bunga’ (in beta stage) by Scikit learn tests and compares the long list of models available in Sklearn once the user feed pre-processed data. This allows the user to apply all the major algorithms in a single go and get a list with each algorithm’s accuracy. This still cannot replace the requirement for a Data Scientist having sound knowledge of various algorithms, knowing the advantages and limitations of each algorithm helping in their proper implementation.
You may also like to read:
1. What is Knowledge representation in Artificial Intelligence?
2. Machine Learning vs Deep learning- What Is the Difference?





