
The surge in data generation, fueled by IoT and digitization, has led to the challenge of handling massive datasets, commonly known as big data. Distributed stream processing engines have emerged to address this, enabling efficient real-time data processing through clustering.
There are various stream processing engines present today. The common ones include Flink, Kafka Streams, Spark, Samza, etc. SQL-like syntax is typically used to process streams for easy error handling and data manipulation. For example, KSQL is used by Kafka, whereas SparkSQL is used for Apache Spark.
Get detailed insight on Apache Spark: Spark for Data Science and Big Data Applications
This article will discuss the most prominent stream processing platforms, such as Apache Flink, Apache Spark, Apache Samza, etc. However, before you understand these platforms and how they differ, you must understand the stream processing engine.
What is a Stream Processing Engine?
Stream processing engines refer to run time engines and libraries that allow programmers to write relatively simple code to process data that come in as streams. These libraries and frameworks empower programmers to process data without delving into the intricacies of lower-level stream mechanics.
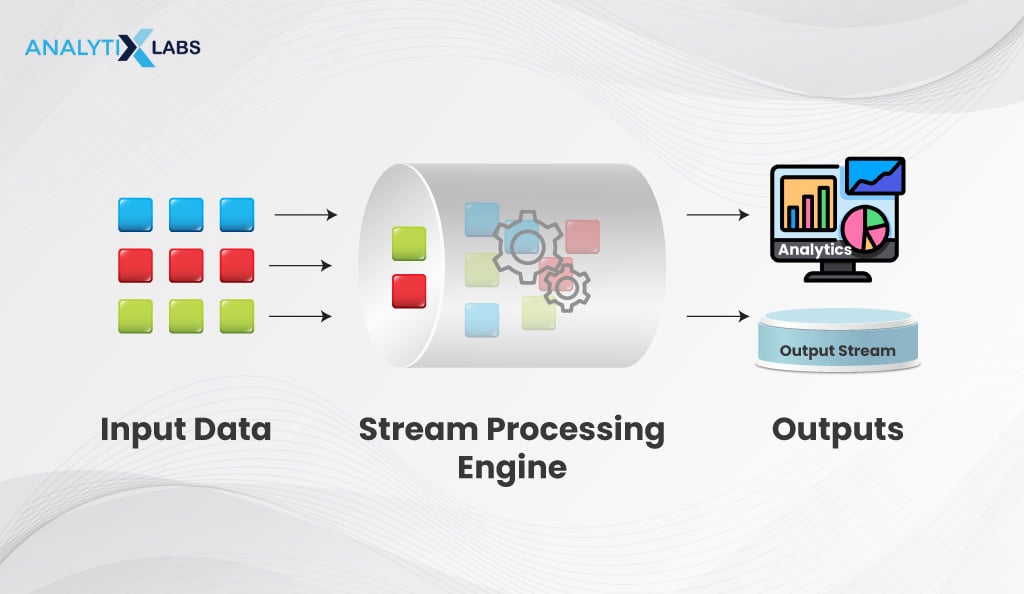
Few of these stream libraries have built-in algorithms that allow for complex types of processing, such as Apache Spark, which has MLLib enabling the use of machine learning algorithms.
-
Direct Acyclic Graph (DAG)
A Direct Acyclic Graph (DAG) is crucial for processing engines, where functions in these engines progress through DAG processes. This concept allows multiple functions to be linked in a specific order, ensuring the process never regresses to an earlier point. See the accompanying graph for a visual representation of DAG in action.

DAG usage gives rise to two processing engines: declarative and compositional. In a declarative engine, users channel functions, and the engine executes the DAG, handling data flow. A compositional engine requires users to explicitly define and pump data through the DAG.
Among the stream processing engines discussed here, Apache Spark and Flink are declarative with functional coding, while Apache Samza is compositional, involving lower-level coding for DAG design.
Through our comprehensive 360-degree learning courses, you can proficiently acquire expertise in various concepts, including but not limited to Flink, Kafka, Spark, programming, and various other essential domains. We have certification and PG courses.
Currently, we are offering courses as follows –
- Data Science 360 Certification Course
- Big Data Engineering
- PG in Data Science
- Business Analytics 360 certification course
- Data Visualization and Analytics
- PG in Data Analytics
Have some more questions? Book a free demo with us. Also, check out our exclusive enrollment offers.
Now that you understand the idea behind stream processing engines, let’s look at the two most popular tools in the world of processing engines- Flink and Kafka . We will first look at the major differences between the two.
Flink Vs. Kafka: Major Differences
Flink operates as a data processing framework utilizing a cluster model, whereas the Kafka Streams API functions as an embeddable library, negating the necessity to construct clusters.
The two major streaming platforms are Apache Flink and Kafka. Let’s understand Flink vs Kafka by exploring these frameworks.
-
Flink
Flink, originating from Berlin TU University, embraces the lambda architecture, functioning as a true streaming engine. It handles batch processing as a special case of streaming, particularly for bounded data.

Flink excels in auto-adjustment, minimizing the need for extensive parameter tuning and establishing itself as the first true streaming framework. Its advanced capabilities, including event time processing and watermarks, contribute to its widespread adoption in major companies like Uber and Alibaba.
-
Kafka
Kafka serves multiple purposes, from message passing to stream processing applications. It finds applications in stream processing, website activity tracking, metrics collection, log aggregation, real-time analytics, microservices, etc.

Kafka Streams, a lightweight library, is specifically designed for stream processing activities. The key comparison between Kafka and Flink centers around Kafka Streams vs Flink.
-
Industry Example
Exploring Kafka vs. Flink (i.e., Flink vs. Kafka Streams) reveals that although Kafka Streams integrates seamlessly with any application, its lightweight design limits its ability to handle heavy-weight tasks. Additionally, unlike Flink, Kafka doesn’t require a separate cluster to run, simplifying deployment and initiation of work.
Between the Apache Flink vs Kafka debate, heavy-duty stream processing tasks drive companies like Uber towards Flink. In contrast, companies such as Bouygues Telecom leverage Kafka for real-time analytics and event processing.
In the Flink vs. Kafka Stream comparison, Kafka Streams excels in interactive queries, leading the way due to Flink’s deprecation of this feature owing to low community demand. Flink offers an application mode for easy microservices building, yet Kafka Streams remains a favored choice for many.
-
Flink vs Kafka : Architecture
Another significant difference between Kafka vs. Flink is in terms of their architecture. The Flink architecture comprises the checkpointing system that stops the whole job at every local error and requires you to roll back to the last checkpoint. However, this functionality does provide consistent screenshots of the process.
Kafka, on the other hand, is devoid of this concept, as here, local errors can be recovered locally. Another difference is that Flink follows a checkpointing system that is fault-tolerant, and Kafka, on the other hand, uses a hot standby system for higher levels of availability.
While there are specific differences between these two technologies, and the discussion around Apache Flink vs Kafka can go on further, it is worth noting that companies are increasingly combining Flink and Kafka to build real-time stream processing applications.
Creating a Data Pipeline with Kafka and Flink
Interestingly, ING Bank is considered the first prominent organization to combine Kafka and Flink and think beyond Apache Flink vs Kafka. They use these platforms for fraud detection, and companies have increasingly been combining them.
Traditionally, data was processed at rest in databases, but Flink and Kafka now allow real-time data processing. While Kafka excels independently, its separate infrastructure from Flink complicates integration, requiring companies to manage two platforms.
However, companies can integrate these two leading open-source technologies to enable numerous stream processing use cases. These include mission-critical transaction workloads, global, hybrid, multi-cloud deployments, analytics embedded with machine learning, etc. Thus, if one looks for a Kafka Streams alternative, Flink is the best option.
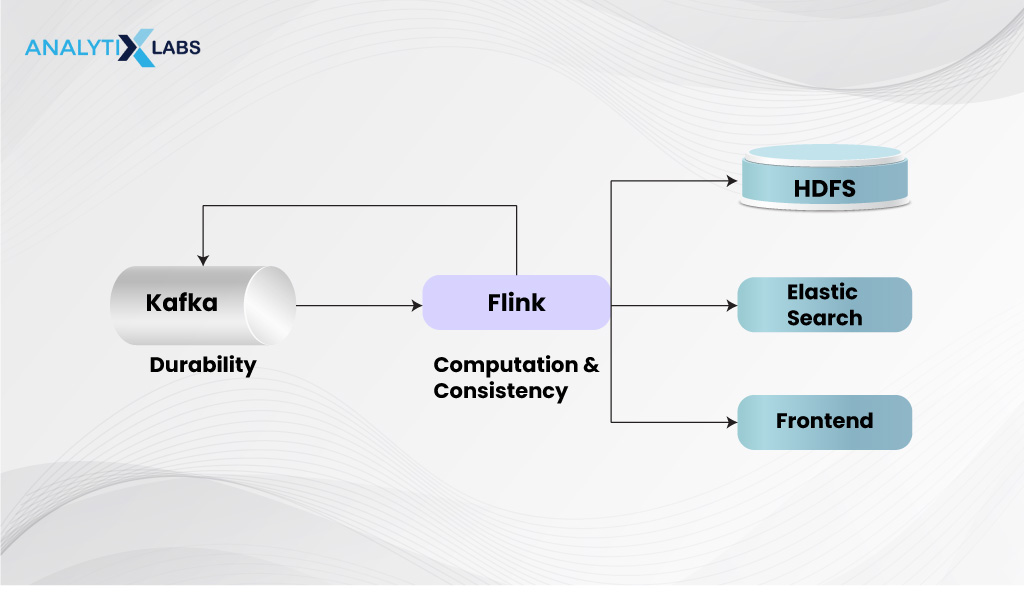
How can creating a data pipeline using both systems can be helpful?
The following steps can serve as a starting point, offering insights into the fundamental operations that both technologies can execute.
-
Overview
You start with understanding what these two technologies are all about. While some aspects are touched on, it’s worth noting that Flink operates as a real-time stream processing framework, whereas Kafka serves as a distributed stream processing framework.
-
Installation
The second step is to install and configure Kafka. The official Kafka website provides clear instructions on installing and configuring it. Once done, you need to create new topics – flink_input and flink_output. You can use the following commands to do so-

-
Flink Usage
The next step is to add Flink. There are multiple third-party systems that Flink allows to be used as stream sources or sinks. This includes-
1. Source
2. Sink
3. Source / Sink
You can include certain Maven dependencies, allowing you to consume and produce to and from Kafka projects. Refer to the code below-

-
Kafka String Consumer
Now, provide a Kafka address and a topic for Flink to consume data from Kafka. Additionally, ensure a group ID is specified to avoid reading data from the beginning each time.
You can use the code below that takes a kafkaGroup, kafkaAddress, and topic to create FlinkKafkaConsumer that consumes data from a given topic as a String (because to decode data, you provide SimpleStringSchema). Do note that the number 001 in the code refers to the version of Kafka that you are using, and you may have to change it based on the version you are currently running.

-
Kafka String Producer
The next step is to provide a Kafka address and topic so that data can be produced in Kafka. We create producers for the different topics by creating a static method again. Refer to the code below and note that this time, the method takes only two arguments- kafkaAddress and topic because group id is unnecessary when producing Kafka topics.

-
String Stream Processing
Once you have a fully functional consumer and producer, processing data from Kafka is the next step. The idea is also to save data back to Kafka. Several functions can be used for stream processing.
For example, if you intend to make the words in your data uppercase and write them back to Kafka, you must start creating a map function and then use it in stream processing. The application uses the flink_input topic to read data and the flink_output topic to save the results once the operations are performed.
Creating Map Function-

Using Function-

-
Custom Object Deserialization
First, you create a class representing a message with the senders’ and recipients’ information.

To deserialize data directly to custom objects, you must have a custom DeserializationSchema. Note that previously, you used to deserialize messages from Kafka using SimpleStringSchema.
Refer to the code below, where you start by assuming that the messages in Kafka are being held in JSON format. You, therefore, specify JavaTimeModule as you have a field of type LocalDateTime and want to make sure that proper mapping is done of the LocalDateTime objects to JSON.
Note that schemas in Flink are always serializable mainly because the operators (such as functions and schemas) are serialized at the beginning of the job (similar issues are also found in Spark).
Here, we fix this issue by initializing fields as static, as done with ObjectMapper below. Also, if a stream needs to be processed until specific data is reviewed, then isEndOfStream can be used; however, this is not the case in the example below.

-
Custom Object Serialization
Let’s take an example to understand custom object serialization. Imagine a system automatically backing up messages, creating a daily backup containing all the messages sent within that specific day. First, you create a class Backup to ensure each backup message gets assigned a unique ID. Once done, you must make your SerializationSchema save your backup object to Kafka as a JSON.
Creating Class-

Creating SerializationSchema-

-
Timestamping Messages
If you want to back up your messages, it’s important to timestamp them daily. Here, Flink comes in handy as it provides three characteristics, viz. IngestionTime, ProcessingTime, and EventTime, with the EventTime being of your use, as the idea here is to capture the time when the message is sent.
The code below uses a TimestampAssigner as we require it to use EventTime to extract time from the input data.
Flink expects the date time format to be in epoch seconds, so the code below transforms LocalDateTime to EpochSecond. Once the timestamps are assigned, all the time-related operations operate using the time sent from the sentAt field.
Another issue with Flink is that the format in which it expects time contains milliseconds, whereas the function toEpochSecond() returns time with only seconds, i.e., without milliseconds. This is why the time is multiplied by 1000, as by doing this, Flink can create windows properly.
The code also uses Watermark. This concept of Flink is helpful in situations where the order of the sent and received data is different.
Through Watermark, the user can define the acceptable lateness allowed for processing elements with timestamps below the Watermark being left unprocessed.

-
Creating Time Windows & Aggregating Backups
Only messages sent in a day must be captured for the backup. To ensure this is the case, the code below timeWindowAll method is used on the stream as the method splits messages into windows.
The AggregateFunction also aggregates the split messages from each window to be sent back to the Backup. Once all this is complete, begin processing your Kafka input.
Creating Time Windows-

Aggregating Backups-

The above data pipeline would have given you a sense of the power of Flink and Kafka. However, before discussing how different other platforms are from each other, let’s better understand Kafka, particularly Kafka Streams API.
What is the Kafka Streams API?
As briefly discussed when comparing Kafka and Flink, Kafka Streams is a component of Kafka. When comparing Kafka and Flink, many discussions surround Kafka Streams vs Flink.
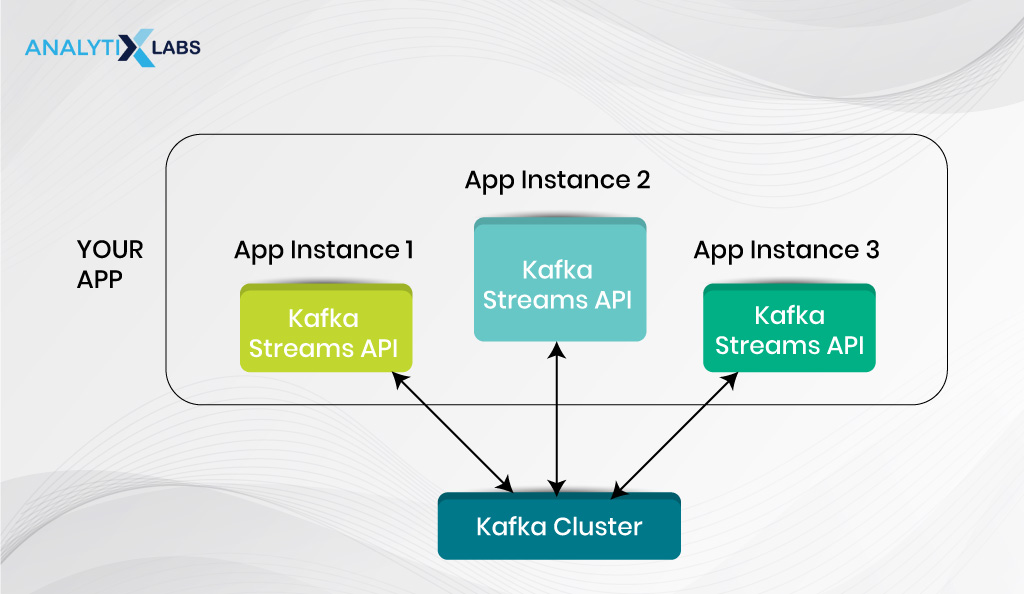
The Streams API of Kafka is a lightweight library available through Java. As hinted earlier, the specialty is that it enables distributed applications and microservices and is highly elastic, scalable, and fault tolerant.
Through the Kafka Stream, its users can create real-time applications. As you would have seen in the previous section, one can use Flink with Kafka; however, Kafka Stream API makes processing data stored in Kafka much easier.
Kafka Stream API follows all the crucial stream process concepts. These include being fast and efficient in performing aggregations and joins, efficient in the application state management, clearly distinguishing between processing and event time, and handling out-of-order data efficiently.
A great benefit of Kafka Streams is that the applications built using it behave like any other Java application, making their packaging, deployment, and monitoring easy for any Java developer. This allows the company not to waste resources preparing for a separate and special-purpose infrastructure.
However, with all its advantages, a great Kafka Streams alternative is Flink, which attracts many organizations. This is why we will discuss next where the two other major stream processing engines, Samza and Spark, stand against Flink.
Samza vs. Flink
Apache Samza is another popular real-time stream processing engine. It is relatively easy to understand the discussion around Samza vs Flink. It’s mainly because, at a higher level, Samza is similar to Kafka Streams.
As we have already discussed the difference between Kafka Streams and Flink, you can get a fair idea of what Samza is all about and how it differs from Flink. Both Kafka Streams and Samza can be easily and tightly integrated with Kafka.
However, Samza is a scaled-up version of Kafka Streams mainly because Kafka Streams is a library, whereas Samza is a proper cluster processing system.
While Kafka runs are primarily aimed at microservices, Samza runs on YARN. This makes the difference in Samza vs. Flink smaller than Kafka Streams and Flink.
Next, let’s also discuss how Spark is different from Flink.
Spark vs Flink
Spark vs Flink is a whole different debate. While Spark is a framework for cluster computing used to deal with large-scale data processing, Flink, as you would have known by now, is a framework for stream processing and quick data processing. While both frameworks are open source and deal with large datasets, there are several differences between Spark and Flink. These differences are slightly more pronounced than those of Kafka Streams and Samza.
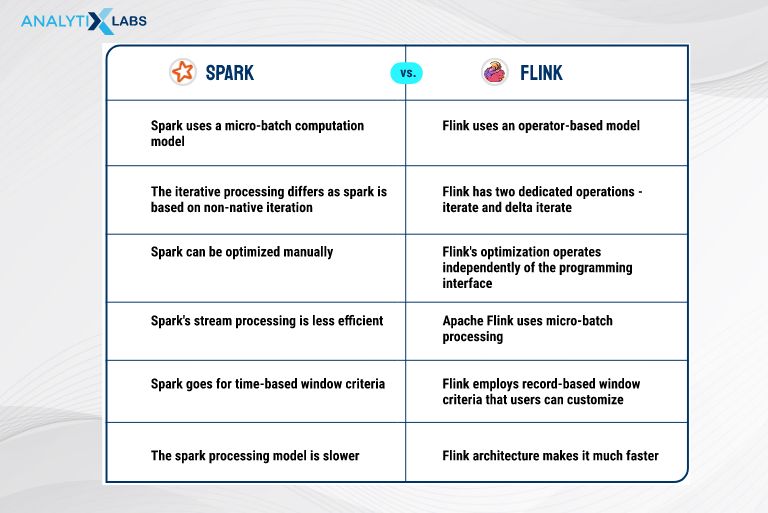
The main differences include the following-
- Spark uses a micro-batch computation model, while Flink uses an operator-based model.
- The iterative processing differs as Spark is based on non-native iteration, whereas Flink has two dedicated operations – Iterate and Delta Iterate.
- Manual optimization is possible for Spark, whereas Flink’s optimization operates independently of the programming interface.
- Spark’s stream processing is less efficient than Apache Flink, which uses micro-batch processing.
- Spark utilizes time-based window criteria, while Flink employs record-based window criteria that users can customize.
- The Spark processing model is slower, whereas Flink architecture makes it much faster.
Both frameworks are remarkable. However, a significant point of discussion in Spark vs Flink is that Spark’s community is much more mature, while Flink is much faster and better equipped for data streaming.
Conclusion
The landscape of big data tools is rapidly changing with daily advancements. An organization or individual today has many frameworks they can choose from, each having its advantage.
By and large, Flink is at the cutting edge of big data processing capabilities, with the most lethal combination being Kafka and Flink. You must watch out for these tools and see how they grow and revolutionize the big data space.
FAQs:
- Is Flink better than Kafka?
The main competition of Flink is not with Kafka as they can complement each other but with Kafka Streams. By and large, Flink is better than Kafka Streams mainly because it is much faster.
- Does Netflix use Flink?
Yes, Netflix uses Flink to index the federated GraphQL data, making the user experience more efficient and easy.
- What is Apache Flink good for?
Apache Flink is good for storing and streaming data as it can read and write from different streaming systems and storehouses. There is also the FlinkML library that allows for the machine learning algorithms to run on large datasets.
- Should I use Apache Flink?
Yes, it would be great if you used Flink. It is known as the most advanced tool currently available in big data.
We hope this article helped you widen your understanding of Flink and other critical big data frameworks. If you want to know more about the tools discussed in this article or want to learn big data, then write back to us.





