
Spark is an open-source distributed computing framework widely used in data science to process large amounts of data. Its distributed computing capabilities make it ideal for cost-effectively analyzing large datasets, and its open-source framework ensures that data scientists have access to the latest innovations.
Developed at UC Berkeley’s AMPLab, Spark provides a unified API for working with diverse data sources. That includes high-level libraries for machine learning, graph processing, and stream processing. Therefore, Spark for data science is ideal for handling data wrangling, preprocessing, and analysis.
In this article, we will explore Spark’s features and capabilities. Then, we will discuss why it is essential for processing Big Data. Finally, we will explore strategies for best utilizing Spark in your data science workflows.
What is Apache Spark?
Apache Spark is a popular open-source distributed computing framework. It enables the processing of large-scale data sets across multiple nodes in a cluster. It was originally developed at the University of California, Berkeley’s AMPLab, in 2009 and later donated to Apache Software Foundation (ASF). Spark enables users to access data quickly from HDFS and other sources like S3, MySQL, Cassandra, and MongoDB.
Spark can run in Hadoop clusters through YARN or stand-alone mode without any extra installation. The main features of Spark include its speed and scalability, which make it ideal for iterative machine-learning algorithms used by data scientists.
With the help of in-memory caching, Spark can process queries at lightning speeds compared to MapReduce jobs.
Spark provides a library of machine learning algorithms that can be used to create useful insights from data quickly and cost-effectively. It also offers support for graph analytics, making it easier to analyze the relationships between different elements in unstructured data sets.
Spark is helping organizations revolutionize how they approach data processing and analysis, unlocking the potential to make better decisions faster.
Video developed by Databricks, founded by the creators of Apache Spark
Busting Apache Spark Myths
#1. Apache Spark is a database.
For more clarity, Apache Spark is not a database. It is a framework designed for distributed computing and allows users to process data in parallel across a cluster of computers. It can read data from various sources like databases, file systems, and streaming data sources, even though it is not a database itself.
#2. Apache Spark can replace Hadoop.
Apache Spark is not a replacement for Hadoop. While Spark can run on Hadoop clusters, it is not a Hadoop replacement. Rather, it is a complementary tool that provides faster and more efficient data processing than Hadoop’s MapReduce algorithm.
#3. Apache Spark can solve all big data problems.
Apache Spark is not useful for all big data problems. It is best suited for tasks that require complex data processing. These include machine learning, graph processing, and real-time data processing. It may not be the best tool for simpler tasks, and users may be better off with a more straightforward solution.
#4. Apache Spark is a programming language.
Apache Spark is not a programming language. While it provides APIs for multiple programming languages, such as Python, Java, and Scala, it is not a programming language itself.
Apache Spark for Big Data
Big Data refers to the vast amounts of structured, semi-structured, and unstructured data that organizations generate on a daily basis. It comes from various sources, such as social media, mobile devices, internet searches, and IoT devices. This data’s sheer volume, velocity, and variety make it challenging to store, process, and analyze using traditional methods.
Also read: Big Data Technologies
To address these challenges, companies have turned to Big Data Analytics to extract valuable insights from their data. Big Data Analytics involves using advanced analytics techniques to process and analyze large and complex data sets.
Also read: Understanding Big Data Analytics
One of the most popular tools for Big Data Analytics is Apache Spark.
Spark’s distributed computing capabilities allow companies to process large data sets quickly and efficiently. Spark also provides high-level libraries for machine learning, graph processing, and real-time data processing. Thus, making it a versatile tool for Big Data Analytics.
Also read: 16 Best Big Data Analytics Tools
Additionally, using Spark for Data Science allows companies to process and analyze massive data sets in real-time. Thus, providing them with actionable insights and business intelligence.
Spark’s machine learning libraries enable it to build predictive models. These can be used to make better business decisions, while its graph processing capabilities can help companies identify patterns and relationships in their data.
Big Data Analytics is a critical component of modern business strategy. Apache Spark is one of the most popular and versatile tools for processing and analyzing large and complex data sets.
Why is Spark Important for Big Data Companies?
Big Data companies rely on Spark for Data Science to generate, store, and process massive amounts of data on a daily basis. They require a tool that can handle data efficiently to extract insights and valuable information that can be used for further improvements in business operations.
Spark’s scalability enables companies to process massive datasets rapidly and efficiently. It works by distributing data and processing across a cluster of computers. This feature makes it an ideal tool for handling big data workloads.

Why Spark?
- Spark is faster than many other big data processing tools, including Hadoop. It is because of its in-memory computing capabilities. It can also process data in real time, making it an ideal tool for handling streaming data. It enables businesses to perform complex calculations, analytics, and machine learning tasks faster than traditional systems can.
- Spark for Data Science provides a variety of libraries for machine learning, graph processing, and real-time data processing. These libraries enable businesses to build complex models and extract valuable insights from their data. Thus, making it an essential tool for Big Data Analytics.
- It can also integrate with various data sources, including SQL databases, NoSQL databases, HDFS file systems, and Amazon S3. This makes it easy to access data from different sources, enabling businesses to use all their available data for analysis.
- In addition, Apache Spark can be deployed in a wide range of production environments. It can run on-premise or cloud-based deployments and hybrid solutions that combine the two. This makes it highly flexible and suitable for any enterprise’s needs. Finally, Spark’s open-source nature means that it is available for free. And this makes it a cost-effective solution for businesses of all sizes.
Features of Apache Spark
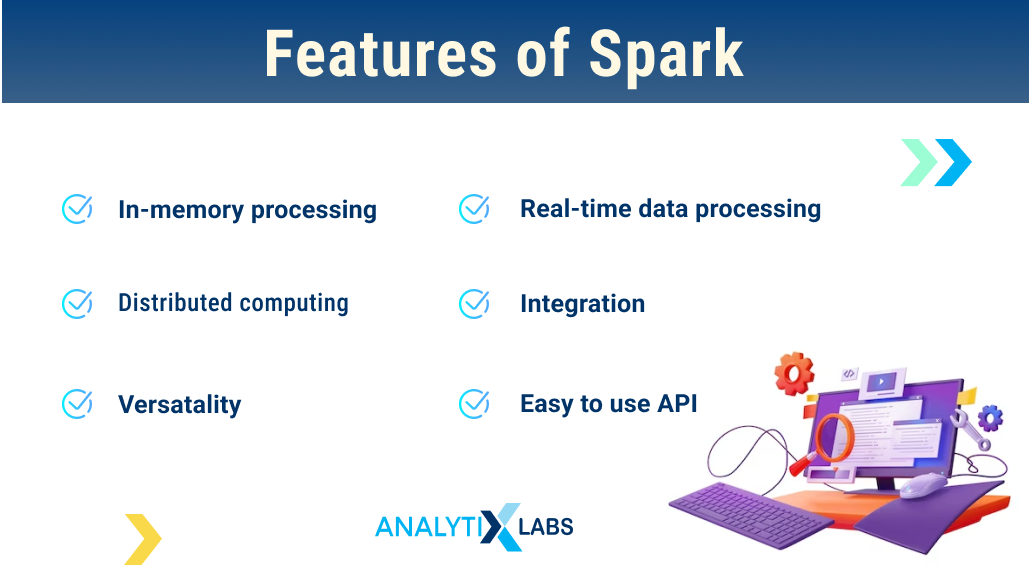
- In-memory processing: Spark processes data in memory faster than traditional disk-based processing. This means that data can be accessed and processed more quickly.
- Distributed computing: Spark’s distributed computing capabilities enable it to handle large-scale data.
- Versatility: Spark is a versatile tool that supports various data processing and analysis tasks. That includes batch processing, stream processing, and machine learning.
- Real-time data processing: Spark’s real-time data processing capabilities enable it to process and analyze data as it is generated. Thereby making it ideal for critical applications such as fraud detection and recommendation engines.
- Integration: Spark integrates with many data sources, including Hadoop, databases, and cloud storage solutions. Therefore, businesses find incorporating Spark into their existing Big Data infrastructure convenient.
- Easy-to-use APIs: Spark provides easy-to-use APIs for programming in languages such as Scala, Python, and Java, making it accessible to a wide range of developers.
Use cases
- Data processing: Apache Spark is ideal for processing large volumes of data, including batch processing and real-time processing. It is commonly used for data preprocessing, wrangling, and cleansing.
- Streaming data: Spark’s real-time data processing capabilities make it ideal for streaming data applications. It includes social media monitoring, real-time fraud detection, and IoT data processing.
- Machine learning: Spark’s machine learning libraries, such as MLlib, enable data scientists to build and train machine learning models on large datasets.
- Graph processing: Spark’s GraphX library enables graph processing. Thus, making it ideal for social network analysis, recommendation systems, and fraud detection.
- Image processing: Spark can be used for image processing applications, such as image recognition and classification.
- ETL processing: Spark is widely used for ETL (extract, transform, load) processing, enabling businesses to extract data from various sources, transform it into a usable format, and load it into a data warehouse or data lake.
- Data visualization: Spark can be used to generate visualizations of large and complex datasets, making it easier to identify patterns and trends.
- Ad hoc analysis: Spark’s interactive shell and SQL support enable ad hoc analysis, allowing businesses to explore their data and uncover insights.
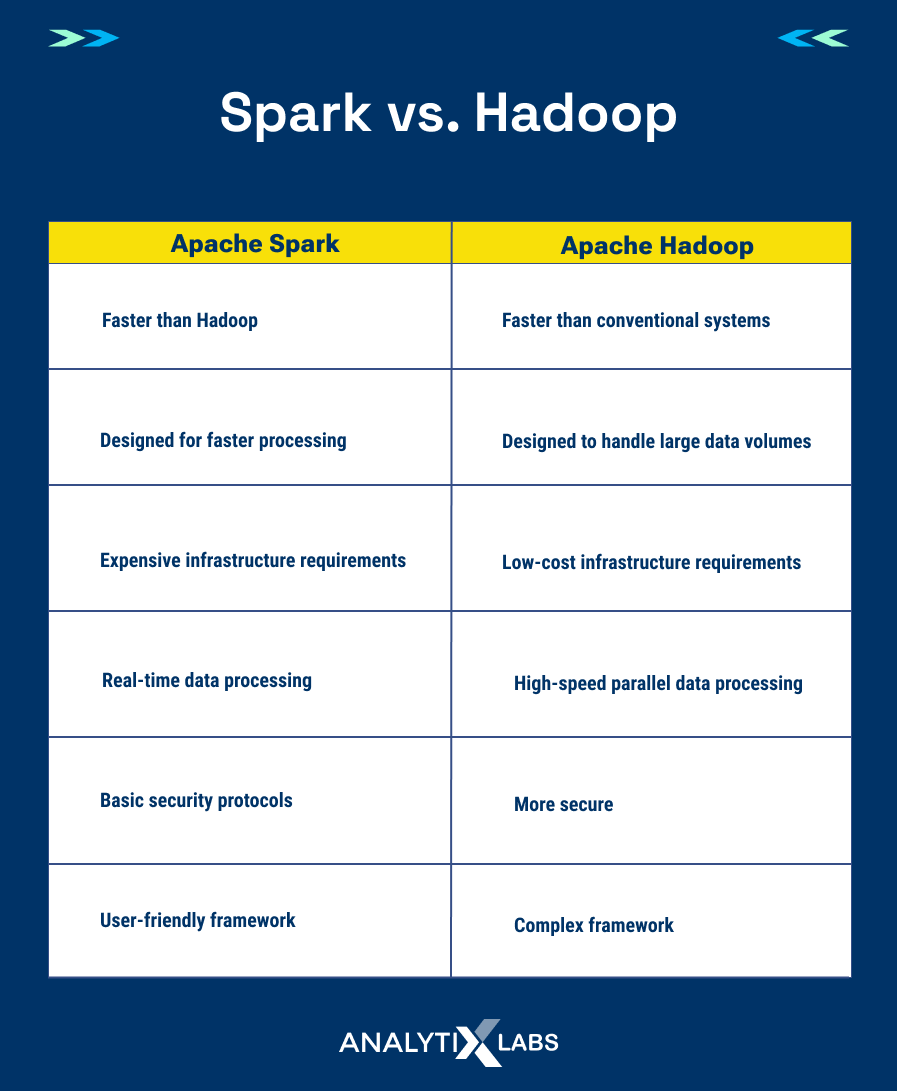
Spark vs. Hadoop: Which one is better?
-
Performance
Performance is one of the primary differences between Apache Spark and Hadoop. Although Apache Spark may process in-memory, Hadoop keeps the results of each intermediate step on disc.
Hadoop can read data from the local HDFS, but its performance falls short of that of Spark, which runs in memory. Regarding in-memory and on-disk operations, Apache Spark iterations are 100 times faster than Hadoop’s.
-
Data processing
Apache Spark offers far more than Hadoop does in terms of batch processing. Additionally, the two frameworks approach data in various ways. Hadoop employs MapReduce to batch and distribute sizable datasets across a cluster for parallel data processing.
Apache Spark, on the other hand, offers real-time streaming processing and graph analysis. Hadoop must be used in conjunction with other technologies to accomplish such capability.
-
Real-time processing
Hadoop only supports batch processing using MapReduce. It does not support real-time processing. This makes it difficult to use Hadoop for applications that require low-latency execution.
Low-latency processing is offered by Apache Spark, and results are delivered via Spark Streaming in close to real-time. It is designed for high scalability and fault tolerance.
Spark can read streams from the stock market, Twitter, or Facebook, which include millions of events each second.
-
Cost
Spark and Apache Hadoop are open sources. Thus, companies using them do not need to pay a licensing fee. Nonetheless, it is necessary to account for the expenditures of infrastructure and development.
Hadoop is a less expensive choice because it is disk-based and compatible with commodity hardware. The infrastructure cost increases since Apache Spark activities, on the other hand, are memory-intensive and demand a lot of RAM.
-
Security
Spark offers only shared secret password authentication, which makes it slightly less secure than MapReduce. Due to Kerberos, Hadoop MapReduce is more secure. In addition, it supports the more conventional file permission model known as Access Control Lists (ACLs).
-
Fault tolerance
Fault tolerance exists in Spark. As a result, if the application fails, there is no need to start over from the beginning. MapReduce is also fault-tolerant, just like Apache Spark. Therefore any failure will not require the application to start from scratch.
Which one to choose?
The debate between Hadoop and Spark for big data processing is common. The choice of which platform to use depends largely on the specific needs and requirements of the project at hand. Here are some key factors to consider when deciding which platform is best:
Apache Spark
- Runs as a stand-alone utility without using Apache Hadoop.
- Provide scheduling, I/O capabilities, and distributed job dispatching.
- Includes Python, Java, and Scala among the languages it supports.
- Provides failure tolerance and implicit data parallelism.
You may choose Apache Spark if you are a data scientist focusing largely on machine learning methods and big data processing.
Apache Hadoop
- Provides a comprehensive framework for the processing and storing of large amounts of data.
- Offers a staggering variety of products, including Apache Spark.
- Builds on a distributed, scalable, and portable file system.
- Utilizes additional programs for parallel computing, machine learning, and data warehousing.
You may choose Apache Hadoop if you need a wide range of data science tools for processing and storing massive amounts of data.
The Architecture of Spark
Spark follows the Master/Slave architecture where the master node controls and manages slaves. Its main components are:
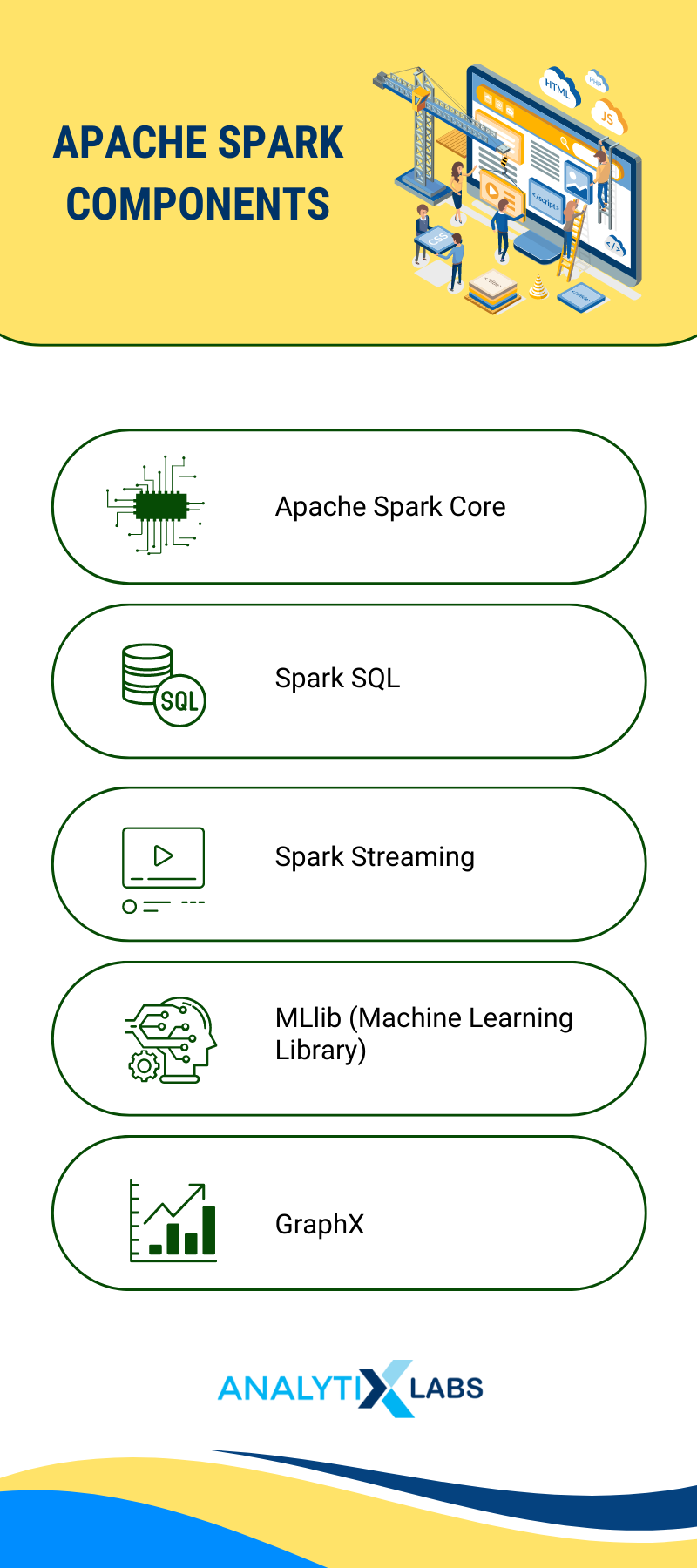
- Apache Spark Core
The primary execution engine for the Spark platform, on which all other functionalities are built, is called Spark Core. Fault tolerance, in-memory computing, resource management, and access to external data sources are all features of the Spark core.
For simplicity of development, it also offers a distributed execution infrastructure that supports a wide range of programming languages, including Python, Java, and Scala.
- Spark SQL
Working with structured data is possible with the Spark SQL module. To query structured data inside Spark programs, utilize Spark SQL. Java, Python, R, and SQL are all supported.
Hive, Avro, Parquet, JSON, and JDBC are just a few of the data sources from that Spark SQL can also be linked. Moreover, Spark SQL supports the HiveQL syntax, enabling access to already existing Hive warehouses.
- Spark Streaming
The fault-tolerance semantics of Spark is used out of the box by Spark streaming. It uses the Spark Core API to do real-time interactive data analytics. Such well-liked data sources as HDFS, Flume, Kafka, and Twitter may all be coupled with Spark streaming.
- MLlib (Machine Learning Library)
High-quality algorithms are delivered via the scalable machine learning library MLib, which is developed on top of Spark Core API.
MLib is simple to integrate into Hadoop workflows since it can be used with any Hadoop data, including HDFS, HBase, or local storage. When used with Spark applications, the library is usable in Java, Scala, and Python.
- GraphX
The Spark API for graph-parallel processing is called GraphX. Users can construct and alter graph-structured data interactively and at scale with GraphX.
Apache Spark Alternatives
-
Dask
Dask (2018) seeks to offer a robust parallel computing framework that is very user-friendly for Python programmers and can run on either a single laptop or a cluster. Incorporating Dask with existing hardware and programming is simpler and lighter than Spark.
Relevant reading: Dask vs. Spark
Because of its innovative API and execution model, Spark necessitates a certain amount of study and experience. In contrast, Pandas data frames and Numpy array data structures are supported by the pure Python framework Dask. Most data scientists can use it almost right away, which is a huge advantage.
Scikit-JobLib integration is also possible with Dask. With only a few modest code tweaks, Scikit-learn programs may be processed in parallel using Learn’s parallel computing module.
-
Ray
As a straightforward and all-purpose API for creating networked applications, the Ray framework was developed at RISELab, UC Berkeley. The following four libraries are included with the Ray core to speed up deep learning and machine learning operations.
- Tune (Scalable Hyperparameter Tuning),
- RLlib(Scalable Reinforcement Learning),
- Ray Train (Distributed Deep Learning)
- Datasets (Distributed Data Loading and Compute – beta phase).
Ray is utilized in important machine learning use cases like simulation, distributed training, sophisticated computations, and deployment in interactive settings while maintaining all of Hadoop and Spark advantageous traits.
Best Practices to Use Spark for Data Science
As data scientists, you often rely on the power of Apache Spark to run your computations. Here are some best practices for using Spark for data science:
- Have a good understanding of the Spark architecture. Data formats, including RDD, data frames, and datasets, as well as a clear concept of the role and duties of the driver, executors, and the nature of the task, are essential.
- Balance out the workload of all jobs and ensure a smooth distribution for parallel processing to prevent bottlenecks. Choose the correct number of cores, partitions, and tasks.
- As far as possible, avoid frequent shuffles, loading the disc, and excessive garbage collection. Load data onto discs only if a certain executor reports that the worker node on which it is running is out of memory.
- Debugging knowledge is essential because processing big amounts of data is typically difficult and can result in errors.
- Partition appropriately to optimize query planning. Partitioning must be done based on the columns used for filtering and sorting.
You can enroll in our Data Science certification course and our exclusive PG in Data Science course at your convenience, or you can book a demo with us.
Conclusion
Spark has a promising future because it outperforms other big data solutions now in use. Even in situations where MapReduce would generally perform better, Apache Spark can operate up to 100 times quicker. While some experts predict Spark will eventually displace Hadoop, others assert that the two complement one another’s strengths.
Spark for Data Science will be used more due to its adaptability, emphasis on Big Data insights, and backing from numerous businesses. Businesses will continue to leverage Apache Spark for its edge in speed, scalability, and machine learning advantages.
With its open-source roots, ever-growing library of supporting tools and services, and impressive performance gains over legacy systems like MapReduce or Hadoop, Spark quickly becomes a staple tool in the Data Science community.






1 Comment
Nice Blog, Thanks for Sharing